文章目录
- 一、RHCS集群的定义及相关概念
1.1 RHCS集群的定义
1.2 RHCS提供的三个核心功能
1.3 RHCS 集群组成
1.4 RHCS集群的特点- 二、通过fence设备解决集群节点之间争抢资源的现象
2.1 HA简介
2.2 集群脑裂
2.3 高可用集群中fence的搭建- 三、实现各集群节点之间服务迁移时客户端仍正常访问(高可用HA)
3.1 高可用服务配置(以httpd为例)
一、RHCS集群的定义及相关概念
1.1 RHCS集群的定义
- RHCS是red hat cluster suite的缩写,也就是红帽子集群套件,RHCS是一个能提供高可用性,高经济性,负载均衡,存储共享且经济廉价的集群工具集合,它将集群系统中的三大经济架构融为一体,可以给web应用,数据库应用等提供安全,稳定的运行环境。
- RHCS是一个功能完备的集群应用解决方案,它从应用的前端访问到数据后端的数据数据存储都提供了一个行之有效的集群架构实现,通过RHCS提供的这种解决方案,不但能保证前端应用持久,稳定的提供服务,同时也保证了后端数据存储的安全。
- RHCS提供了集群系统中三种集群架构,分别是高可用性集群,负载均衡集群,存储集群。
1.2 RHCS提供的三个核心功能
(1)高可用集群
高可用集群是RHCS的核心功能
当应用程序出现故障的时候,或者系统硬件,网络出现故障时,应用可以通过RHCS提供的高可用管理组件自动,快速从一个节点切换到另一个节点,节点故障转移功能对客户端来说是透明的,从而保证保证应用持续,不间断的对外提供服务,这就是RHCS高可用集群实现的功能。
(2)负载均衡集群
RHCS通过LVS(Linux Virtual Server)来提供负载均衡,而LVS是一个开源的,功能强大的基于IP的负载均衡技术
LVS由由负载调度器和访问节点组成,通过LVS的负载调度功能,可以将客户端的请求平均的分配到各个服务节点上,同时还可以定义多种负载分配策略,当一个请求近来时,集群系统根据调度算法来判断应该将请求分配到哪个服务节点,然后,由分配到的节点响应客户端需求。
LVS也提供了故障转移功能,就是指当某个服务节点不能提供服务时,LVS会自动屏蔽这个故障节点,接着将失败节点从集群中剔除,同时将新来次节点的请求平滑的转移到其它正常的节点上来;而当此故障节点恢复正常后,LVS又会自动将此节点加入到集群中去,而这一系列的切换动作,对于用户来说是透明的,通过故障转移功能,保证了服务的不间断,稳定的运行。
(3)存储集群
RHCS通过GFS文件系统来提供存储集群功能,GFS是Global File System的缩写,它允许多个服务同时去读写一个单一的共享文件系统,存储集群通过将共享的数据放到一个共享文件系统中从而消除了在应用程序间同步数据的麻烦,GFS是一个分布式文件系统,它通过锁管理机制,来协调和管理多个服务节点对同一个文件系统的读写操作。
1.3 RHCS 集群组成
RHCS是一个集群工具的集合,主要由以下几大部分组成:
(1)集群架构管理器
这是RHCS集群的一个基础套件,提供一个集合的基本功能,使各个节点组成集群在一起工作,具体包含分布式集群管理器(CMAN),成员关系管理,锁管理(DLM),配置文件管理(CCS),栅设备(FENCE)。
(2)高可用服务管理器
提供节点服务监控和服务故障转移功能,当一个节点服务出现故障时,将服务转移到一个健康节点。
(3)集群配置管理工具
RHCS最新版本利用LVS来配置和管理rhcs集群,LUCI是一个基于web的集群配置方式,通过luci可以轻松的搭建一个功能强大的集群系统。
在红帽系统中我们通过luci和ricci来配置管理集群,其中luci安装在一台独立的计算机上或者节点上,luci只是用来通过web访问来快速的配置管理集群的,它的存在与否并不影响集群。ricci是安装在每个节点上,它是luci与集群给节点通信的桥梁。
(5)Linux Virtual Server
LVS是一个开源的负载均衡软件,利用LVS可以将客户端的请求根据指定的负载均衡策略和算法合理的分配到各个服务节点,实现动态、智能的负载均衡的分担。
RHCS除了上面的几个核心构成,还可以通过下面的一些组件来补充RHCS集群功能:
(1)Red Hat GFS(Global File System)
GFS是redhat公司开发的一款集群文件系统,目前最新的版本是GFS2,GFS文件系统允许多个服务同时读写一些磁盘分区,通过GFS可以实现数据的集中管理,免去了数据同步和拷贝的麻烦,但GFS并不能孤立的存在,安装GFS需要RHCS的底层组建支持。
(2)Cluster Logical Volume Manger
cluster逻辑卷管理器,即CLM,是LVM的扩展,这种扩展允许cluster中的机器使用lvm来管理共享存储。
(3) ISCSI
iscsi是一种在internet协议上,特别是以太网上进行数据块传输的标准,它是一种基于IP Storage理论的新型存储技术,RHCS可以通过ISCSI技术来导出和分配共享存储的使用。
(4) Global Network Block Deceive
全局网络模块,简称GNBD,是GFS的一个补充组件,用于RHCS分配和管理共享存储,GNBD分为客户端和服务端,在服务端GNBD允许导出多个块设备或者GNBD文件,而GNBD客户端通过导入这些导出的文件或者块设备,就可以把它们当作本地块设备使用。由于现在GNBD已经停止了开发,所以使用GNBD的越来越少。
1.4 RHCS集群的特点
(1)最多支持128个节点(红帽企业Linux 3 和红帽企业Linux 4 支持 16 个节点)。
(2)可同时为多个应用提供高可用性。
(3)NFS/CIFS 故障切换:支持 Unix 和 Windows 环境下使用的高可用性文件。
(4)完全共享的存储子系统:所有集群成员都可以访问同一个存储子系统。
(5)综合数据完整性:使用最新的 I/O 屏障(barrier)技术,如可编程的嵌入式和外部电源开关装置(power switches)。
(6)服务故障切换:红帽集群套件可以确保及时发现硬件停止运行或故障的发生并自动恢复系统,同时,它还可以通过监控应用来确保应用的正确运行并在其发生故障时进行自动重启。
二、HA (High Available)高可用集群—通过fence设备解决集群节点之间争抢资源的现象
2.1 HA简介
HA(High Available),高可用集群,是减少服务中断时间为目的的服务器集群技术。是保证业务连续性的有效解决方案。集群,简单的来说就是一组计算机。一般有两个或者两个以上的计算机组成,这些组成集群的计算机被称为节点。
其中由两个节点组成的集群被称为双机热备,即使用两台服务器互相备份,当其中一台服务器出现问题时,另一台服务器马上接管服务,来保护用户的业务程序对外不间断提供的服务,当然集群系统更可以支持两个以上的节点,提供比双机热备更多、更高级的功能,把因软件/硬件/人为造成的故障对业务的影响降低到最小程度。
2.2 集群脑裂
1、什么是脑裂
脑裂(split-brain)就是“大脑分裂”,也就是本来一个“大脑”被拆分了两个或多个“大脑”,我们都知道,如果一个人有多个大脑,并且相互独立的话,那么会导致人体“手舞足蹈”,“不听使唤”。
脑裂通常会出现在集群环境中,集群环境有一个统一的特点,就是它们有一个大脑,即集群中的Master/Leader节点,
2、集群中的脑裂场景
对于一个集群,想要提高这个集群的可用性,通常会采用多机房部署,比如现在有一个由6台Server所组成的一个集群,部署在了两个机房:
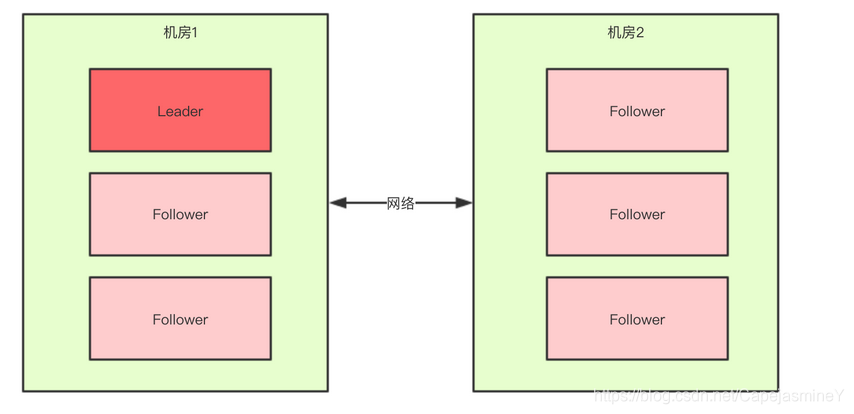
正常情况下,此集群只会有一个Leader,那么如果机房之间的网络断了之后,两个机房内的Server还是可以相互通信的,如果不考虑过半机制,那么就会出现每个机房内部都将选出一个Leader。

这就相当于原本一个集群,被分成了两个集群,出现了两个“大脑”,这就是脑裂。
对于这种情况,我们也可以看出来,原本应该是统一的一个集群对外提供服务的,现在变成了两个集群同时对外提供服务,争抢资源。还会出现一种问题:如果过了一会,断了的网络突然联通了,那么此时就会出现问题了,两个集群刚刚都对外提供服务了,数据该怎么合并,数据冲突怎么解决等等问题。
3、解决方法
在集群中为了防止服务器出现“脑裂”的现象,集群中一般会添加Fence设备,有的是使用服务器本身的的硬件接口称为内部Fence,有的则是外部电源设备称为外部Fence,当一台服务出现问题响应超时的时候,Fence设备会对服务器直接发出硬件管理指令,将服务器重启或关机,并向其他节点发出信号接管服务。
在红帽系统中我们通过luci和ricci来配置管理集群,其中luci安装在一台独立的计算机上或者节点上,luci只是用来通过web访问来快速的配置管理集群的,它的存在与否并不影响集群。ricci是安装在每个节点上,它是luci与集群中节点通信的桥梁。
2.3高可用集群中fence的搭建
实验环境:
一台主机和两台虚拟机
| 主机ip | 172.25.1.250 |
|---|---|
| 虚拟机server1(6.5版本) | 172.25.1.101 |
| 虚拟机server2(6.5版本) | 172.25.1.102 |
实验:
虚拟机server1作为管理节点和HA节点
虚拟机server2作为HA节点
虚拟机server1上:
步骤一:关闭firewalld和selinux
service iptables stop #关闭防火墙
chkconfig iptables off #永久关闭防火墙
service iptables status #查看防火墙状态


步骤二:添加本地解析

步骤三:配置高可用yum源
[HighAvailability]
name=HighAvailability
baseurl=http://172.25.1.250/rhel6.5/HighAvailability #使用真机共享的6.5版本镜像中中的高可用包
gpgcheck=0
[LoadBalancer]
name=LoadBalancer
baseurl=http://172.25.1.250/rhel6.5/LoadBalancer
gpgcheck=0
[ResilientStorage]
name=ResilientStorage
baseurl=http://172.25.1.250/rhel6.5/ResilientStorage
gpgcheck=0
[ScalableFileSystem]
name=ScalableFileSystem
baseurl=http://172.25.1.250/rhel6.5/ScalableFileSystem
gpgcheck=0

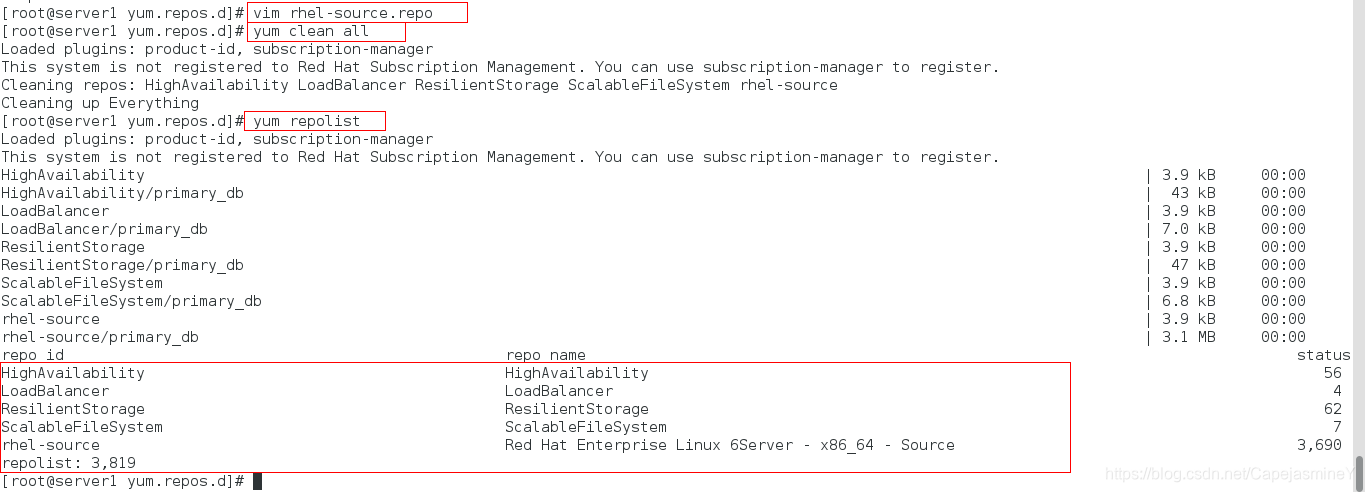
步骤四:安装ricci和luci
luci是web界面的管理工具
yum install -y ricci luci

步骤五:安装完后会产生ricci用户,给ricci用户设置密码
passwd ricci

步骤六:开启ricci,luci并设置开机启动
/etc/init.d/ricci start
/etc/init.d/luci start
chkconfig ricci on
chkconfig luci on
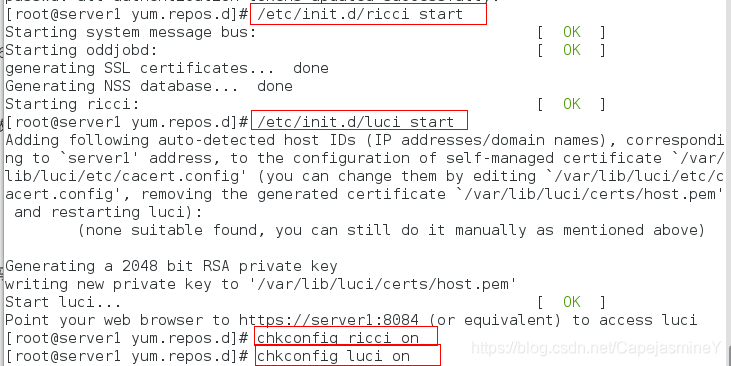
步骤七:查看两个服务开启的端口: 8084和11111
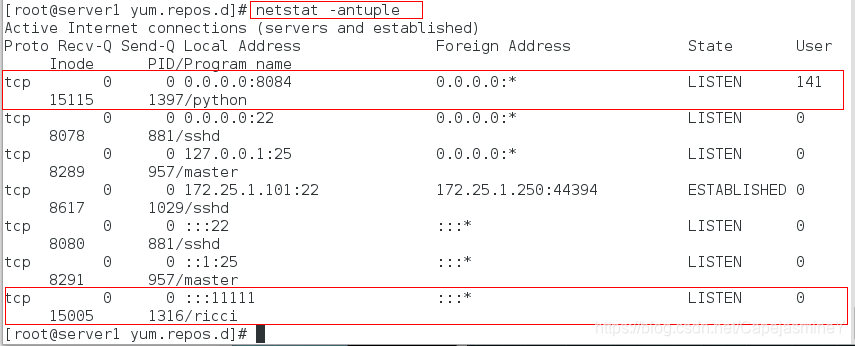
虚拟机server2上:
步骤一:关闭firewalld和selinux
service iptables stop #关闭防火墙
chkconfig iptables off #永久关闭防火墙
service iptables status #查看防火墙状态


步骤二:添加本地解析
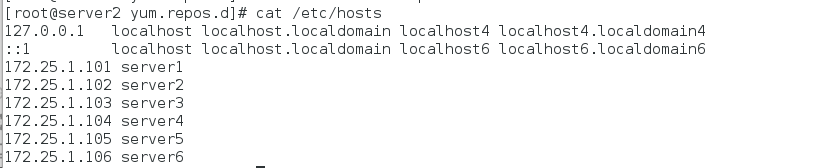
步骤三:配置高可用yum源
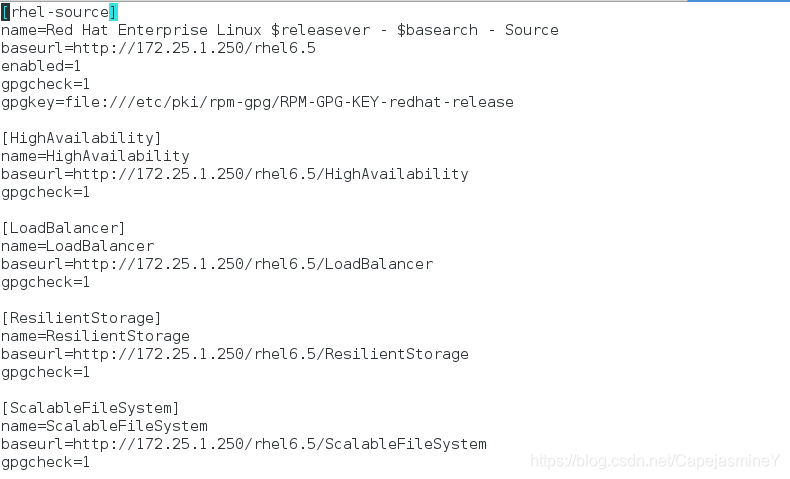
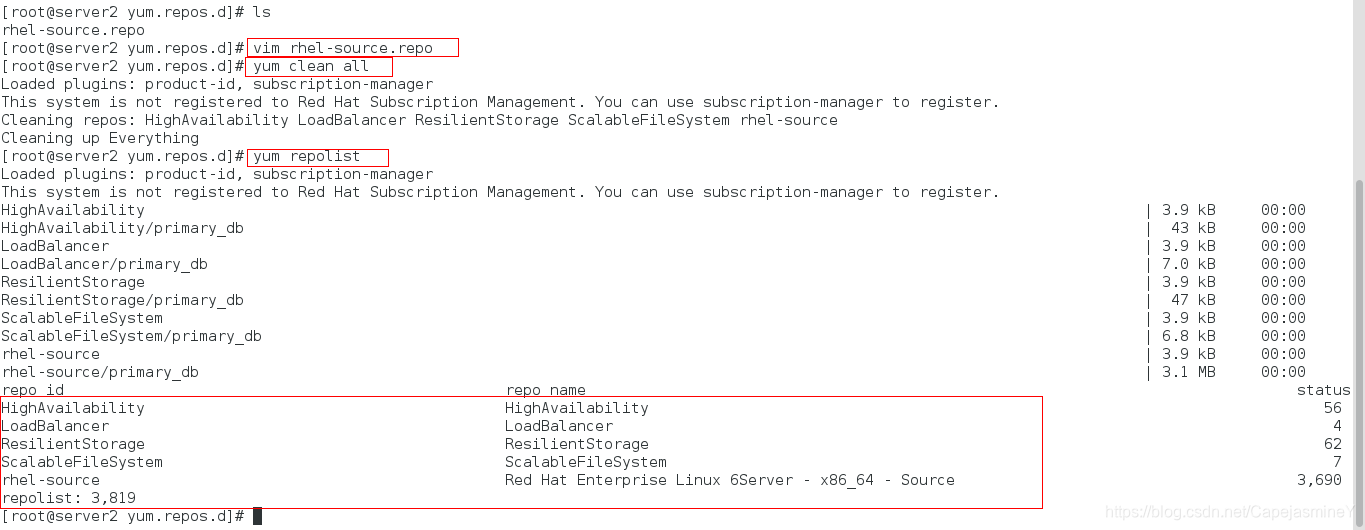
步骤四:安装ricci
yum install -y ricci
步骤五:安装完后会产生ricci用户,给ricci用户设置密码
passwd ricci

步骤六:开启ricci,luci并设置开机启动
/etc/init.d/ricci start
chkconfig ricci on

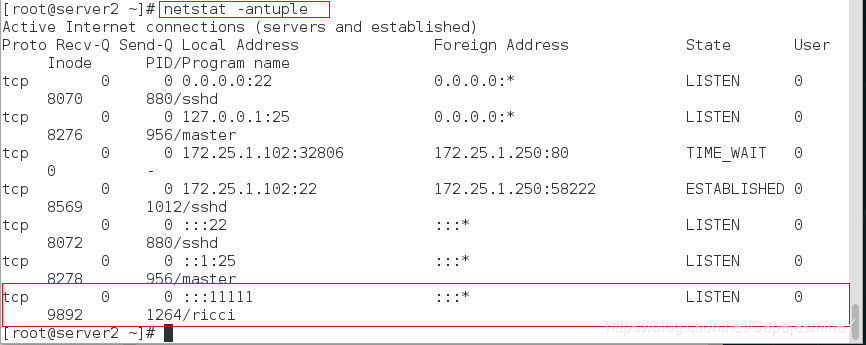
步骤七:查看服务开启的端口: 11111
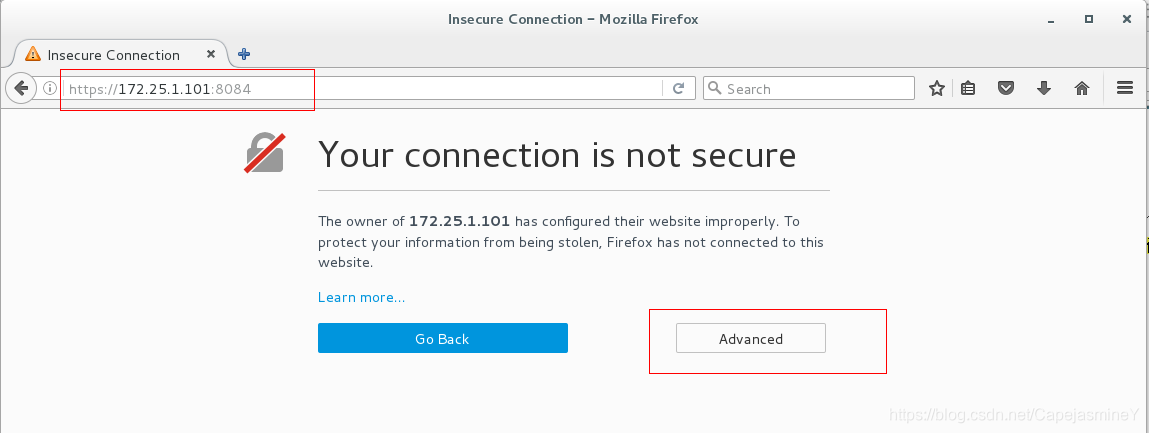
服务配置完成后在真机打开web界面配置:
使用firefox登陆 https://172.25.1.101:8084
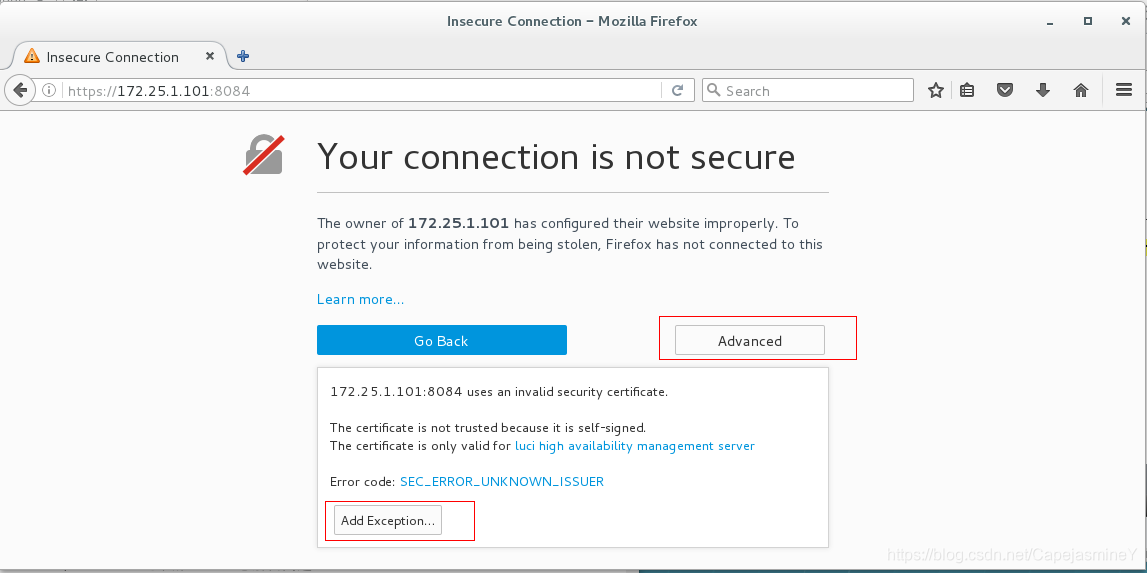
- 浏览器访问https://172.25.12.1:8084 出现下面的界面,手动导入证书,点击【Advanced】
- 注意:删除集群时要先删除节点,节点删除后集群会自动消失
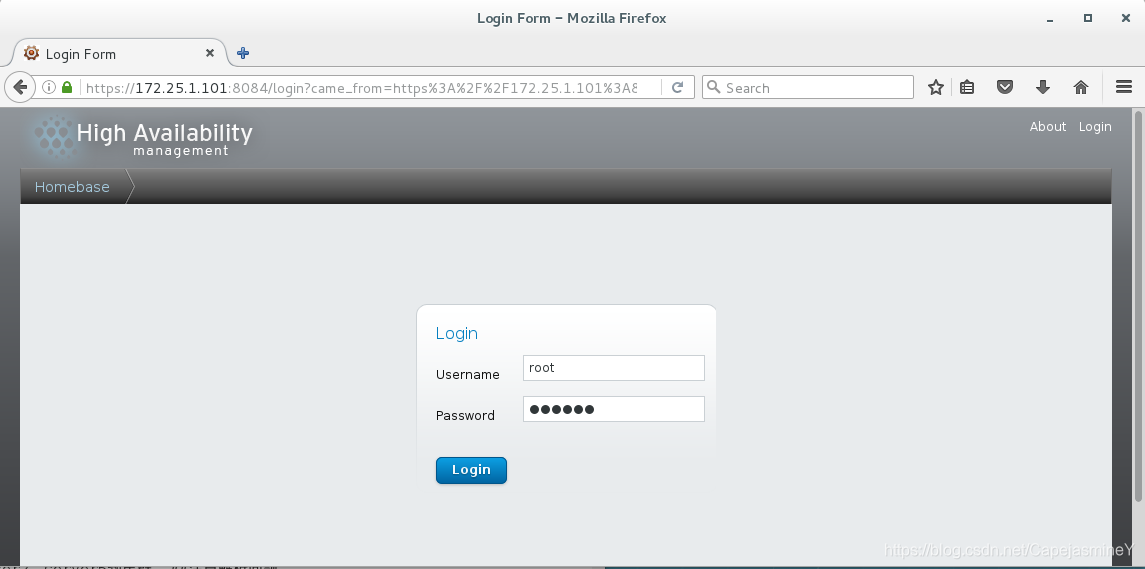
认证完成后出现如下界面,输入用户名称密码:
添加server1和server2到集群:
点击集群管理(manage cluster),选择create,创建集群
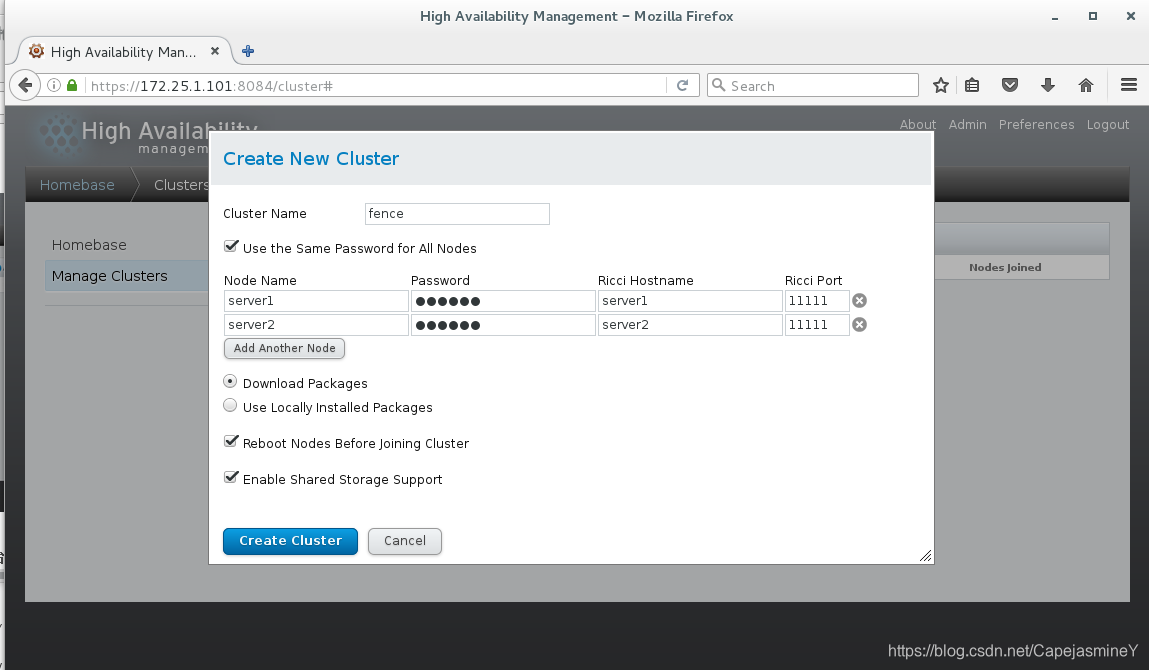
点击create cluster开始创建,可以看到开始创建集群:

结点添加完此:
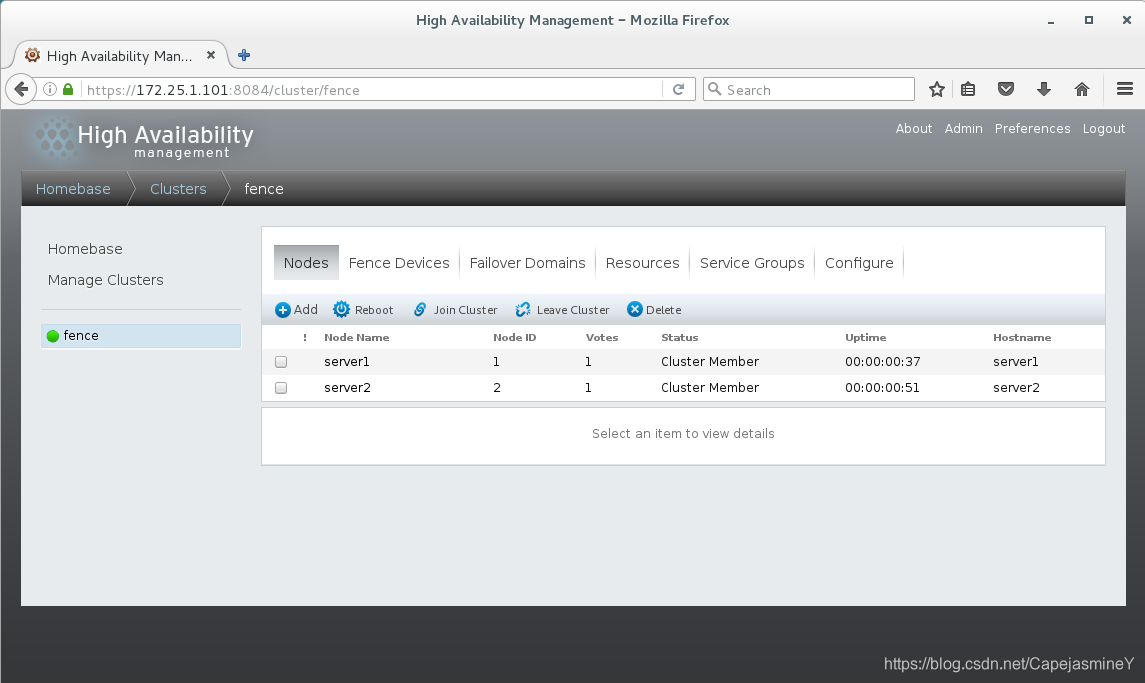
点击查看结点信息:
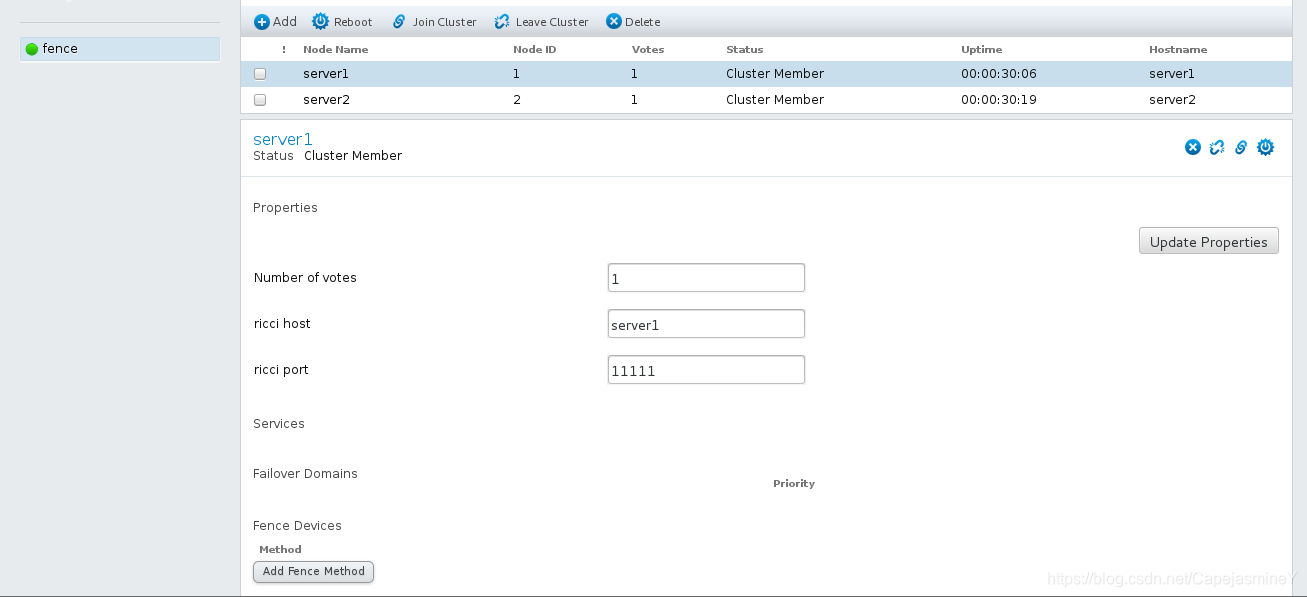
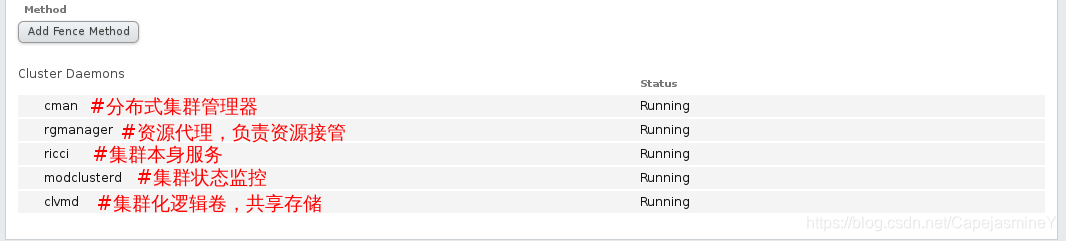
创建时两台虚拟机都会重启,如果之前没有设置服务开机启动这个时候就会报错,重启后要在虚拟机中手动打开服务创建的过程才会继续
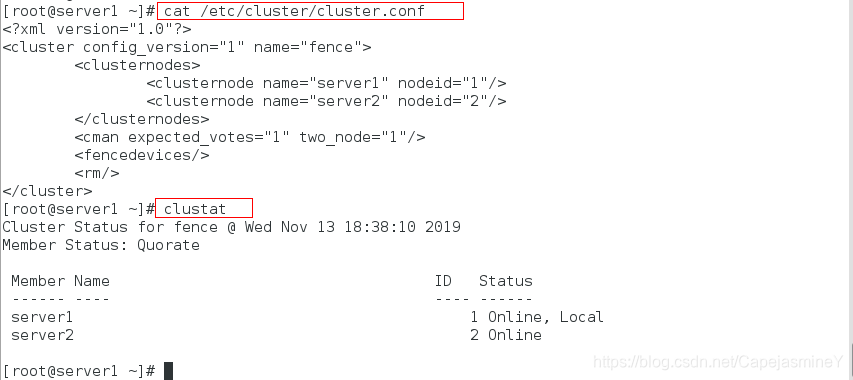
在虚拟机server1上查看结点是否添加成功:
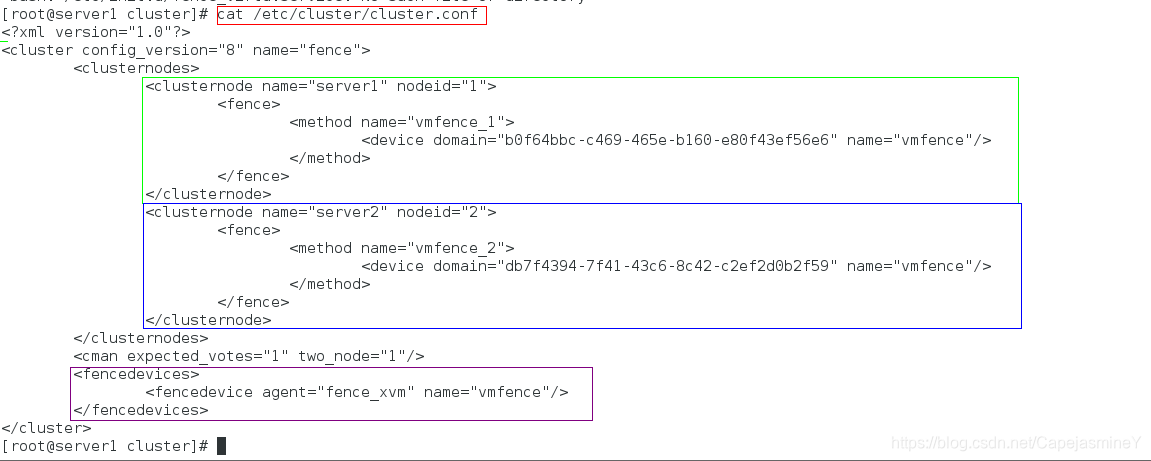
cat /etc/cluster/cluster.conf #查看集群配置文件
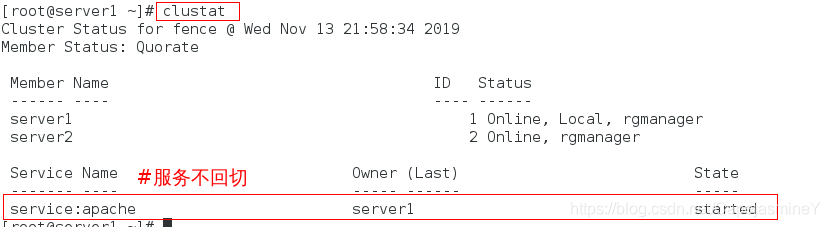
clustat #查看集群状态
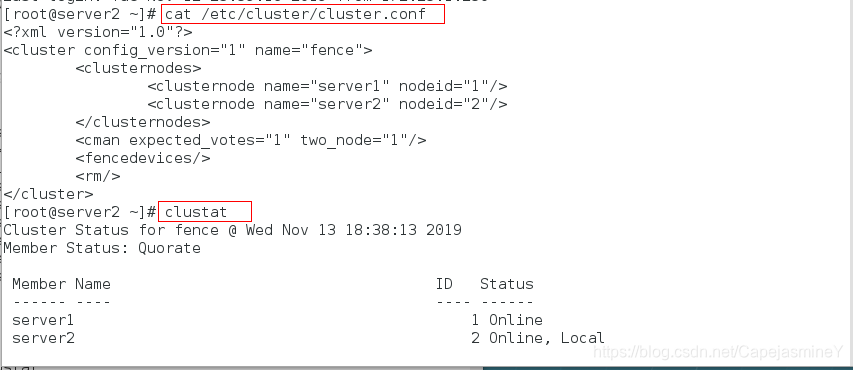
 在虚拟机server2上查看结点是否添加成功:
在虚拟机server2上查看结点是否添加成功:
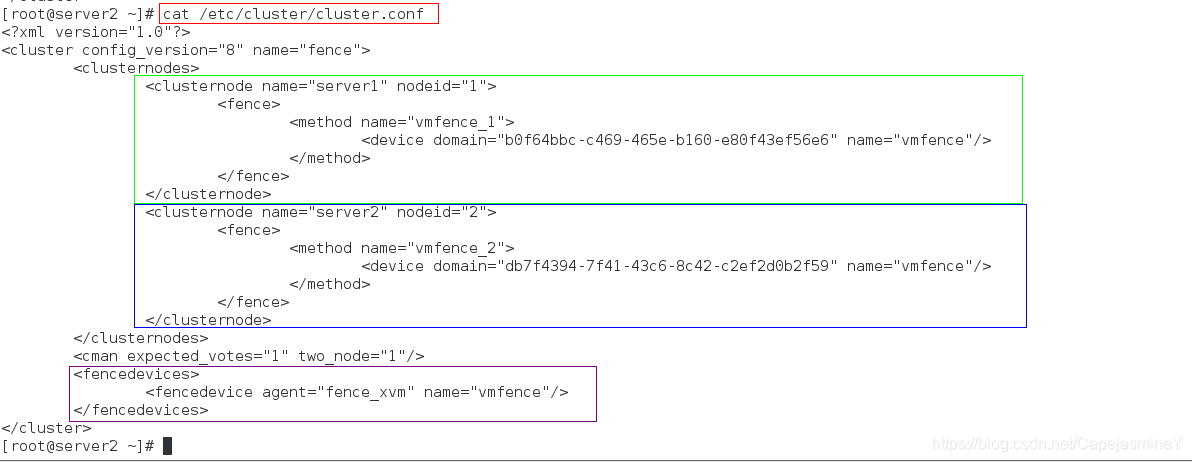
cat /etc/cluster/cluster.conf #查看集群配置文件
clustat #查看集群状态
添加fence,解决争抢资源的现象
本实验用到两台调度器为用户提供服务。简单讲一下工作原理:
如何通过fence设备解决集群节点之间争抢资源的现象?
RHCS高可用集群比之前的lvs调度器性能更好,更全面,有更多功能,前端后端均有,在这里我们可以把每个集群节点当作一个调度器,实际上功能不止调度器一个。一般情况下集群节点中有主有备,正常情况下会有一个对外提供服务(调度器正常),但是当调度器坏了就完蛋了。
因此要做到一台调度器坏了,调度器1就去通知调度器2接管它的工作,正常情况下调度器1和调度器2会一直通信,当2收不到1的消息的时候,就说明1坏了,2马上接替1的工作。但是当1和2之间的心跳检测出现问题的时候,也就是有一个卡死了,彼此检测不到对方心跳,认为对方挂掉了,1和2都开始对外提供服务,会去争抢资源,因此需要fence这样一个物理设备抑制争抢资源。
FENCE的工作原理是:当意外原因导致主机异常或者宕机时,备机会首先调用FENCE设备,然后通过FENCE设备将异常主机重启或者从网络隔离,当FENCE操作成功执行后,返回信息给备机,备机在接到FENCE成功的信息后,开始接管主机的服务和资源。这样通过FENCE设备,将异常节点占据的资源进行了释放,保证了资源和服务始终运行在一个节点上。
在真机上 配置fence:
步骤一:配置真机的yum源,将虚拟机的高可用yum源的配置文件发给真机

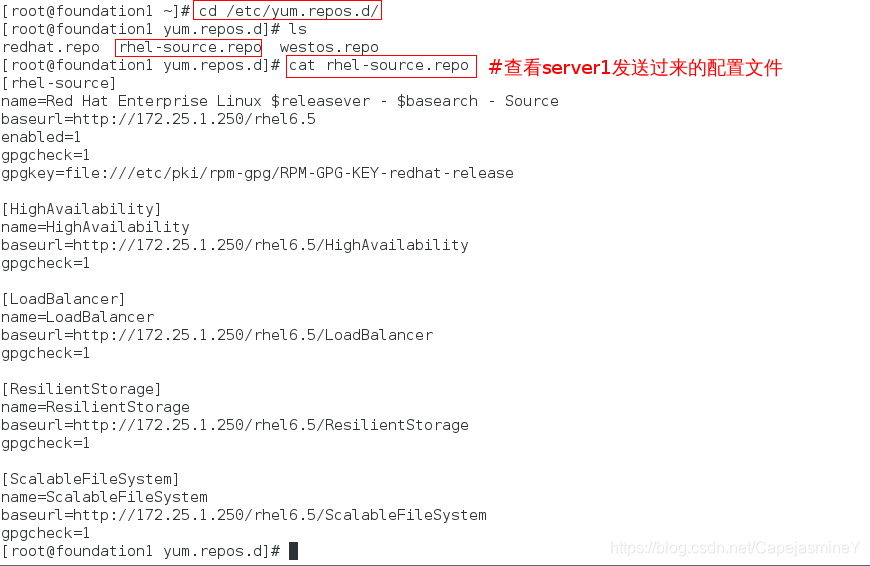
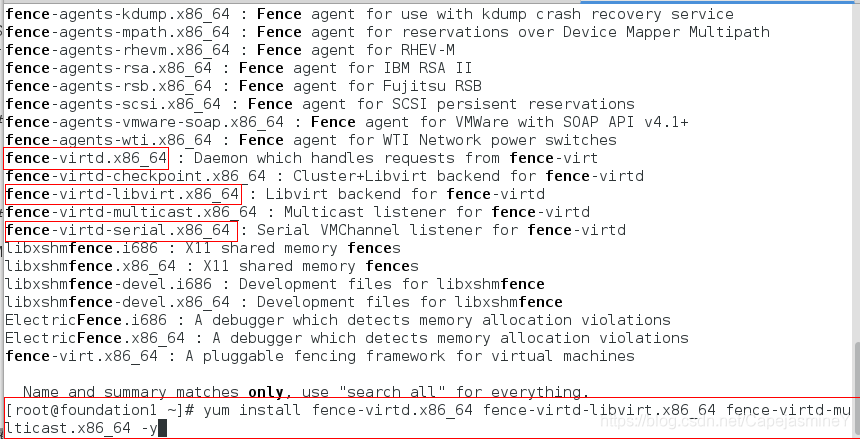
步骤二:安装fence软件包
yum search fence
yum install fence-virtd.x86_64 fence-virtd-libvirt.x86_64 fence-virtd-multicast.x86_64 -y

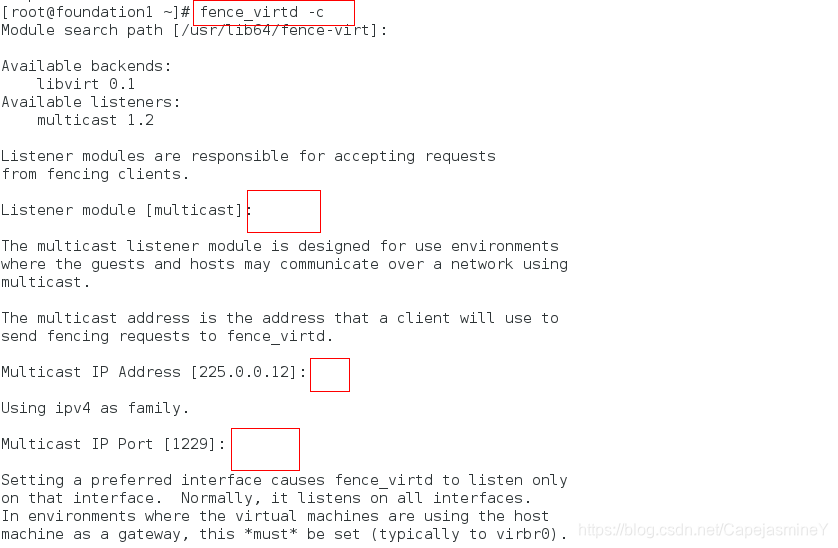
步骤三:初始化fence设备管理
一直回车,注意网卡是br0(因为两个集群是在虚拟机上面做的,虚拟网卡是通过真实的网卡br0来工作)
fence_virtd -c
Interface [virbr0]: br0 ##设备选择br0,其他用默认
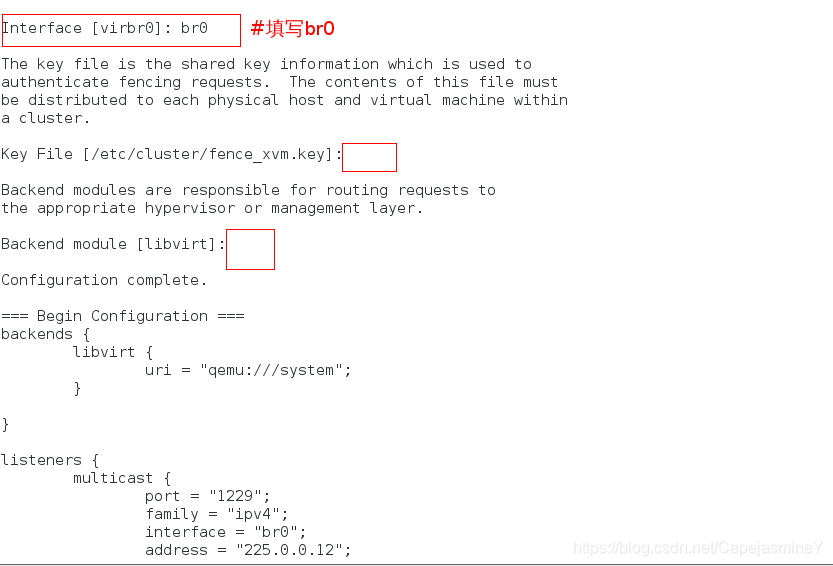

步骤四:生成fence_xvm.key,把fence_xvm.key分发到HA节点,通过这个key来管理节点
注意发送key的时候fence不能开启,否则server1和server2接收到的key不一样
mkdir /etc/cluster 在这个目录下生成fence管理的key,然后传给集群
生成fence管理的key:
dd if=/dev/urandom of=/etc/cluster/fence_xvm.key bs=128 count=1
scp fence_xvm.key root@server2:/etc/cluster/
scp fence_xvm.key root@server5:/etc/cluster/


步骤五:web界面使用luci配置fence设备
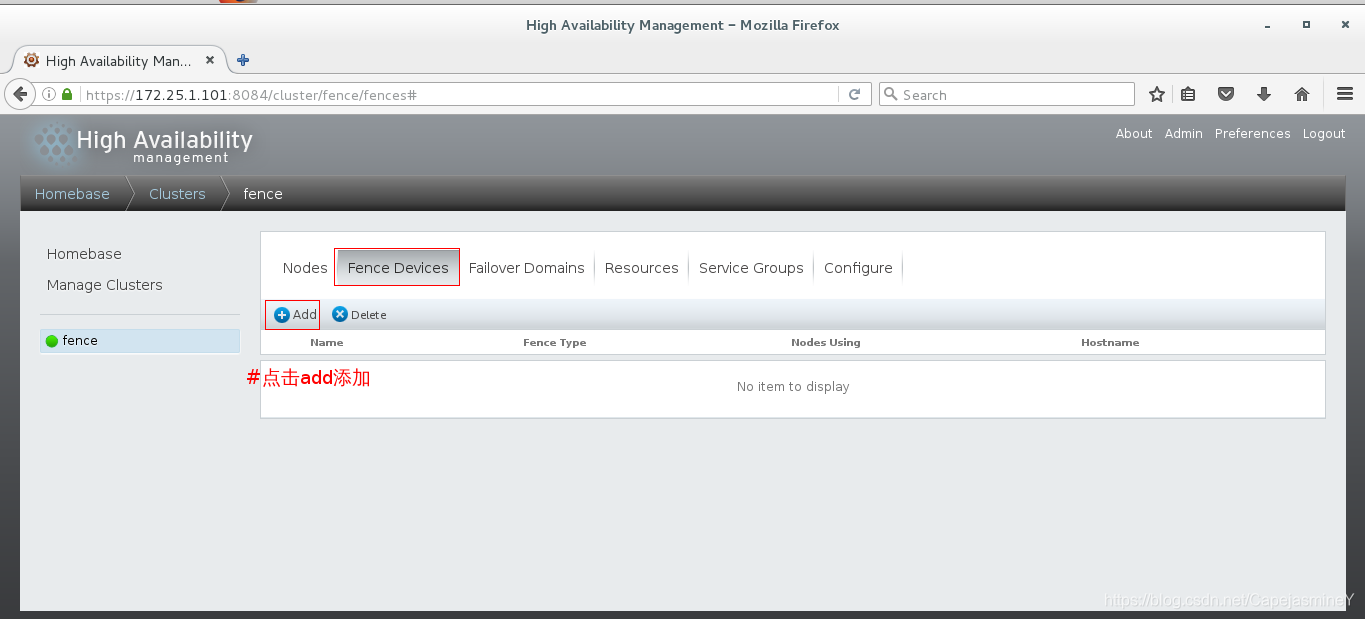
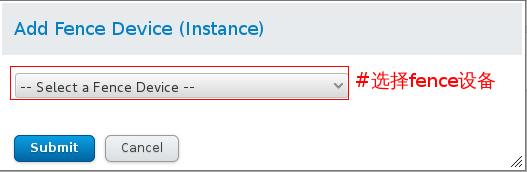
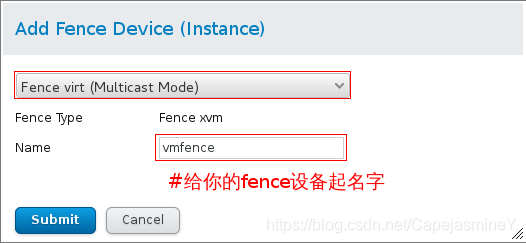
fence设备添加成功:

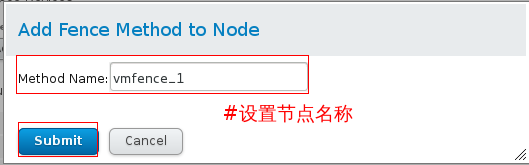
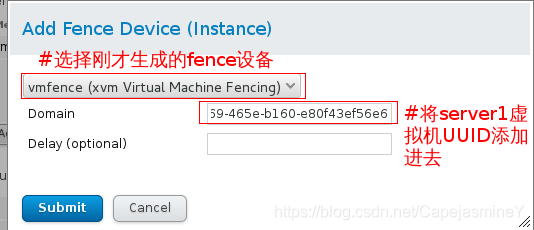
步骤六:web界面为server1节点配置fence
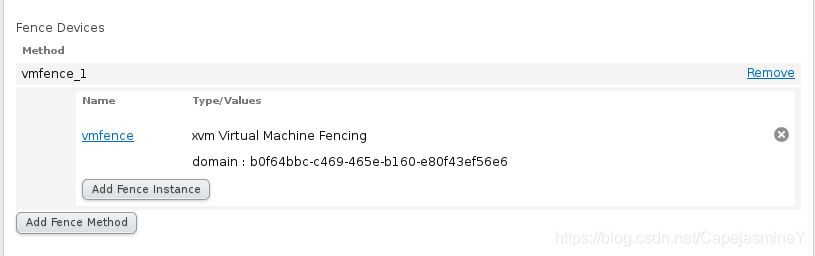
给server1和server2集群添加fence,vmfence_1(名字) uuid(server1主机的),vmfence_2(名字) uuid(server2主机的)
因为两个集群的ip可能会一样,有可能会一次关闭两个集群,不安全
应该把每个集群唯一的uuid写在fence设备上面
在真机里面virt-manager把两个uuid查看出来

 在虚拟控制器中查看server1的UUID:
在虚拟控制器中查看server1的UUID:
 添加到节点中:
添加到节点中:
添加成功:
步骤七:web界面为server2节点配置fence


 在虚拟控制器中查看server2的UUID:
在虚拟控制器中查看server2的UUID:
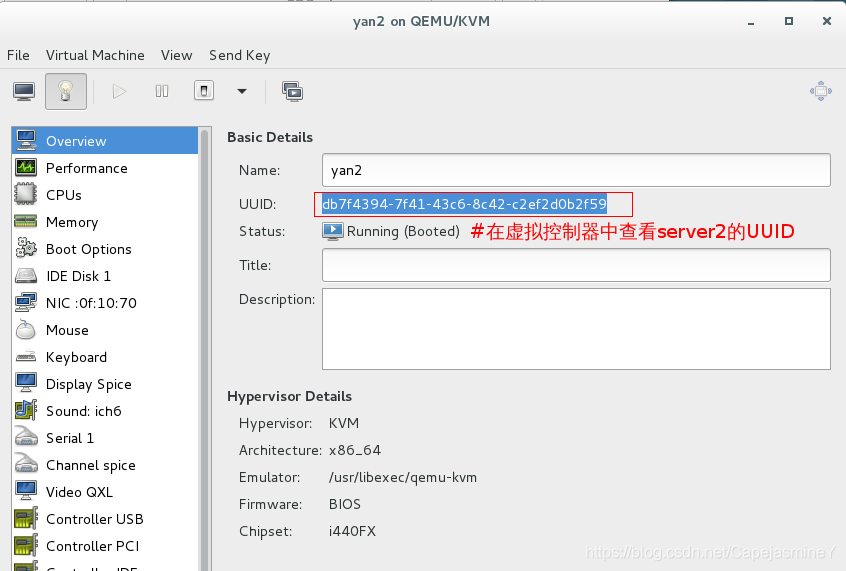
给server2添加fence设备,将UUID填入:
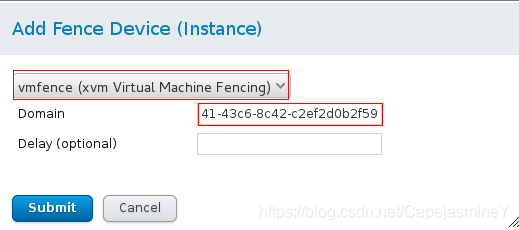 添加成功:
添加成功:
 在server1虚拟机上查看节点信息:
在server1虚拟机上查看节点信息:
 在server2虚拟机上查看节点信息:
在server2虚拟机上查看节点信息:
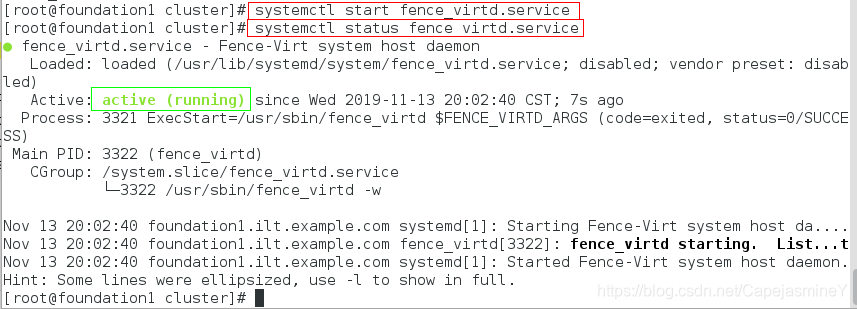
 步骤七:开启fence设备,查看端口
步骤七:开启fence设备,查看端口
systemctl start fence_virtd.service
systemctl status fence_virtd.service #查看fence服务是否开启
netstat -antulp | grep 1229 #fence服务使用的端口
 步骤八:测试
步骤八:测试
在server1虚拟机上:
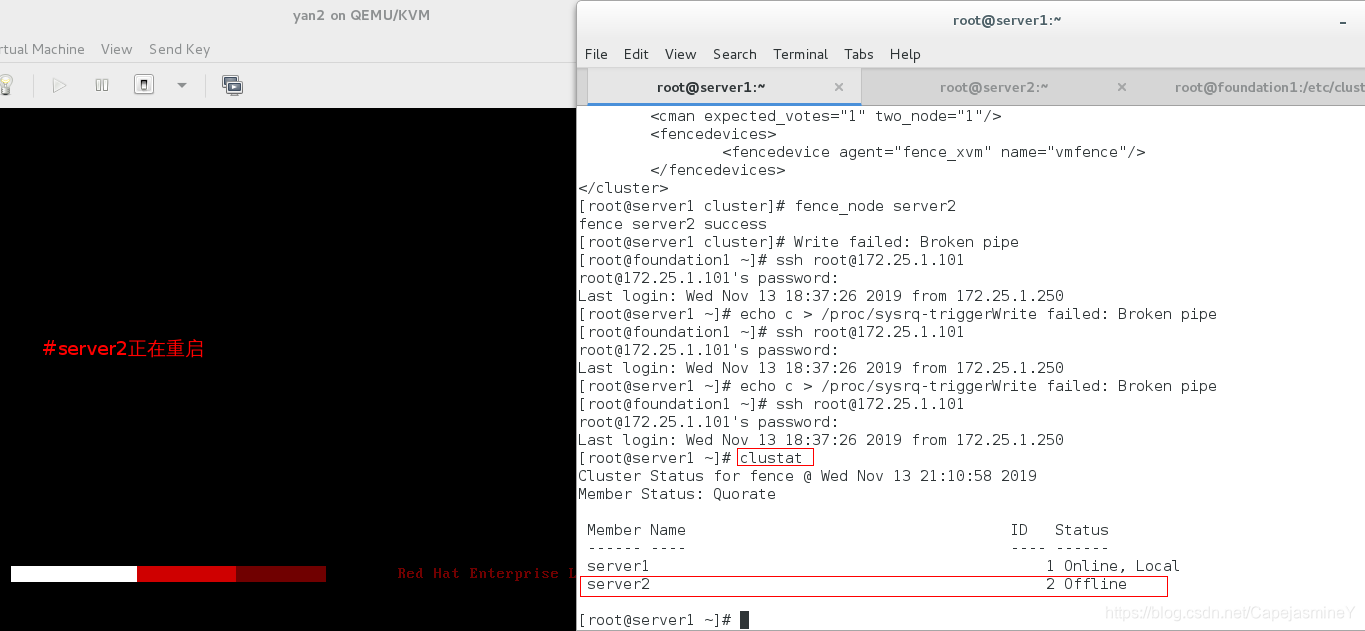
fence_node server2 #在server1上使用这条命令,server1通过fence干掉server2,可以看到server2断电重启

在server2虚拟机上:
fence_node server1#在server1上使用这条命令,server1通过fence干掉server2,可以看到server2断电重启


模拟server1主机故障:
破坏server1的内核,输入:echo c > /proc/sysrq-trigger,fence会强制重启server1
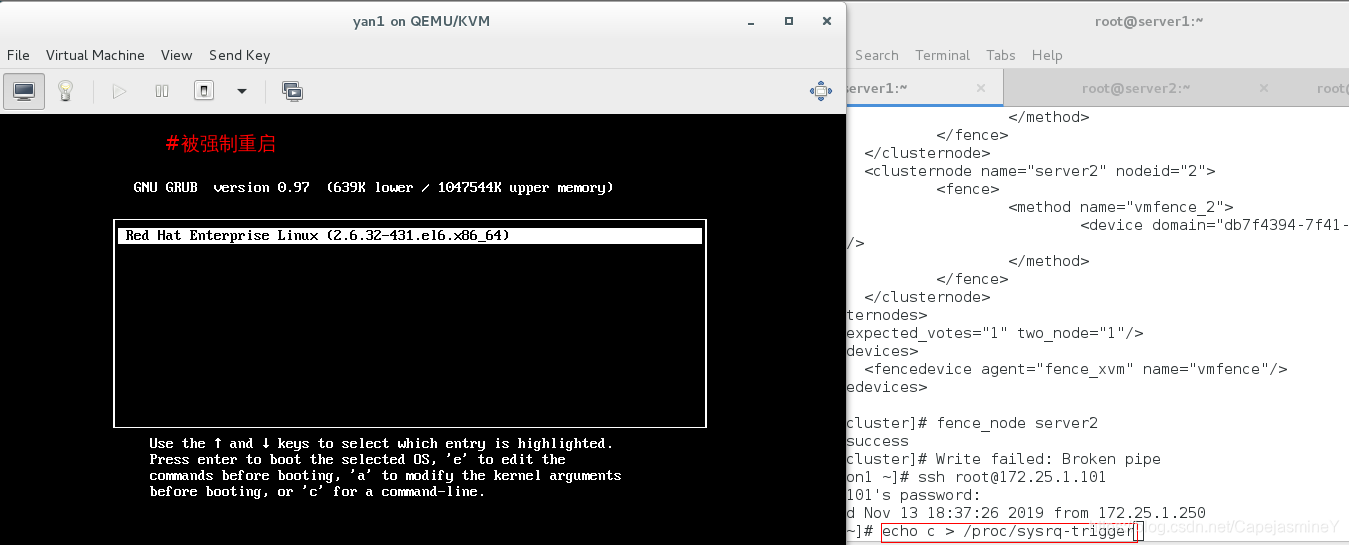
此时在server2上查看集群信息:
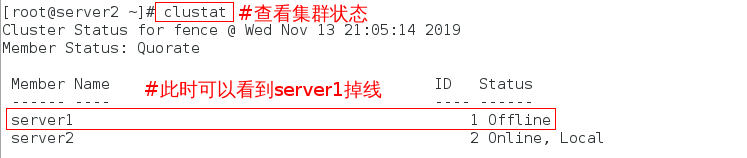
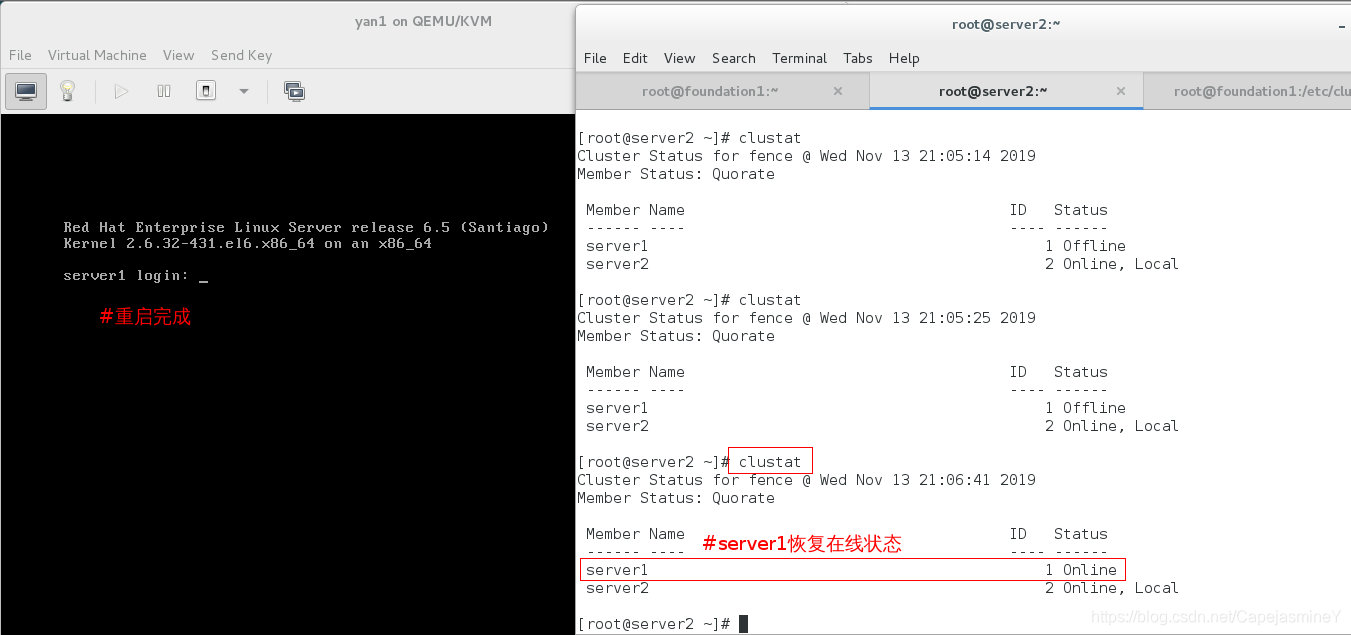
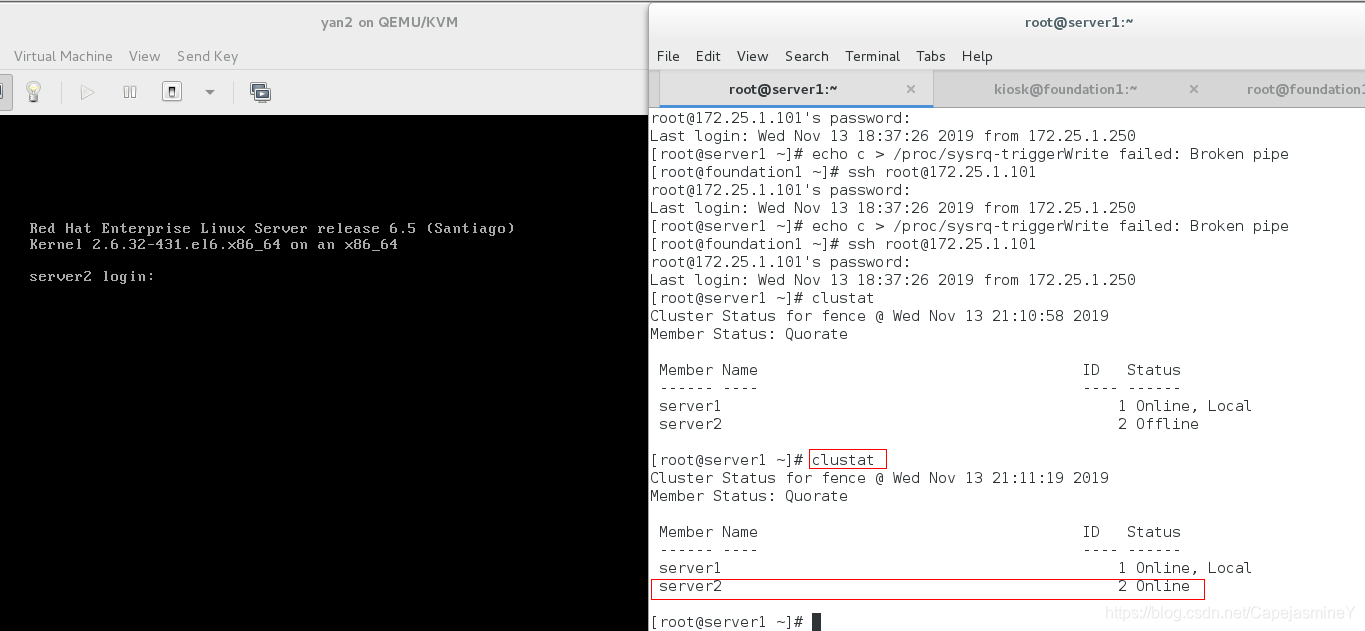
重启完成后查看集群状态:
模拟server2主机网络故障:

此时server1通过fence将server2强制重启,在server1上查看集群状态:
重启完毕,查看集群信息:
三、实现各集群节点之间服务迁移时客户端仍正常访问(高可用HA)
背景 :当一个集群节点(类似于调度器)坏了,如何将服务安全的迁移到另一个集群上面,对于客户访问资源来说,访问毫无感觉,透明的。在集群的图形化管理工具里面进行设置(类似于一个总的负责人,它管理所有的集群节点)
思路 :先设置迁移服务的规则,再设置客户访问资源的规则(入口地址,脚本方式启动web服务),最后资源组:所有的资源都要放在一个组里面,迁移的时候也是也是一整套的删除
3.1 高可用服务配置(以httpd为例)
步骤一:在server1和server2上下载httpd服务,并编写默认发布页面




步骤二:在web界面添加故障转移策略---->失败回切和优先级
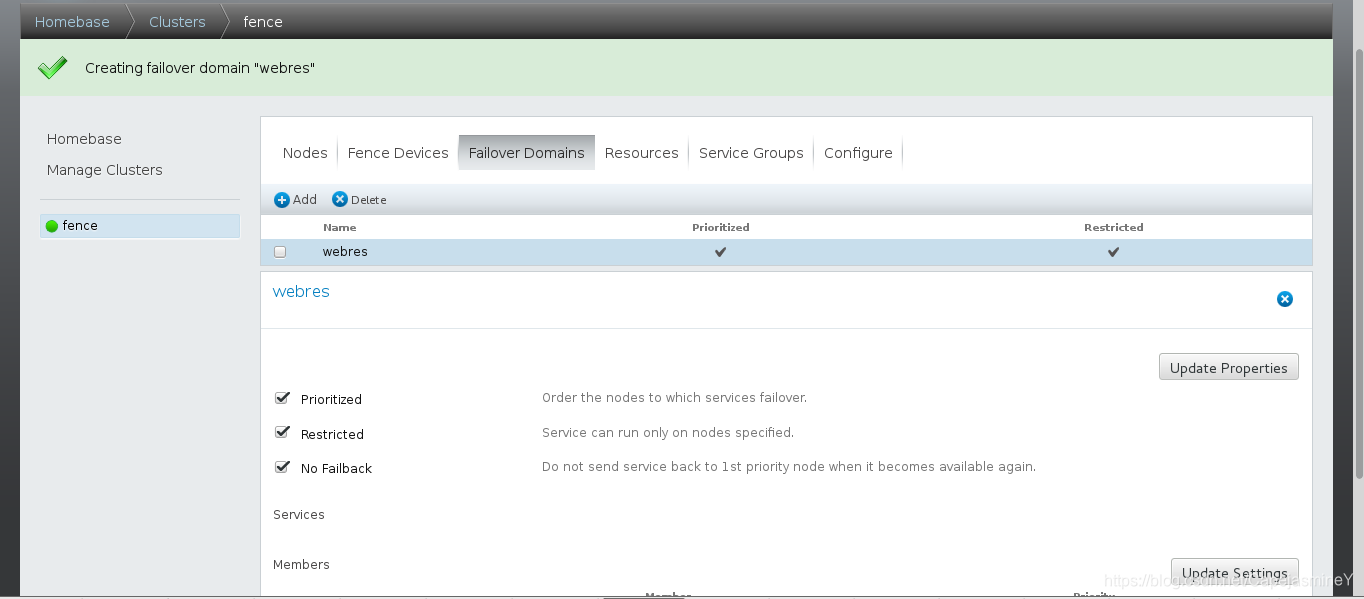
设置步骤:Failover --> Add --> webfail --> Prioritized(对服务故障转移到的节点进行排序) --> Restricted(服务只能在指定的节点上运行) --> No Failback(当服务再次可用时,不要将其发送回优先级为1的节点)(若此选项选中,failover的主机在再次正常时不会按优先级大小回切,否则会)
server2优先级为1,server5优先级为10,数字越小,优先级越高
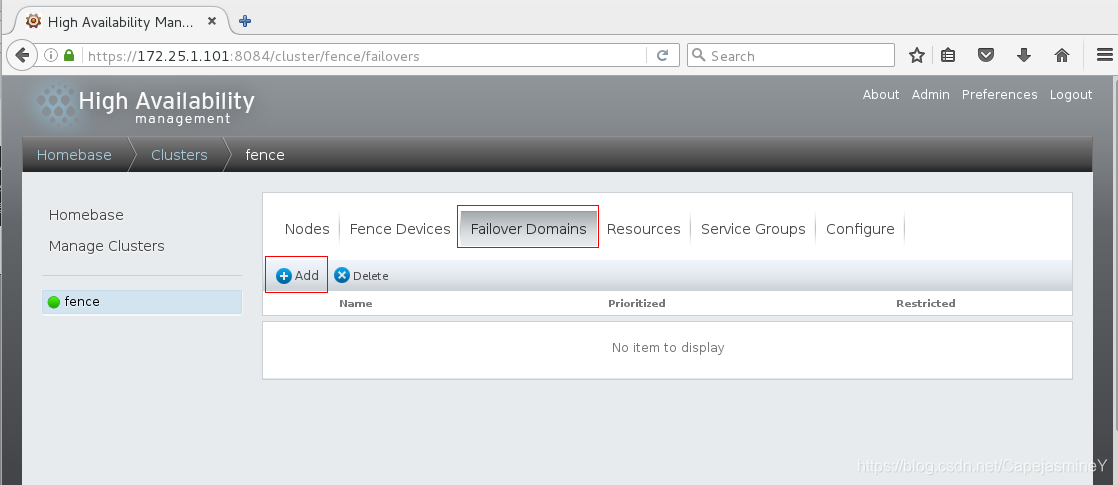

添加成功:
步骤三:添加vip资源和httpd服务
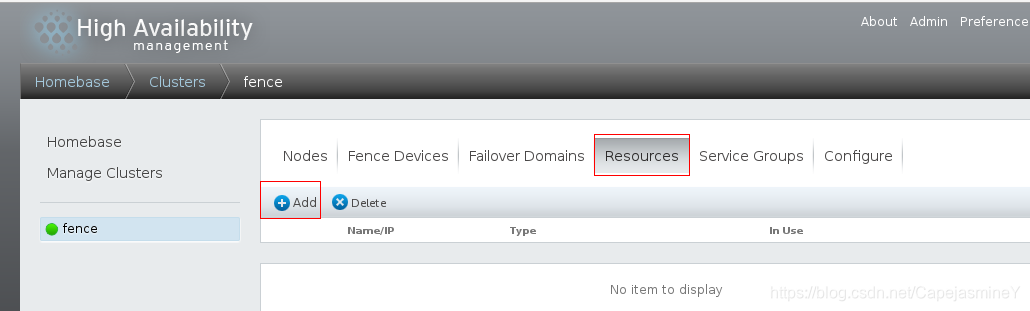

vip资源资源添加成功:
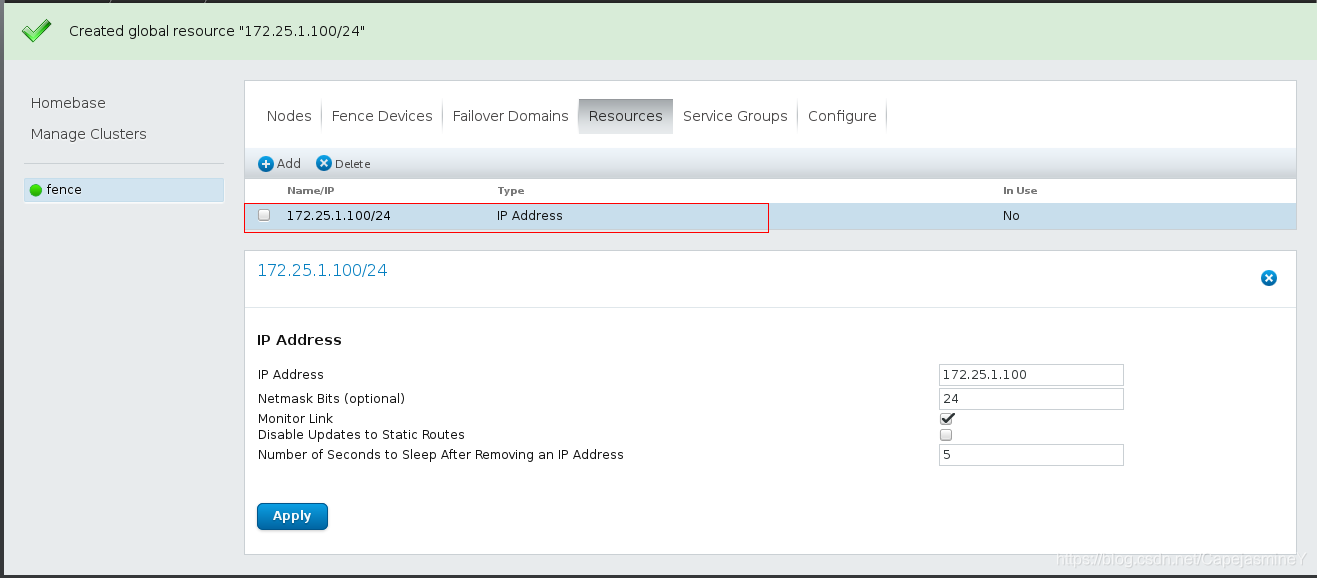
添加httpd服务:
添加script(因为httpd时脚本启动的)
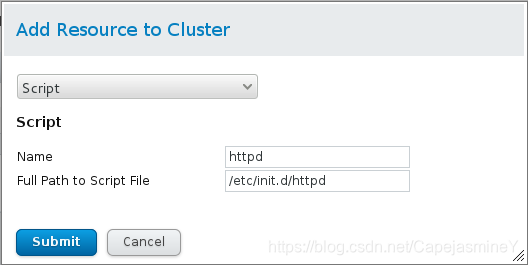
httpd服务添加成功:

资源添加完毕后,不用手动启动httpd服务,集群会自己开启调度器上httpd服务
步骤四:添加服务组到集群,然后添加资源
点击add设置资源组的名字为apache -->添加资源(上一步中添加的vip)—>添加资源(httpd脚本)
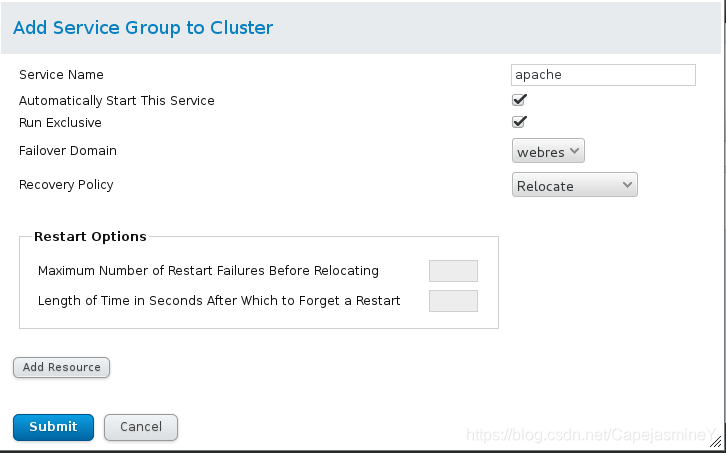
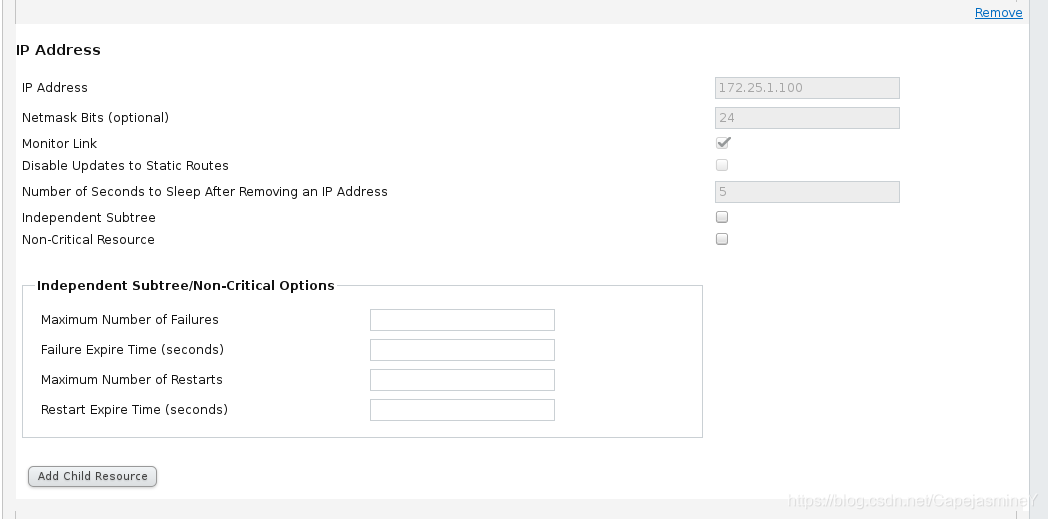

步骤五:测试
在真机上访问vip:
默认转到优先级高的server1上

此时查看集群服务工作状态:
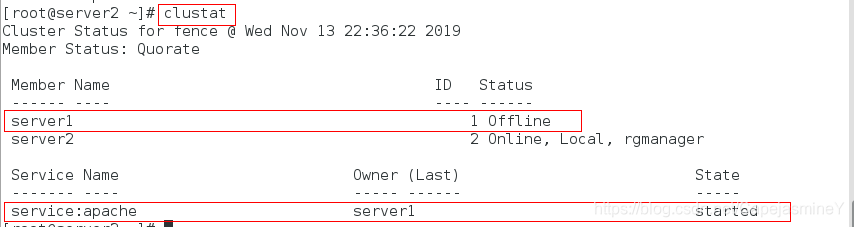
 模拟server1故障:
模拟server1故障:
服务节点转移:
真机测试虚拟vip:
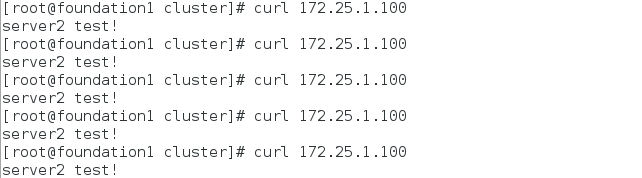
server1被fence强制重启后,恢复故障,服务不回切: