数据库的三大范式
在数据库的表设计中我们需要遵守一些规范,以达到数据库结构合理,查询高效,删改无误的目标。
一、数据库的第一范式:在设计表格的字段时,要确保字段的原子性(即不可再分),比如电话号码这个字段名的表意就不是很明确,它是指家庭电话还是个人手机电话呢?字段的原子性保证了我们在查询数据时的高效和准确。这也是关系型数据库比如MySQL数据库的设计要求。
二、数据库第二范式:在满足第一范式的基础上,我们还需要满足第二范式,即各个字段都应该依赖主键,且不能依赖于主键的一部分,我们可以通过主键唯一确定我们要查询的内容。我们举一个例子,现给出一些信息:学号、姓名、课名、分数、系名、系主任。
接下来我们先介绍一下超键、候选键、主键的概念:
超键:能够唯一标识元组(一条记录)的属性组合,超键的要求比较宽泛,因此只要通过它能唯一标识元祖就可以了,在一张信息表中超键有多种组合形式。
候选键:候选键是特殊的超键,它也能唯一标识元祖,但是候选键中的属性都不能去掉,去掉其中的任一属性,它就不属于超键了。
主键:候选键顾名思义是“候选者”,它是主键的候选者,用户可以在候选键中选择一个作为主键。
主属性和非主属性:包含在键中的属性称为主属性,其余属性为非主属性。
另外再阐述一下依赖的概念:当属性A确定后,属性B也唯一确定,那么称属性B依赖于属性A。
我们再来看看上面的例子。可以唯一标识元组的属性组合是学号和课程,我们选择它作为主键。通过学号和课程,我们可以确定分数;另外通过学号我们可以确定姓名、系名、系主任,系名也可以确定系主任。做出如下关系图:
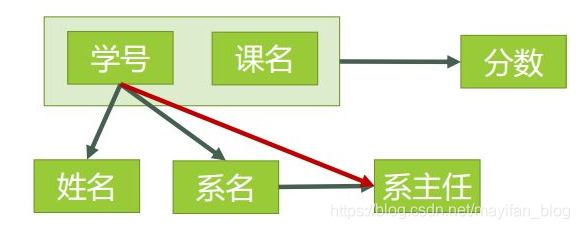
这些属性不可再分,所以他们是满足第一范式的,但它存在非主属性对键的部分依赖,在上图中我们可以发现,姓名、系名、系主任是可以通过学号这个主属性来确定的,第二范式的要求是所有非主属性都是依赖主键,不允许部分依赖。解决这个问题的方案是把这个表划分为两张字表,即单独把学号拿出来作为姓名、系名、系主任的主键。如图:
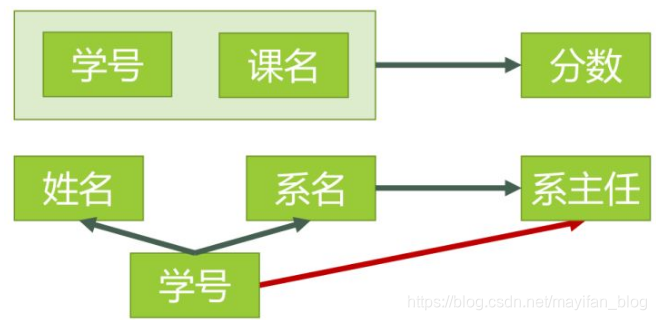
这样便消除了部分依赖的关系了。这可以防止一些数据的冗余,以及数据的插入删除可以导致的错误。
三、数据库的第三范式:我们继续在上述例子的基础上挖深,上面用红色线标识的关系可以表示系主任这个属性是依赖于学号的,同时系主任也可以通过系名唯一确定,系名由学号唯一确定,这时发生了依赖的传递。主键是学号,元祖可以通过学号来唯一确定,但是我们可以假设这样一种情况:如果一个新成立的系,还没有开始招收学生,数据表中没有数据,是不是就表示这个系不存在了?不是的,这时我们需要把系和学号分离开来。数据库第三范式的要求是表中不能存在传递依赖的关系,这使得表格的逻辑不清,数据的存储也会出现错误。解决问题的思路依然是对表格进行划分。如图:
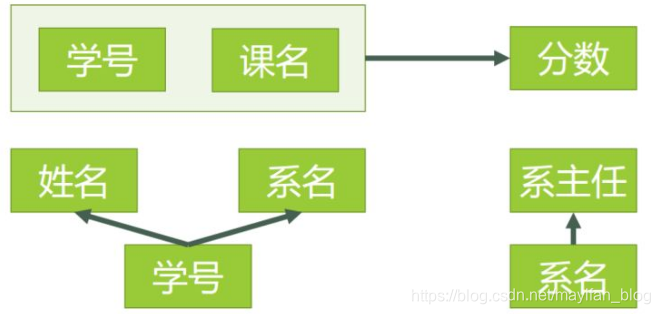
在一个新系成立后,可以在表三添加系名和系主任,招生之后可以添加学号、系名、姓名的对应关系,学生选课后再添加学号课名到分数的对应关系,逻辑清晰,层次分明,满足第三范式。
数据库的左连接、右连接、内连接
左连接: 例如:select * from tbl1 Left Join tbl2 where tbl1.ID = tbl2.ID 。选择需要连接的两张表,Left Join来表示采用了左连接,连接后的表结构是按照上式中的表顺序的,tbl1在左,tbl2在右,左连接是指把右表合并到左表,关联两表的因素自然是两表的字段。上面这句话的意思是把两张表ID相同的部分连接起来。左连接对表一不做任何修改,在表二中找到和表一ID属性匹配的记录,拼接到表一相应记录的后方。此时原表变长了,表二拼接上去后,其他匹配不到的数据部分都用null表示,此时记录之间的顺序可以简单调整,匹配到的记录移到上方。
右连接: 例如:select * from tbl1 Right Join tbl2 where tbl1.ID = tbl2.ID。表顺序不变,变的是把表一右连接到表二,表二内容完整,表一内容可能会缺失。
内连接: 例如:select * from tbl1 inner join tbl2 on tbl1.ID = tbl2.ID。最终得到的表是两者的公共部分(类似于交集)。
作用: 这几种连接方式可以使得我们在查询成绩的时候有所偏重的去查找,比如学生信息和课程成绩两张表的查询,如果我们以学生信息表为主,如果学生信息表中没有某同学,那么左连接时即便他有成绩也不会显示在最终表中;反之,如果以成绩为准,如果没有某同学的成绩记录,右连接时是不会显示这个同学的信息的。这种查询方式使得对表信息的筛选效率大大的提高了。
MySQL的乐观锁和悲观锁
乐观锁: 顾名思义,MySQL在对表格处理时是抱着乐观的态度的,它认为不会有别人在自己操作的时候去修改记录数据,唯一做的事是在操作前取出表单的版本号,最后要更新数据的时候再取版本号比对,观察在这期间是不是有别人操作过数据库导致版本号的更新(+1),如果没有人动过数据库,那么它就可以更新数据了。乐观锁是人为实现的,而不是是数据库自带的。
悲观锁: 持悲观的态度,认为在自己操作的时候会有别人操作数据,所以在自己操作之前,先给表上锁,结束之后再释放锁,这个锁是MySQL自带的,通过相应配置即可实现。我们既可以为表加表锁,也可以为行加行锁。
两种锁的分析比较: 一般乐观锁操作时效率较高,只是简单检查版本号便可以实现安全的操作,悲观锁在每次处理时需要上锁,这必然会带来一些资源的开销。一般乐观锁被广泛使用,因为其简单高效;而悲观锁在高并发且易出现资源竞争的情况下会比乐观锁更有优势,因为如果经常竞争性地对表进行操作,在乐观锁的情况下容易出现操作失效,降低了效率,而悲观锁可以确保指令的执行,可靠性好。
MySQL语句知识点扩展
1、SELECT DISTINCT “栏位名” FROM “表格名”
作用:在筛选的同时去掉重复的内容。
2、SELECT “栏位名” FROM “表格名” WHERE “简单条件” { [AND|OR] “简单条件” }
作用:多条件筛选。
3、SELECT “栏位名” FROM “表格名” WHERE “栏位名” IN (‘值一’,‘值二’…)
SELECT “栏位名” FROM “表格名” WHERE “栏位名” BETWEEN ‘值一’ AND ‘值二’
作用:查询指定栏目的内容,同时满足其他栏目的某些条件。
4、select * from table1 where name like ‘%明%’ //含有“明”字的
select * from table1 where name like ‘%[0-9]%’ //含有数字的
select * from table1 where name like ‘%[a-z]%’ //含有小写字母的
select * from table1 where name like ‘%[!0-9]%’ //不含数字的
作用:模糊查询含有指定内容的记录。
5、SELECT “栏位名” FROM “表格名” WHERE “简单条件” ORDER BY “栏位名” [ASC,DESC]
作用:筛选后降序(DESC)或者升序(ASC)排列。
6、SELECT COUNT “栏位名” FROM “表格名”
作用:查询表中记录的行数。
7、SELECT “栏位名1”,SUM “栏位名2” FROM “表格名” GROUP BY “栏位1”
作用:把栏目2中数据按照栏目1的内容计算合计值,合并栏目1中相同的部分。
8、SELECT “栏位名1”,SUM “栏位名2” FROM “表格名” GROUP BY “栏位1” HAVING(函数条件)
作用:在上题的基础上,另加函数条件约束。
常见完整性约束:
非空约束:not null
唯一约束:unique
主键约束:primary key
外键约束:foreign key
检查约束:check (确保添加内容在check约束范围内)
添加非空约束:modify(score number(10,2) not null)
删除非空约束:drop constraint std1_id_nn ;
加入检查约束:add(constraint std1_score_ck check(score>=0 and score<=100)) ;
有效化无效化约束:disable 、enable
级联删除:ON DELETE CASCADE (当父表中的列被删除时,字表中相对应的列也被删除)
级联置空:ON DELETE SET NULL (当父表中的列被删除时,字表中相对应的列被置空)