Kafka Java客户端里的生产者
如果不了解Kafka的Java 客户端,可以先看看示例 Kafka Java 客户端入门示例
生产者发送消息的基本流程


从创建一个 ProducerRecord 对象开始,ProducerRecord 对象需要包含目标主题和要发送的内容。我们还可以指定键或分区。在发送 ProducerRecord 对象时,生产者要先把键和值对象序列化成字节数组,这样它们才能够在网络上传输。
接下来,数据被传给分区器。如果之前在 ProducerRecord 对象里指定了分区,那么分区器就不会再做任何事情,直接把指定的分区返回。如果没有指定分区,那么分区器会根据 ProducerRecord 对象的键来选择一个分区。选好分区以后,生产者就知道该往哪个主题和分区发送这条记录了。
紧接着,这条记录被添加到一个记录批次里(双端队列,尾部写入),这个批次里的所有消息会被发送到相同的主题和分区上。有一个独立的线程负责把这些记录批次发送到相应的broker上。
服务器在收到这些消息时会返回一个响应。如果消息成功写入Kafka,就返回一个 RecordMetaData 对象,它包含了主题和分区信息,以及记录在分区里的偏移量。

如果写入失败,则会返回一个错误。生产者在收到错误之后会尝试重新发送消息,几次之后如果还是失败,就返回错误信息。
生产者发送消息一般会发生两类错误:
- 可重试错误,比如连接错误(可通过再次建立连接解决)、无主no leader(可通过分区重新选举首领解决)。
- 不可重试错误,比如“消息太大”异常,具体见message.max.bytes,这类消息不会进行任何重试,直接抛出异常。
使用Kafka生产者
三种发送方式
我们通过生成者的 send 方法进行发送。send 方法会返回一个包含 RecordMetadata 的 Future 对象。

发送并忘记
忽略 send 方法的返回值,不做任何处理。大多数情况下,消息会正常到达,而且生产者会自动重试,但有时会丢失消息。
try {
ProducerRecord<String,String> record;
try {
//TODO 发送4条消息
for(int i=0;i<4;i++){
record = new ProducerRecord("hello-topic", null,"hello");
producer.send(record);//发送并发忘记(重试会有)
System.out.println(i+",message is sent");
}
} catch (Exception e) {
e.printStackTrace();
}
} finally {
producer.close();
}
同步发送
获得 send 方法返回的 Future 对象,在合适的时候调用 Future 的 get 方法。
try {
/*待发送的消息实例*/
ProducerRecord<String,String> record;
try {
record = new ProducerRecord<>(
"hello-topic","key0","value0");
Future<RecordMetadata> future = producer.send(record);
System.out.println("do other sth");
RecordMetadata recordMetadata = future.get();//阻塞在这个位置
if(null!=recordMetadata){
System.out.println("offset:"+recordMetadata.offset()+"-" +"partition:"+recordMetadata.partition());
}
} catch (Exception e) {
e.printStackTrace();
}
} finally {
producer.close();
}
异步发送
实现接口 org.apache.kafka.clients.producer.calback,然后将实现类的实例作为参数传递给 send 方法。
/*待发送的消息实例*/
ProducerRecord<String,String> record;
try {
record = new ProducerRecord(
"hello-topic","key1","value1");
producer.send(record, new Callback() {
public void onCompletion(RecordMetadata metadata,
Exception exception) {
if(null!=exception){
exception.printStackTrace();
}
if(null!=metadata){
System.out.println("offset:"+metadata.offset()+"-"
+"partition:"+metadata.partition());
}
}
});
} finally {
producer.close();
}
多线程生产
Kafkaproducer 的实现是线程安全的,所以我们可以在多线程的环境下,安全地使用 Kafkaproducer 的实例。
点击这里查看多线程生产和多线程消费的示例。
常用配置
生产者有很多属性可以设置,大部分都有合理的默认值,无需调整。有些参数可能对内存使用,性能和可靠性方面有较大影响。可以参考 org.apache.kafka.clients.producer 包下的 Producerconfig 类。
-
acks
指定了必须要有多少个分区副本收到消息,生产者才会认为写入消息是成功的,这个参数对消息丢失的可能性有重大影响。
acks=0:生产者在写入消息之前不会等待任何来自服务器的响应,容易丢消息,但是吞吐量高。
acks=1:只要集群的首领节点收到消息,生产者会收到来自服务器的成功响应。如果消息无法到达首领节点(比如首领节点崩溃,新首领没有选举出来),生产者会收到一个错误响应,为了避免数据丢失,生产者会重发消息。不过,如果一个没有收到消息的节点成为新首领,消息还是会丢失。默认使用这个配置。
acks=all:只有当所有参与复制的节点都收到消息,生产者才会收到一个来自服务器的成功响应。延迟高。
金融业务,主备外加异地灾备。所以很多高可用场景一般不是设置2个副本,有可能达到5个副本,不同机架上部署不同的副本,异地上也部署一套副本。 -
batch.size
当多个消息被发送同一个分区时,生产者会把它们放在同一个批次里。该参数指定了一个批次可以使用的内存大小,按照字节数计算。当批次内存被填满后,批次里的所有消息会被发送出去。但是生产者不一定都会等到批次被填满才发送,半满甚至只包含一个消息的批次也有可能被发送。缺省16384(16k),如果一条消息超过了批次的大小,会写不进去。 -
inger.ms
指定了生产者在发送批次前等待更多消息加入批次的时间。它和 batch.size 以先到者为先。也就是说,一旦我们获得消息的数量够 batch.size 的数量了,他将会立即发送而不顾这项设置。这个设置默认为 0,即没有延迟。设定 linger.ms=5,将会减少请求数目,同时会增加 5ms 的延迟,但也会提升消息的吞吐量。 -
buffer.memory
设置生产者内存缓冲区的大小,生产者用它缓冲要发送到服务器的消息。如果数据产生速度大于向 broker 发送的速度,导致生产者空间不足,producer 会阻塞或者抛出异常。缺省 33554432(32M) -
max.block.ms
指定了在调用 send 方法或者使用 partitionsFor 方法获取元数据时生产者的阻塞时间。当生产者的发送缓冲区已满,或者没有可用的元数据时,这些方法就会阻塞。在阻塞时间达到 max.block.ms 时,生产者会抛出超时异常。缺省 60000ms -
retries
发送失败时,指定生产者可以重发消息的次数(缺省Integer.MAX_VALUE)。默认情况下,生产者在每次重试之间等待100ms,可以通过参数 retry.backof.ms 参数来改变这个时间间隔。 -
receive.buffer.bytes 和 send.buffer.bytes
指定 TCP socket 接受和发送数据包的缓存区大小。如果它们被设置为-1,则使用操作系统的默认值。如果生产者或消费者处在不同的数据中心,那么可以适当增大这些值,因为跨数据中心的网络一般都有比较高的延迟和比较低的带宽。缺省 102400 -
compression.type
producer 用于压缩数据的压缩类型。默认是无压缩。选项值有 none、gzip、snappy。压缩最好用于批量处理,批量处理消息越多,压缩性能越好。snappy 占用 cpu少,提供较好的性能和可观的压缩比,如果比较关注性能和网络带宽,用这个。如果带宽紧张,用gzip,会占用较多的cpu,但提供更高的压缩比。 -
client.id
当向 server 发出请求时,这个字符串会发送给 server。目的是能够追踪请求源头,以此来允许 ip/port 许可列表之外的一些应用可以发送信息。这项应用可以设置任意字符串,因为没有任何功能性的目的,除了记录和跟踪。 -
max.in.flight.requests.per.connection
指定了生产者在接收到服务器响应之前可以发送多个消息,值越高,占用的内存越大,当然也可以提升吞吐量。发生错误时,可能会造成数据的发送顺序改变,默认是5。
如果需要保证消息在一个分区上的严格顺序,这个值应该设为1。不过这样会严重影响生产者的吞吐量。 -
request.timeout.ms
客户端将等待请求的响应的最大时间,如果在这个时间内没有收到响应,客户端将重发请求;超过重试次数将抛异常,默认30秒。 -
metadata.fetch.timeout.ms
是指我们所获取的一些元数据的第一个时间数据。元数据包含:topic,host,partitions。此项配置是指当等待元数据 fetch 成功完成所需要的时间,否则会跑出异常给客户端 -
max.request.size
控制生产者发送请求最大大小。默认这个值为1M,如果一个请求里只有一个消息,那这个消息不能大于1M,如果一次请求是一个批次,该批次包含了1000条消息,那么每个消息不能大于1KB。注意:broker具有自己对消息记录尺寸的覆盖,如果这个尺寸小于生产者的这个设置,会导致消息被拒绝。这个参数和Kafka主机的 message.max.bytes 参数有关系。如果生产者发送的消息超过 message.max.bytes 设置的大小,就会被Kafka服务器拒绝。
一般来说,就记住acks、batch.size、linger.ms、max.request.size就行了,因为这4个参数重要些,其他参数一般没有太大必要调整。
顺序保证
Kafka可以保证同一个分区里的消息是有序的。也就是说,发送消息时,主题只有且只有一个分区,同时生产者按照一定的顺序发送消息,broker就会按照这个顺序把它们写入分区,消费者也会按照同样的顺序读取它们。
在某些情况下,顺序是非常重要的。例如,往一个账户存入100元再取出来,这个与先取钱再存钱是截然不同的!
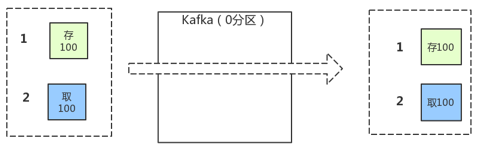
如果 retires 为非零整数(默认),同时把 max.in.flight.requests.per.connection 设为比1大的数(默认),那么,如果第一个批次消息写入失败,而第二个批次写入成功,broker会重试写入第一个批次。如果此时第一个批次也写入成功,那么两个批次的顺序就反过来了。
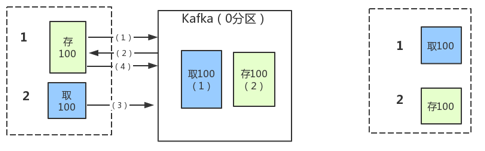
如果某些场景要求消息是有序的,把 max.in.flight.request.per.connection 设为1,这样在生产者尝试发送第一批消息时,就不会有其他的消息发送给 broker。不过这样会严重影响生产者的吞吐量,所以只有在对消息的顺序有严格要求的情况下才能这么做。
自定义分区器
某些情况下,数据特性决定了需要进行特殊分区,比如电商业务,北京的业务量明显比较大,占据了总业务量的20%,我们需要对北京的订单进行单独分区处理,默认的散列分区算法不合适了,我们就可以自定义分区算法,对北京的订单单独处理,其他地区沿用散列分区算法。或者某些情况下,我们用 value 来进行分区。
自定义一个 Partitioner :
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;
import org.apache.kafka.common.PartitionInfo;
import java.util.List;
import java.util.Map;
public class SelfPartitioner implements Partitioner {
public int partition(String topic, Object key, byte[] keyBytes,
Object value, byte[] valueBytes, Cluster cluster) {
//拿到
List<PartitionInfo> partitionInfos = cluster.partitionsForTopic(topic);
//TODO 分区数
int num = partitionInfos.size();
//TODO 根据value与分区数求余的方式得到分区ID
int parId = (value).hashCode()%num;
return parId;
}
public void close() {
//do nothing
}
public void configure(Map<String, ?> configs) {
//do nothing
}
}
使用:
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.100.14:9092");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
//填写全限定类名
properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, "SelfPartitioner");
参考:King——笔记-Kafka
