物理存储机制
Kafka的基本存储单元是分区。分区无法在多个broker间进行再细分,也无法在同一个broker的多个磁盘上进行再细分。
在配置Kafka的时候,管理员指定了一个用于存储分区的目录清单——也就是log.dirs参数的值(不要把它与存放错误日志的目录混淆了,日志目录是配置在log4j.properties文件里的)。该参数一般会包含每个挂载点的目录。
分区分配
在创建主题时,Kafka首先会决定如何在broker间分配分区。假设你有6个broker,打算创建一个包含10个分区的主题,并且复制系数为3(确保至少有3台broker)。那么Kafka就会有30个分区副本,它们可以被分配给6个broker。在进行分区分配时,我们要达到如下的目标。
- 在broker间平均地分布分区副本。对于我们的例子来说,就是要保证每个broker可以分到5个副本。
- 确保每个分区的每个副本分布在不同的broker上。假设分区0的首领副本在broker2上,那么可以把跟随者副本放在broker3和broker4上,但不能放在broker2上,也不能两个都放在broker3上。
- 如果为broker指定了机架信息,那么尽可能把每个分区的副本分配到不同机架的broker上。这样做是为了保证一个机架的不可用不会导致整体的分区不可用。
为了实现这个目标,我们先随机选择一个broker(假设是4),然后使用轮询的方式给每个broker分配分区来确定首领分区的位置。于是,首领分区0会在broker4上,首领分区1会在broker5上,首领分区2会在broker0上(只有6个broker),并以此类推。然后,我们从分区首领开始,依次分配跟随者副本。如果分区0的首领在broker4上,那么它的第一个跟随者副本会在broker5上,第二个跟随者副本会在broker0上。分区1的首领在broker5上,那么它的第一个跟随者副本在broker0上,第二个跟随者副本在broker1上。
最少使用原则:为分区和副本选好合适的broker之后,接下来要决定这些分区应该使用哪个目录。我们单独为每个分区分配目录,规则很简单:计算每个目录里的分区数量,新的分区总是被添加到数量最小的那个目录里。也就是说,如果添加了一个新磁量,所有新的分区都会被创建到这个磁盘上。因为在完成分配工作之前,新磁盘的分区数量总是最少的。
默认只有一个目录:

文件管理
保留数据是Kafka的一个基本特性,Kafka不会一直保留数据,也不会等到所有消费者都读取了消息之后才删除消息。相反,Kafka管理员为每个主题配置了数据保留期限,规定数据被删除之前可以保留多长时间,或者清理数据之前可以保留的数据量大小。
因为在一个大文件里查找和删除消息是很费时的,也很容易出错,所以分区分成若干个片段。默认情况下,每个片段包含1GB或一周的数据,以较小的那个为准。在 broker 往分区写入数据时,如果达到片段上限,就关闭当前文件,并打开一个新文件。
当前正在写入数据的片段叫作活跃片段,活动片段永远不会被删除。如果你要保留数据一周,而且每天使用一个新片段,那么你就会看到,每天在使用一个新片段的同时会删除一个最老的片段一所以大部分时间该分区会有7个片段存在。
文件格式
Kafka的消息和偏移量保存在文件里。保存在磁盘上的数据格式与从生产者发送过来或者发送给消费者的消息格式是一样的。因为使用了相同的消息格式进行磁盘存储和网络传输,Kafka 可以使用零复制技术给消费者发送消息,同时避免了对生产者已经压缩过的消息进行解压和再压缩。
除了键、值和偏移量外,消息里还包含了消息大小、校验和、消息格式版本号、压缩算法(snappy、Gzip或Lz4)和时间戳(在0.10.0版本里引入的)。时间戳可以是生产者发送消息的时间,也可以是消息到达broker的时间,这个是可配置的。
如果生产者发送的是压缩过的消息,那么同一个批次的消息会被压缩在一起,被当作“包装消息”进行发送。于是,broker就会收到一个这样的消息,然后再把它发送给消费者。消费者在解压这个消息之后,会看到整个批次的消息,它们都有自己的时间戳和偏移量。
如果在生产者端使用了压缩功能(极力推荐),那么发送的批次越大,就意味着在网络传输和磁盘存储方面会获得越好的压缩性能,同时意味着如果修改了消费者使用的消息格式(例如,在消息里增加了时间戳),那么网络传输和磁盘存储的格式也要随之修改,而且broker要知道如何处理包含了两种消息格式的文件。一种是普通消息,一种是包装消息:
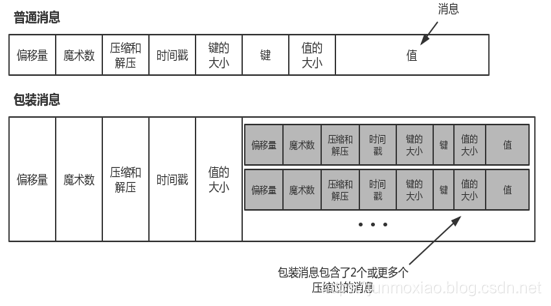
Kafka附带了一个叫DumpLogSegment的工具,可以用它查看片段的内容。它可以显示每个消息的偏移量、校验和、魔术数字节、消息大小和压缩算法。
索引
消费者可以从Kafka的任意可用偏移量位置开始读取消息。假设消费者要读取从偏移量100开始的1MB消息,那么broker必须立即定位到偏移量100(可能是在分区的任意一个片段里),然后开始从这个位置读取消息。为了帮助broker 更快地定位到指定的偏移量,Kafka为每个分区维护了一个索引。索引把偏移量映射到片段文件和偏移量在文件里的位置。
索引也被分成片段,所以在删除消息时,也可以删除相应的索引。Kafka不维护索引的校验和。如果索引出现损坏,Kafka会通过重新读取消息并录制偏移量和位置来重新生成索引。如果有必要,管理员可以删除索引,这样做是绝对安全的,Kafka会自动重新生成这些索引。
超时数据的清理机制
一般情况下,Kafka会根据设置的时间保留数据,把超过时效的旧数据删除掉。
不过,试想一下这样的场景,如果你使用Kafka保存客户的收货地址,那么保存客户的最新地址比保存客户上周甚至去年的地址要有意义得多,这样你就不用担心会用错旧地址,而且短时间内客户也不会修改新地址。另外一个场景,一个应用程序使用Kafka保存它的状态,每次状态发生变化,它就把状态写入Kafka。在应用程序从崩溃中恢复时,它从Kafka读取消息来恢复最近的状态。
在这种情况下,应用程序只关心它在崩溃前的那个状态,而不关心运行过程中的那些状态。
Kafka通过改变主题的保留策略来满足这些使用场景。早于保留时间的事件会被删除,为每个键保留最新的值,从而达到清理的效果每个日志片段可以分为以下两个部分。
- 干净的部分,这些消息之前被清理过,每个键只有一个对应的值,这个值是上一次清理时保留下来的。
- 污浊的部分,这些消息是在上一次清理之后写入的。
为了清理分区,清理线程会读取分区的污独部分,并在内存里创建一个map。map里的每个元素包含了消息键的散列值和消息的偏移量。键的散列值是16B,加上偏移量总共是24B。如果要清理一个1GB的日志片段,并假设每个消息大小为1KB,那么这个片段就包含一百万个消息,而我们只需要用24MB的map就可以清理这个片段。(如果有重复的键,可以重用散列项,从而使用更少的内存。)
清理线程在创建好偏移量map后,开始从干净的片段处读取消息,从最旧的消息开始,把它们的内容与map里的内容进行比对。它会检查消息的键是否存在于map中,如果不存在,那么说明消息的值是最新的,就把消息复制到替换片段上。如果键已存在,消息会被忽略,因为在分区的后部已经有一个具有相同键的消息存在。在复制完所有的消息之后,我们就将替换片段与原始片段进行交换,然后开始清理下一个片段。完成整个清理过程之后,每个键对应一个不同的消息——这些消息的值都是最新的。清理前后的分区片段如图所示。
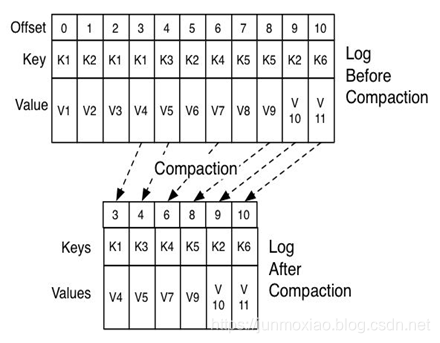
清理的思想就是根据Key的重复来进行整理,注意,它不是数据删除策略,而是类似于压缩策略,如果key送入了值,对于业务来说,key的值应该是最新的value才有意义,所以进行清理后只会保存一个key的最新的value。
这个适用于一些业务场景,比如说key代表用户lD,Value用户名称,如果使用清理功能就能够达到最新的用户的名称的消息。
参考:King——笔记-Kafka
