学习笔记
转载:https://blog.csdn.net/waterhawk/article/details/50723677
转载:https://blog.csdn.net/jasonchen_gbd/article/details/79462064
先简单说一下DMA的CACHE一致性是个啥问题?
CPU在访问内存时,首先判断所要访问的内容是否在Cache中,如果在,就称为“命中(hit)”,此时CPU直接从Cache中调用该内容;否则,就 称为“ 不命中”,CPU只好去内存中调用所需的子程序或指令了。CPU不但可以直接从Cache中读出内容,也可以
直接往其中写入内容。由于Cache的存取速 率相当快,使得CPU的利用率大大提高,进而使整个系统的性能得以提升。
Cache的一致性就是直Cache中的数据,与对应的内存中的数据是一致的。
DMA是直接操作总线地址的,这里先当作物理地址来看待吧(系统总线地址和物理地址只是观察内存的角度不同)。如果cache缓存的内存区域不包括DMA分配到的区域,那么就没有一致性的问题。但是如果cache缓存包括了DMA目的地址的话,会出现什么什么问题呢?
问题出在,经过DMA操作,cache缓存对应的内存数据已经被修改了,而CPU本身不知道(DMA传输是不通过CPU的),它仍然认为cache中的数 据就是内存中的数据,以后访问Cache映射的内存时,它仍然使用旧的Cache数据。这样就发生Cache与内存的数据“不一致性”错误。
来个外语的:
The cache.
This entity is essentially "memory state" as the flush architecture views it. In general it has the following properties:
It will always hold copies of data which will be viewed as uptodate by the local processor.
Its proper functioning may be related to the TLB and process/kernel page mappings in some way, that is to say they may depend upon each other.
It may, in a virtually cached configuration, cause aliasing problems if one physical page is mapped at the same time to two virtual pages, and due to to the bits of an address used to index the cache line, the same piece of data can end up residing in the cache twice, allowing inconsistancies to result.
Devices and DMA may or may not be able to see the most up to date copy of a piece of data which resides in the cache of the local processor.
Currently, it is assumed that coherence in a multiprocessor environment is maintained by the cache/memory subsystem. That is to say, when one processor requests a datum on the memory bus and another processor has a more uptodate copy, by whatever means the requestor will get the uptodate copy owned by the other processor.
(NOTE: SMP architectures without hardware cache coherence mechanisms are indeed possible, the current flush architecture does not handle this currently. If at at some point a Linux port to some system where this is an issue occurrs, I will add the necessary hooks. But it will not be pretty.)
以前接触比较多的几种内存机制:
带CACHE的内存有两种,写回(writeback)、写穿(writethrough);或者非CACHE空间。
搞DMA的时候发现非CACHE其实还可以细分两种,一致(coherent),写缓存(writecombine)。
其实后面这两种,网上也找不到标准的翻译方法,以前书上也没具体介绍过,纯属自己瞎翻译。
又一个因为复制粘贴导致的网络上流行结果:
一致性DMA映射申请的缓存区能够使用cache,并且保持cache一致性。一致性映射具有很长的生命周期,在这段时间内占用的映射寄存器,即使不使用也不会释放。生命周期为该驱动的生命周期
千万别被这句话误导了,这句是错误的。因为,同样的网页里以下这段是正确的。
dma_alloc_coherent 在 arm 平台上会禁止页表项中的 C (Cacheable) 域以及 B (Bufferable)域。
而 dma_alloc_writecombine 只禁止 C (Cacheable) 域.
C 代表是否使用高速缓冲存储器, 而 B 代表是否使用写缓冲区。
这样,dma_alloc_writecombine 分配出来的内存不使用缓存,但是会使用写缓冲区。而 dma_alloc_coherent 则二者都不使用。
C B 位的具体含义
0 0 无cache,无写缓冲;任何对memory的读写都反映到总线上。对 memory 的操作过程中CPU需要等待。
0 1 无cache,有写缓冲;读操作直接反映到总线上;写操作,CPU将数据写入到写缓冲后继续运行,由写缓冲进行写回操作。
1 0 有cache,写通模式;读操作首先考虑cache hit;写操作时直接将数据写入写缓冲,如果同时出现cache hit,那么也更新cache。
1 1 有cache,写回模式;读操作首先考虑cache hit;写操作也首先考虑cache hit。
效率最高的写回,其次写通,再次写缓冲,最次非CACHE一致性操作。
其实,写缓冲也是一种非常简单得CACHE,为何这么说呢。
我们知道,DDR是以突发读写的,一次读写总线上实际会传输一个burst的长度,这个长度一般等于一个cache line的长度。
cache line是32bytes。即使读1个字节数据,也会传输32字节,放弃31字节。
写缓冲是以CACHE LINE进行的,所以写效率会高很多。
简单写了一个测试程序,验证在ARM平台上的DMA一致性问题。
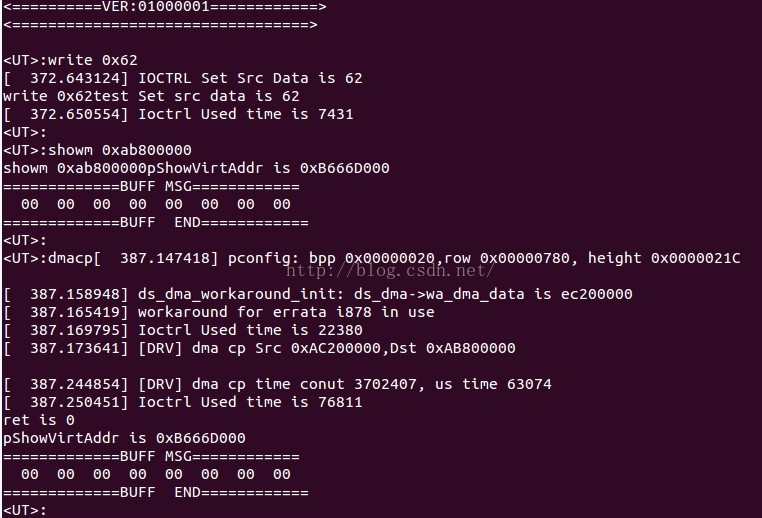
dst 地址0xab800000, dst 原始数据0x00,长度8
src 地址0xac200000, src 原始数据0x62,长度8
为保证验证可靠,源地址是一致性内存,目的地址是写回内存。
实验步骤:
1. 读两个内存数据,用于后续比较,因为源地址是非CACHE的,所以修改一定会被写到DDR上。
2. 对目的地址的读8遍。
3. DMA拷贝源到目的地址。
4. 读目的地址。
实验结果说明,目的地址读取到的值依然是0.
解释:
第二步骤实际作用是为了在cache中,目的地址不被替换出cache。
我们知道一般OS采用的CACHE替换算法都是基于局部性原理,当一个数据在连续时间内经常被操作,则对应的cache line就有更大概率被保留。
而DMA拷贝完成前,只要目的地址的CACHE LINE没有被替换出去,则DMA完成后,CPU会访问目的地址时,一定是原始数据。
也就是图中最终结果,目的地址数据依然是原始数据0x00.
此时CPU访问的是CACHE,但也有可能访问的是DDR,甚至可能出现正确结果0x62。
1. 访问CACHE
这是最简单的了,因为CACHE LINE没有被替换,CACHE HIT。所以,CPU不知道DDR数据已经变化,返回原始数据。
2. 访问DDR
同样好理解,因为如果之前设置了目的地址的数据,这时该cache line会成为dirty状态。
在DMA完成之后,如果该cache line被替换到DDR上,那么DDR的数据就又成了原始数据。
目的DDR的变化是 0x00 --> 0x62 (DMA) --> 0x00 (cache writeback).
3. 出现正确结果
这个涉及的内容最多。如果之前没有设置目的地址的值,只是读目的地址的值,则该cache line是干净的。
在DMA完成之后,该cache line如果被替换,则cache line里的0x00错误数据会被丢弃(因为是干净的,CACHE认为没必要写回)
而CPU在没有CACHE HIT时,就会从DDR上读到正确数据0x62.
这同样说明2个道理,
第一,错误的DMA操作,导致了数据一致性的问题,但一定条件下,这个错误是不会被感知到的。
第二,即使读到的100%是正确数据,你也不能从经验断定这个程序是对的,但只要有一次错误,就可以认为程序是错误的了。
我的解决方案:
先上结果
在DMA拷贝前,进行一次CACHE CLEAN,或CACHE FLUSH。
DMA拷贝完成之后,进行一次CACHE FLUSH。
就能很大概率避免一致性的问题。
这个解决方案不是标准的解决方案,使用一致性内存或写缓冲内存,是无论何时100%正确的。
而这个方案,是一个很大概率的正确方案,在绝大部分合理场景下,可以以最高效率访问内存。
其实,这个解决方案,大概率按照第一个实验的条件3执行的。
为什么要执行这2个操作呢。
DMA拷贝前,CACHE CLEAN保证了条件3中所述,目的地址的CACHE LINE是干净的。最大概率保证DMA传输时间内,不会再有写回动作。
DMA拷贝完成后,CACHE FLUSH保证了,CACHE会重新构建,目的地址的值一定是从DDR上读取最新数据。
而在拷贝过程中,CPU如果只是读取目的地址,会直接访问CACHE,而不访问DDR。
这个方案使用起来很简单,但一定要符合以下条件才能取得合理结果(适用于大部分使用DMA的情况):
1. DMA的数据一定是大数据搬移(至少是DCACHE的10倍以上)。因为仅1次CACHE FLUSH就会毁掉你整个DCACHE的数据,至少嵌入式平台也是128KB以上,这些数据访问DDR重建也是要时间的。 (这一条保证使用DMA的时间效率)
2.在DMA拷贝期间,不会对目的地址进行写操作。(这一条可以保证数据绝对正确)
OK,本篇完成了。最后看到linux下老外写了一个文章,说DMA导致的一致性,linux有一套解决方案,但网上很少人有说,慢慢看。
