描述:采取了scrapy框架对途牛网旅游数据进行了爬取,刚开始练手,所以只爬了四个字段用作测试,分别是景点名称、景点位置、景点开放时间、景点描述,爬取结果存的是json格式。
部分数据:

部分代码:
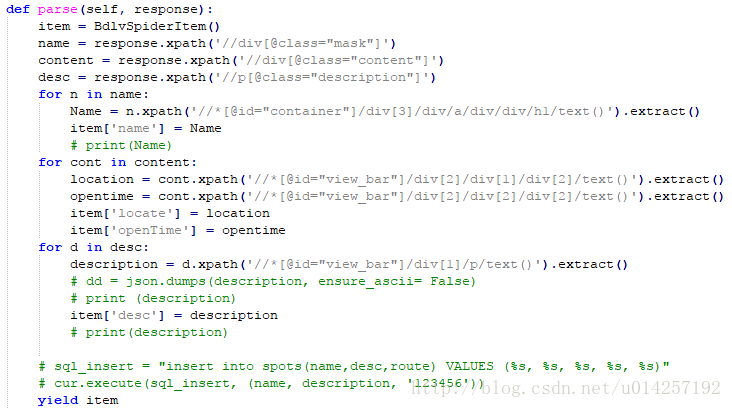
遇到的问题:start_urls是不能动态添加URL的,这个还需要研究,这里只是简单把所有待爬取的网址全扔进了start_urls里面,这是可行的,但是对网址的预处理就很耗时间了。然后是对汉字编码的处理,在scrapy中一开始传到json中的数据总是/uxxx类型的,这需要在pipeline.py、setting.py中都进行修改,具体修改如下:
在pipelines.py中,修改代码如下:
def __init__(self):
self.file = codecs.open('items.json', 'wb', encoding='utf-8')
#
def process_item(self, item, spider):
line = json.dumps(dict(item), ensure_ascii=False) + "\n"
self.file.write(line)
return item
#
def spider_closed(self, spider):
self.file.close()在settings.py中,添加如下代码:
ITEM_PIPELINES = {
'bdlv_spider.pipelines.BdlvSpiderPipeline': 800,
}其中,BdlvSpiderPipeline是pipelines.py中的类名。
