1.正常情况下我们排序都会按照某一列直接order by xxx,我的需求是按照某一列的部分进行排序,正常排序如下

2.如图所示我查出来的字段为string型且固定为6位,我想按照这六位的前两位和后三位进行升序排列,即忽略第三位的存在,目前查出来的是按照整体排的序,修改如下:
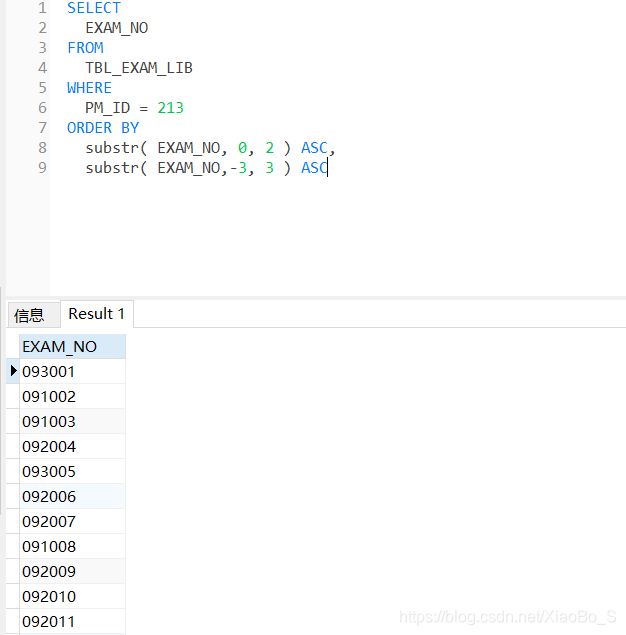
使用substr函数截取字符中的所需位数进行排序即可,如果排序的条件是多列一直往后追加即可,会按照在上一个条件的前提下对下一个条件排序
substr函数说明,substr(string string1,int a,int b)
第一个参数为要截取的的字符串,第二个参数为开始位置,第三个参数为截取后的长度
若第一个参数为负数则会从有向左截取,0或1表示自左向右第一位开始截取,大于1从指定为置开始截取,如下:
(1)select substr('1234567',0,3) value from dual;//返回结果 123
(2)select substr('1234567',1,3) value from dual;//返回结果 123
(3)select substr('1234567',2,3) value from dual;//返回结果 234
(4)select substr('1234567',-1,3) value from dual;//返回结果 7
(5)select substr('1234567',-2,3) value from dual;//返回结果 67
(6)select substr('1234567',-3,3) value from dual;//返回结果 567
(7)select substr('1234567',-4,3) value from dual;//返回结果 456
说明:虽然(6),(7)截取的都是3个字符,结果却不是3 个字符; 因为只要 |a| ≤ b,取a的个数(如:(4),(5));当 |a| ≥ b时,才取b的个数,由a决定截取位
3.另外如果你把代码写到mapping的xml文件里会报错,不识别substr,这是因为xml文件不支持这个字符关键字,需要修改为如下
ORDER BY
<![CDATA[ substr ]]>( t1.EXAM_NO, 0, 2 ) ASC,
<![CDATA[ substr ]]>( t1.EXAM_NO,- 3, 3) ASC