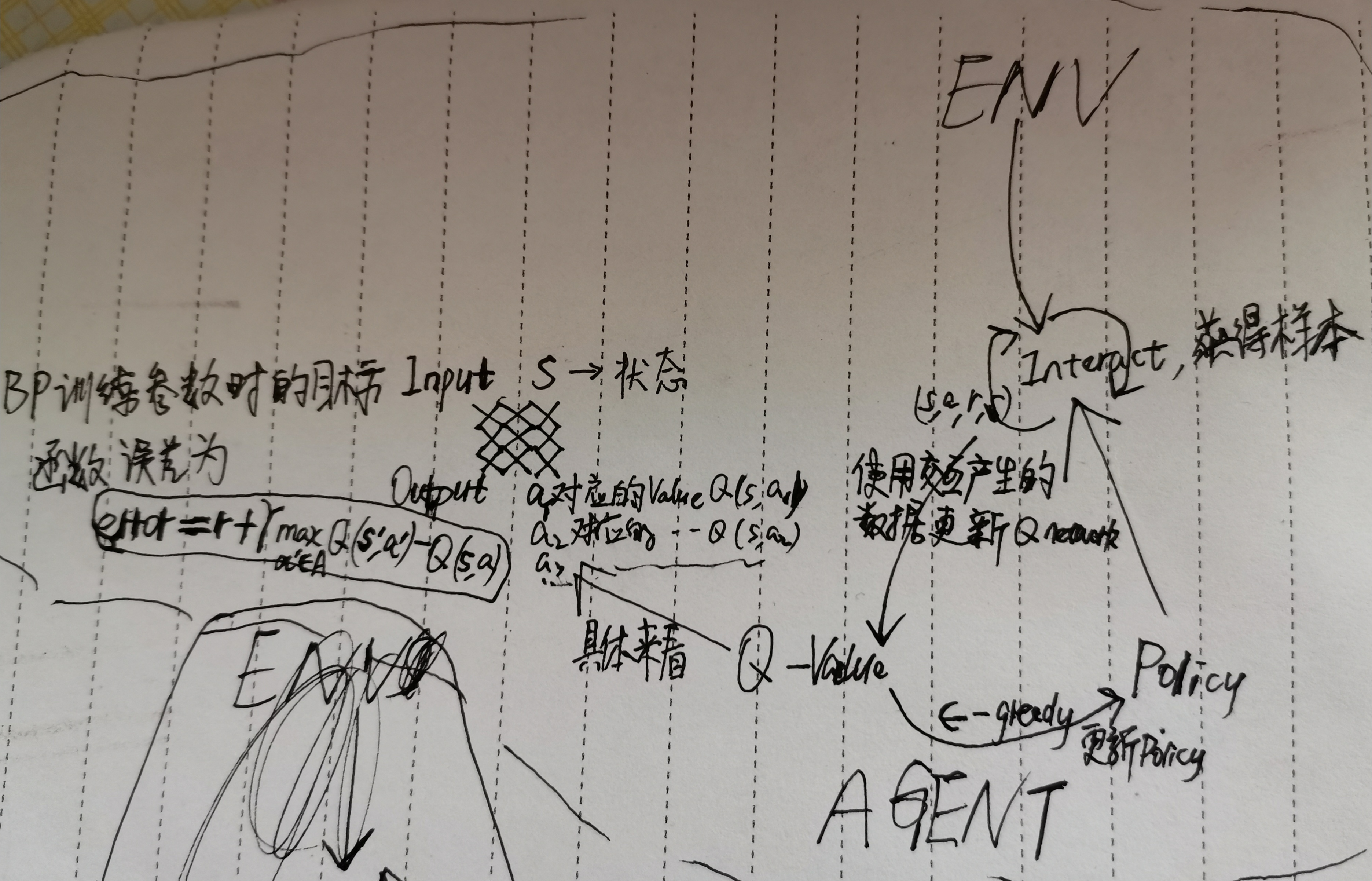
在传统RL算法中,依靠的是Policy和Value的协同迭代优化agent。
而现代,
DQN等value-based类算法弱化了Policy的存在,Policy成了Value的附属;
DDPG,PPO等policy-based类算法直接删掉了Value。agent只有Policy,只做一个从State到Action的映射。
DQN在干嘛?从(s,a)到Q(s,a)的映射
训练DQN的时候在训练的什么?Q(s,a;serta)的参数serta
DQN如何训练?
首先agent与env交互,采样,训练样本为(s,a,r,s'),存储在experience_replay里。
然后采用反向传播方法优化神经网络的参数serta。
误差为