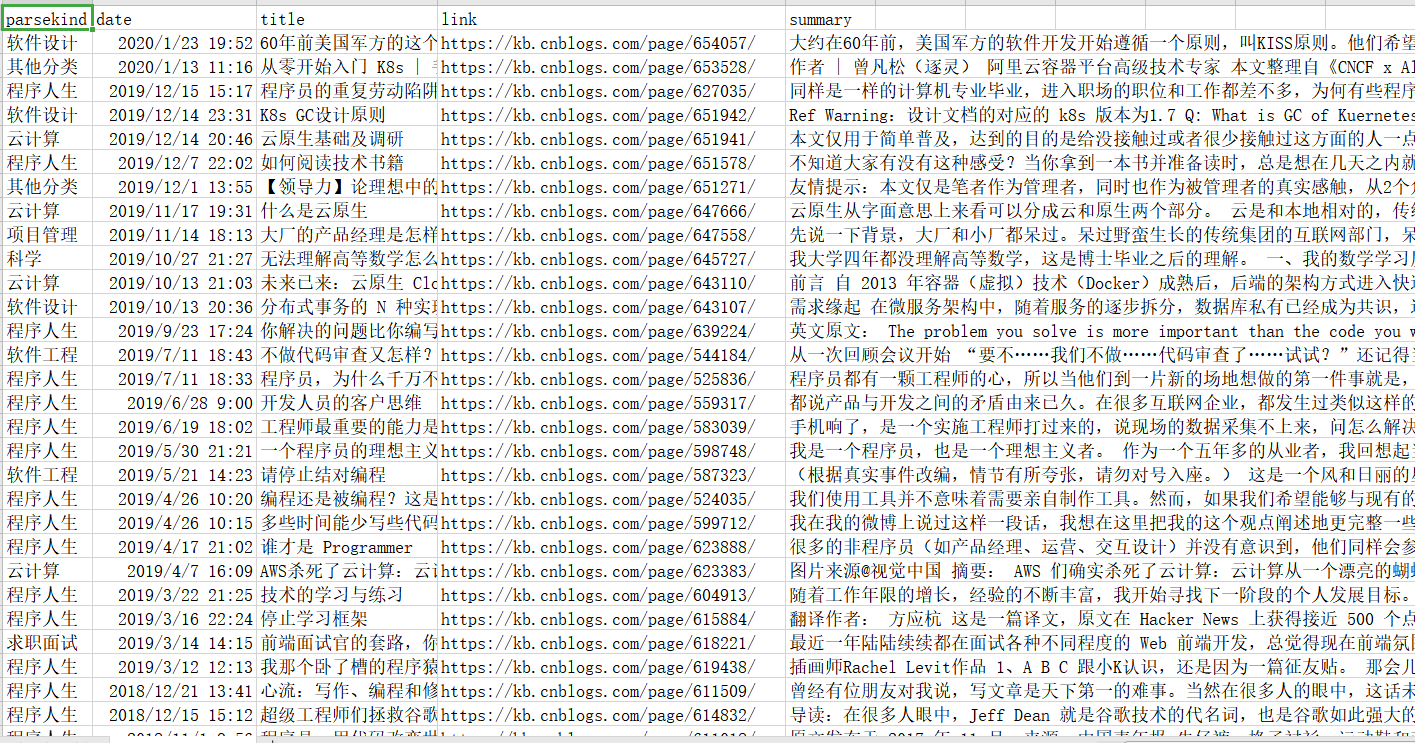
遇到的问题:
目标div块循环中,有其它杂div,如何排除?

解决方法:
for i in range(1, 40, 2): infos = selector.xpath('//*[@id="kb_list"]/div[{}]'.format(str(i))) for info in infos: ###
源代码:
import csv
import os
from lxml import etree
import requests
import time
#创建csv
outPath = 'D://hotwords_data.csv'
if (os.path.exists(outPath)):
os.remove(outPath)
fp = open(outPath, 'wt', newline='', encoding='utf-8')
writer = csv.writer(fp)
writer.writerow(('date', 'title', 'link','summary'))
# 加入请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36'
}
def get_info(url):
res = requests.get(url, headers=headers)
selector = etree.HTML(res.text)
for i in range(1, 40, 2):
infos = selector.xpath('//*[@id="kb_list"]/div[{}]'.format(str(i)))
for info in infos:
title = info.xpath('h2/a[@class="kb-title"]/text()')[0]
print(title)
link=info.xpath('h2/a[@class="kb-title"]/@href')[0]
parselink="https:"+link
#print(parselink)
summary=info.xpath('div[1]/text()')[0]
#print(summary)
date=info.xpath('div[2]/span[@class="green"]/text()')[0]
#print(date)
# 写入csv
writer.writerow((date, title, parselink,summary.strip()))
#程序主入口
if __name__ == '__main__':
urls = ['https://home.cnblogs.com/kb/page/{}/'.format(str(i)) for i in range(1,101)]
for url in urls:
print(url)
get_info(url)
time.sleep(2)
数据截图: