一、Spark介绍
Spark是一个生态系统,内核由Scala语言开发,为批处理(Spark Core)、交互式(Spark SQL)、流式处理(Spark Streaming)、机器学习(MLlib)、图计算(GraphX)提供了一个更快、更通用的统一的数据处理平台(One Stack rule them all),是类Hadoop MapReduce的通用并行框架。
Spark Core:基本引擎,提供内存计算框架、提供Cache机制支持数据共享和迭代计算,用于大规模并行和分布式数据处理
采用线程池模型减少Task启动开稍
采用容错的、高可伸缩性的Akka作为通讯框架
Spark SQL:支持SQL或者Hive查询语言来查询数据
Spark 被标榜为:“快如闪电的集群计算”
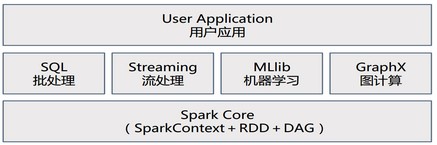
开源分布式计算系统
基于内存处理的大数据并行计算框架
数据处理的实时性,高容错性,高可伸缩性,负载均衡
统一的编程模型:高效支持整合批量处理和交互式流分析
Spark 生态系统名称:伯克利数据分析栈(BDAS)
关于官网对 Spark 的介绍:
Apache Spark is a fast and general-purpose cluster computing system. It provides high-level APIs in Java, Scala, Python and R, and an optimized engine that supports general execution graphs. It also supports a rich set of higher-level tools including Spark SQL for SQL and structured data processing, MLlib for machine learning, GraphX for graph processing, and Spark Streaming.
Apache Spark™ is a fast and general engine for large-scale data processing.
Speed:Run programs up to 100x faster than Hadoop MapReduce in memory, or 10x faster on disk.
Ease of Use:Write applications quickly in Java, Scala, Python, R.
Generality:Combine SQL, streaming, and complex analytics.
Runs Everywhere:Spark runs on Hadoop, Mesos, standalone, or in the cloud. It can access diverse data sources including HDFS, Cassandra, HBase, and S3.
Spark 最核心设计:
RDD:海量数据存储,内存或磁盘存储;
Spark 专用名词预热:
Application:Spark 应用程序,包含一个 Driver 程序和分布在集群中多个节点上运行的若干 Executor 代码
Operation:作用于 RDD 的各种操作分为 Transformation 和 Action
Job:作业,SparkContext 提交的具体 Action 操作,一个 Job 包含多个 RDD 及作用于相应 RDD 上的各种 Operation,常与Action对应
Stage:每个 Job 会被拆分很多组任务,每组任务被称为 Stage,也称TaskSet,即一个作业包含多个阶段
Partition:数据分区,一个 RDD 中的数据可以分成多个不同的区
DAG:Directed Acycle graph, 有向无环图,反映 RDD 之间的依赖关系
Caching Managenment:缓存管理,对 RDD 的中间计算结果进行缓存管理以加快整体的处理速度
Driver in Application —> Job(RDDs with Operations) —> Stage —> Task
RDD 相关术语:
batch interval:时间片或微批间隔,一个时间片的数据由 Spark Engine 封装成一个RDD实例
batch data:批数据,将实时流数据以时间片为单位分批
window length:窗口长度,必须是 batch interval 的整数倍
window slide interval:窗口滑动间隔,必须是 batch interval 的整数倍
关于 Spark 处理速度为什么比 (Hadoop)MapReduce 快?
MapReduce 中间结果在 HDFS 上,Spark 中间结果在内存,迭代运算效率高
MapReduce 排序耗时,Spark 可以避免不必要的排序开销
Spark 能够将要执行的一系列操作做成一张有向无环图(DAG),然后进行优化
此外,Spark 性能优势
采用事件驱动的类库 AKKA 启动任务,通过线程池来避免启动任务的开销
通用性更好,支持 map、reduce、filter、join 等算子
AKKA,分布式应用框架,JAVA虚拟机JVM平台上构建高并发、分布式和容错应用的工具包和运行时,由 Scala 编写的库,提供 Scala和JAVA 的开发接口。
并发处理方法基于Actor模型
唯一通信机制是消息传递
RDD
Resilient Distributed Dataset,弹性分布式数据集,RDD 是基于内存的、只读的、分区存储的可重算的元素集合,支持粗粒度转换(即:在大量记录上执行相同的单个操作)。RDD.class 是 Spark 进行数据分发和计算的基础抽象类,RDD 是 Spark 中的抽象数据结构类型,任何数据在 Spark 中都被表示为 RDD。
RDD是一等公民。Spark最核心的模块和类,Spark中的一切都是基于RDD的。
RDD 来源
并行化驱动程序中已存在的内存集合 或 引用一个外部存储系统已存在的数据集
通过转换操作来自于其他 RDD
此外,可以使 Spark 持久化一个 RDD 到内存中,使其在并行操作中被有效的重用,RDDs 也可以自动从节点故障中恢复(基于 Lineage 血缘继承关系)。
基于 RDD 的操作类型
Transformation(转换):具体指RDD中元素的映射和转换(RDD-to-RDD),常用操作有map、filter等
Action(动作):提交Spark作业,启动计算操作,并产生最终结果(向用户程序返回或者写入文件系统)
转换是延迟执行的,通过转换生成一个新的RDD时候并不会立即执行(只记录Lineage,不会加载数据),只有等到 Action 时,才触发操作(根据Lineage完成所有的转换)。
操作类型区别:返回结果为RDD的API是转换,返回结果不为RDD的API是动作。
常用算子清单

关于相关算子的初识:Spark RDD API 详解
依赖关系:窄依赖,父RDD的每个分区都只被子RDD的一个分区所使用;宽依赖,父RDD的分区被多个子RDD的分区所依赖。
窄依赖可以在某个计算节点上直接通过计算父RDD的某块数据得到子RDD对应的某块数据;
数据丢失时,窄依赖只需要重新计算丢失的那一块数据来恢复;
SparkConf
运行配置,一组 K-V 属性对。SparkConf 用于指定 Application 名称、master URL、任务相关参数、调优配置等。构建 SparkContext 时可以传入 Spark 相关配置,即以 SparkConf 为参实例化 SparkContext 对象。
SparkContext
运行上下文。Spark 集群的执行单位是 Application,提交的任何任务都会产生一个 Application,一个Application只会关联上一个Spark上下文。SparkContext 是 Spark 程序所有功能的唯一入口,类似 main() 函数。
关于共享变量
Spark 提供两种类型的共享变量(Shared varialbes),提升集群环境中的 Spark 程序运行效率。
广播变量:Broadcast Variables,Spark 向 Slave Nodes 进行广播,节点上的 RDD 操作可以快速访问 Broadcast Variables 值,而每台机器节点上缓存只读变量而不需要为各个任务发送该变量的拷贝;
累加变量:Accumulators,只有在使用相关操作时才会添加累加器(支持一个只能做加法的变量,如计数器和求和),可以很好地支持并行;
Spark Streaming
构建在 Spark 上的流数据处理框架组件,基于微批量的方式计算和处理实时的流数据,高效、高吞吐量、可容错、可扩展。
Spark Streaming is an extension of the core Spark API that enables scalable, high-throughput, fault-tolerant stream processing of live data streams,
which makes it easy to build scalable fault-tolerant streaming applications.
Ease of use:Build applications through high-level operators.
Fault Tolerance:Stateful exactly-once semantics out of the box.
Spark Integration:Combine streaming with batch and interactive queries.
基本原理是将输入数据流以时间片(秒级)为单位进行拆分成 micro batches,将 Spark 批处理编程模型应用到流用例中,然后以类似批处理的方式处理时间片数据。

图中的 Spark Engine 批处理引擎是 Spark Core。
Spark Streaming 提供一个高层次的抽象叫做离散流(Discretized Stream,DStream),代表持续的数据流(即一系列持续的RDDs)。DStream 中的每个 RDD 都是按一小段时间(Interval)分割开来的数据集,对 DStream 的任何操作都会转化成对底层 RDDs 的操作(将 Spark Streaming 中对 DStream 的操作变为针对 Spark 中 RDD 的操作)。
sc.foreachRDD { rdd =>
rdd.foreachPartition { partition =>
partition.foreach ( record =>
send(record)
)
}
}
Spark 的 StreamingContext 设置完毕后,启动执行:
sc.start() // 启动计算
sc.awaitTermination() // 等待计算完成
具体参考:Spark Streaming初探
此外,Spark Streaming 还支持窗口操作,具体地:
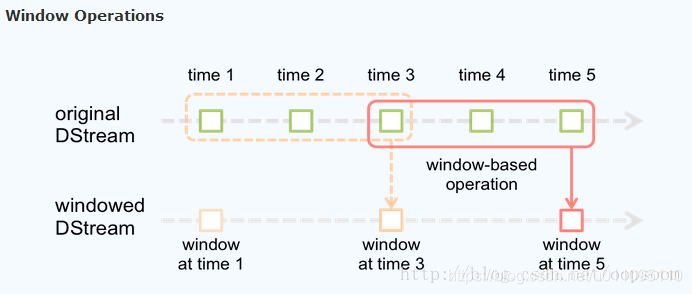
实际应用场景中,企业常用于从Kafka中接收数据做实时统计。
Spark SQL
Spark SQL 的前身是 Shark(Hive on Spark)。
结构化数据处理和查询、提供交互式分析,以 DataFrame(原名 SchemaRDD)形式。DataFrame 是一种以RDD为基础的分布式数据集,是带有 schema 元信息的RDD,即 DataFrame 所表示的二维表数据集的每一列都带有名称和类型。
Spark 容错机制
分布式数据集的容错性通过两种方式实现:设置数据检查点(Checkpoint Data) 和 记录数据的更新(Logging the Updates)。
Spark容错机制通过 Lineage(主) - CheckPoint(辅) 实现
Lineage:粗粒度的记录更新操作
Checkpoint:通过冗余数据缓存数据
RDD会维护创建RDDs的一系列转换记录的相关信息,即:Lineage(RDD的血缘关系),这是Spark高效容错机制的基础,用于恢复出错或丢失的分区。
RDD 之于 分区,文件 之于 文件块
若依赖关系链 Lineage 过长时,使用 Checkpoint 检查点机制,切断血缘关系、将数据持久化,避免容错成本过高。
Spark 调度机制
Spark 应用提交后经过一系列的转换,最后成为 Task 在每个节点上执行。相关概念理解:
Client:客户端(Driver端)进程,负责提交作业到Master。
Master:主控节点,负责接收Client提交的作业,管理Worker,并命令Worker启动分配Driver的资源和启动Executor的资源
Worker:集群中任何可以运行Application代码的节点,也可以看作是Slaver节点上的守护进程,负责管理本节点的资源,定期向Master汇报心跳,接收Master的命令,启动Driver和Executor,是Master和Executor之间的桥梁
Driver:用户侧逻辑处理,运行main()函数并创建SparkContext(准备Spark应用程序运行环境、负责与ClusterManager通信进行资源申请、任务分配和监控
Executor:Slaver节点上的后台执行进程,即真正执行作业的地方,并将将数据保存到内存或者磁盘。一个集群一般包含多个Executor,每个Executor接收Driver的命令Launch Task,一个Executor可以执行一到多个Task(每个Executor拥有一定数量的"slots",可以执行指派给它的Task)
Task:运行在Executor上的工作单元,每个Task占用父Executor的一个slot (core)
Cluster Manager:在集群上获取资源的外部服务,目前
Standalone:Spark原生的资源管理,由 Master 负责资源分配
Hadoop Yarn:由Yarn中的 ResourceManager 负责资源分配
Spark运行的基本流程如下图:
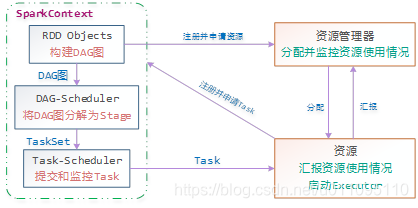
一个Spark作业运行时包括一个Driver进程,也是作业的主进程,负责作业的解析、生成Stage并调度Task到Executor上。包括:
DAGScheduler:实现将Spark作业分解成一到多个Stage,每个Stage根据RDD的Partition个数决定Task的个数,然后生成相应的TaskSet放到TaskScheduler中
TaskScheduler:维护所有的TaskSet,实现Task分配到Executor上执行并维护Task的运行状态
每一个 Spark 应用程序,都是由一个驱动程序组成,运行用户的 Main 函数,并且在一个集群上执行各种各样的并行操作:
所有的 Spark 应用程序都离不开 SparkContext 和 Executor 两部分,Executor 负责具体执行任务,运行 Executor 的机器称为 Worker 节点,SparkContext 由用户程序启动,通过资源调度模块和 Executor 通信。SparkContext 和 Executor 这两部分的核心代码实现在各种运行模式中都是公用的,在它们之上,根据运行部署模式的不同,包装了不同调度模块以及相关的适配代码。具体来说,以 SparkContext 为程序运行的总入口,在 SparkContext 的初始化过程中,Spark 会分别创建 DAGScheduler(作业调度)和 TaskScheduler(任务调度)两个调度模块。其中,作业调度模块是基于任务阶段的高层调度模块,它为每个 Spark 作业计算具有依赖关系的多个调度阶段 (通常根据 Shuffle 来划分),然后为每个阶段构建出一组具体的任务 (通常会考虑数据的本地性等),然后以 TaskSets(任务组) 的形式提交给任务调度模块来具体执行。而任务调度模块则负责具体启动任务、监控和汇报任务运行情况。
环境准备
-
三台Centos或虚拟机环境
-
Hadoop全分布式已安装
主要使用HDFS环境。Hadoop完全分布式安装 -
Scala安装
二、Scala安装
- Scala下载
进入到目标目录/hadoop,下载scala rpm安装包并安装
cd /hadoop/
wget https://downloads.lightbend.com/scala/2.12.7/scala-2.12.7.tgz
- Scala安装
rpm -ivh scala-2.12.7.tgz
- 配置环境变量
export SCALA_HOME=/usr/bin/scala
export PATH= PATH
vim /etc/profile
加入后执行source使环境变量生效
source /etc/profile
- 检查是否安装成功
[root@master hadoop]# scala -version
Scala code runner version 2.12.7 -- Copyright 2002-2018, LAMP/EPFL and Lightbend, Inc.
- Scala拷贝到另外两个Spark节点,并安装
scp -r /hadoop/scala-2.12.7 [email protected]:/hadoop
scp -r /hadoop/scala-2.12.7 [email protected]:/hadoop
三、Spark安装
1、选择spark版本
Hadoop本文安装的是2.9.1,所以,选择下载Spark2.4.0。Spark2.4.0适配于Hadoop2.7以后的版本。

2、下载spark
cd /hadoop
wget http://mirrors.hust.edu.cn/apache/spark/spark-2.4.0/spark-2.4.0-bin-hadoop2.7.tgz
3、修改配置文件
- 配置文件spark-env.sh和slaves修改
首先进入conf目录,将spark-env.sh.template变成spark-env.sh.
cd conf
cp spark-env.sh.template spark-env.sh
- spark-env.sh修改
vim spark-env.sh
加入内容
export JAVA_HOME=/usr/java/jdk1.8.0_181
export SCALA_HOME=/usr/bin/scala
export HADOOP_HOME=/hadoop/hadoop-2.9.0
export HADOOP_CONF_DIR=/hadoop/hadoop-2.9.0/etc/hadoop
export SPARK_MASTER_IP=172.16.16.15
export SPARK_MASTER_HOST=master.hadoop
export SPARK_LOCAL_IP=172.16.16.15
export SPARK_WORKER_MEMORY=1g
export SPARK_WORKER_CORES=2
export SPARK_HOME=/hadoop/spark-2.4.0-bin-hadoop2.7
export SPARK_DIST_CLASSPATH=$(/hadoop/hadoop-2.9.0/bin/hadoop classpath)
变量说明
- JAVA_HOME:Java安装目录
- SCALA_HOME:Scala安装目录
- HADOOP_HOME:hadoop安装目录
- SPARK_MASTER_HOST:spark master主节点hostname
- HADOOP_CONF_DIR:hadoop集群的配置文件的目录
- SPARK_MASTER_IP:spark集群的Master节点的ip地址
- SPARK_WORKER_MEMORY:每个worker节点能够最大分配给exectors的内存大小
- SPARK_WORKER_CORES:每个worker节点所占有的CPU核数目
- SPARK_WORKER_INSTANCES:每台机器上开启的worker节点的数目
- slave文件修改
vim slaves
加入worker两个节点的hostname,slave1.hadoop和slave2.hadoop是我两个从节点的hostname,可以通过hosts直接解析。配置hostname可以通过hostnamectl进行配置,dns解析可以通过vim /etc/hosts进行配置,具体见之前的Hadoop2.9.1全分布式安装
slave1.hadoop
slave2.hadoop
4、配置环境变量
vim /etc/profile
在最结尾加入
export SPARK_HOME=/hadoop/spark-2.4.0-bin-hadoop2.7
export PATH=$PATH:$SPARK_HOME/bin
使环境变量生效
source /etc/profile
- 拷贝spark到slave1和slave2从节点上
scp -r /hadoop/spark-2.4.0-bin-hadoop2.7 [email protected]:/hadoop
scp -r /hadoop/spark-2.4.0-bin-hadoop2.7 [email protected]:/hadoop
- 修改从节点slave1和slave2的spark-env.sh和环境变量
export JAVA_HOME=slave java home
#修改为slave的java home
export SPARK_LOCAL_IP=slave ip
在Slave1和Slave2上分别修改/etc/profile,增加Spark的配置,过程同Master一样。
在Slave1和Slave2修改$SPARK_HOME/conf/spark-env.sh,将export SPARK_LOCAL_IP=1改成Slave1和Slave2对应节点的IP。
5、启动Spark集群
- 在Master节点启动集群。
/hadoop/spark-2.4.0-bin-hadoop2.7/sbin/start-all.sh
[root@master sbin]# ./start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /hadoop/spark-2.4.0-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.master.Master-1-master.hadoop.out
slave1.hadoop: starting org.apache.spark.deploy.worker.Worker, logging to /hadoop/spark-2.4.0-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-slave1.hadoop.out
slave2.hadoop: starting org.apache.spark.deploy.worker.Worker, logging to /hadoop/spark-2.4.0-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-slave2.hadoop.out
可见其分别在设定的master节点启动部署了master程序,在slave节点部署了worker程序;
- 查看集群是否启动成功:
在Master节点查看
jps
Master在Hadoop的基础上新增了master进程:
13711 Master
Slave在Hadoop的基础上新增了:
12341 Worker
