框架问题
流水线
一个序列的数据处理组件称为一个数据流水线。刘世贤在机器学习系统中非常普遍,因为大量的数据操作和数据转化才能应用。
组件通常是异步运行。每个组件拉取大量的数据,然后进行处理,再将结果传输给两外一个仓库;一段时间之后,流水线中的下一个组件会拉取前面的数据,并给出自己的输出,以此类推。每个组件都很独立:组件和组件之间的链接只有数据仓库。这使得整个系统非常简单易懂(在数据流图的帮助下),不同团队可以专注于不同的组件上。如果某个组件发生故障,它的下游组件还能前面的最后一个输出继续正常的运行(至少一段时间),所以使得整体架构鲁棒性较强。
下面给出的图是以房价预测为例给出的一个架构图

性能指标
1. 均方根误差(RMSE)
假如RMSE等于50000就意味着系统的预测值中约68%落在50000之内,约95%落在100000之内(正态分布 “68-95-99.7”规则:大约68%的值落在 内,95%落在 内,99.7%落在 内)
公式说明:
- 是数据集中第 个实例的所有特征值的向量(标签特征除外), 是标签(也就是我们期待的该实例的输出值)
例如,如果数据集的第一个区域位于经度-118.29,纬度33.91,居民数量为1416,平均收入为38372美元,房价中位数为156400美元,那么
并且,
- 是数据集中所有实例的所有特征值的矩阵(标记特征除外)。每一行为一个实例,也就是说地 行等于 的转置矩阵,记做
例如,刚刚描述的第一个区域,矩阵 即为如下所示:
2.平均绝对误差
注意:距离或者范数的测度可能有多种:
- 计算平方和的根(RMSE)对应欧几里得范数,也称之为 范数,记做
- 计算绝对值的总和(MAE)对应 范数,,记做 ,有时也称为曼哈顿距离
- 跟笼统的说,包含 个元素的向量 的范数可以定义为,记做 , 仅仅给出了向量的基数, 而给出了向量中的最大绝对值
- 范数指数越高,则越关注大的值,忽略小的值。这就是为什么RMSE比MAE对异常值更敏感。但是当异常值非常稀少时,RMSE的表现优异,通常作为首选。
下载数据
import os
import tarfile
from six.moves import urllib
DOWNLOAD_ROOT = "hattp://raw.githubusercontent.com/ageron/handson-ml/master"
HOUSING_PATH = "./DATAS/housing"
HOUSING_URL = DOWNLOAD_ROOT + HOUSING_PATH + "/housing.tgz"
def fetch_housing_data(housing_url=HOUSING_URL, housing_path=HOUSING_PATH):
if not os.path.isdir(housing_path):
os.makedirs(housing_path)
tgz_path = os.path.join(housing_path, "housing.tgz")
urllib.request.urlretrieve(housing_url, tgz_path)
housing_tgz = tarfile.open(tgz_path)
housing_tgz.extractall(path=housing_path)
housing_tgz.close()
现在,每当你调用 fetch_housing_data( ) 时,会自动在工作区中创建一个DATAS/housing目录,然后下载housing.tgz文件,并将housing.csv解压到这个目录。
快速查看数据结构
import pandas as pd
def load_housing_data(housing_path=HOUSING_PATH):
csv_path = os.path.join(housing_path, "housing.csv")
return pd.read_csv(csv_path)
这个函数会返回一个包含所有数据的Pandas DataFrame对象。
我们来看看使用DatasFrames的 head( ) 方法之后的前几行的情况。
housing = load_housing_data()
housing.head()

每一行代表了一个区,总共有10个属性, 分别为:
longitude, latitude, housing_median_age, total_rooms, total_bedrooms,
population, households, median_income, median_house_value, ocean_proximity
通过 info( ) 方法可以快速获取数据集的简单描述,特别是总行数、每个属性的类型和非控制的数量。
housing.info()
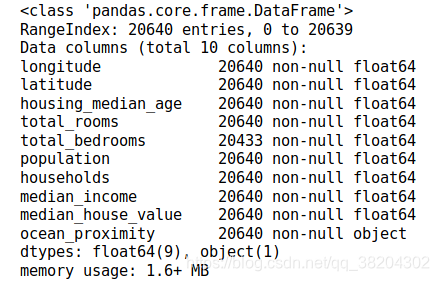
数据集中包含20640个实例,需要注意的是,total_bedrooms这个属性只有20433个非空值,这意味着有207个区域却是这个特征。
从上面的输出结果可以看出,有些列的值是重复的,这意味着它有可能是同属一个分类属性。我们可以通过 value_counts( ) 方法查看有多少种分类存在,每种类别下分别有多少个区域:
housing["ocean_proximity"].value_counts()

再看看其他的区域,可以通过 describe( ) 方法显示数值属性的摘要。
housing.describe()
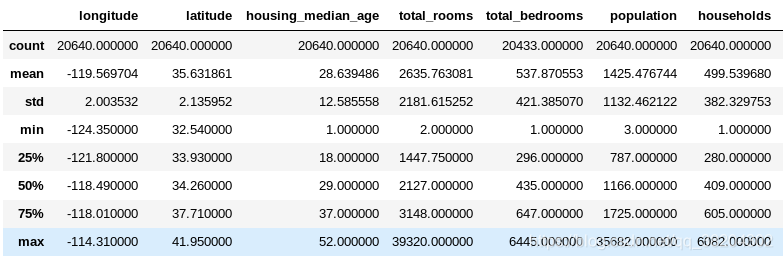 其中各部分值相应的意思都很清楚,这里解释一下25%,50%和75%.这三行显示相应的百分数:百分位数表示一组观测值中给定百分比的观测值都低于该值。例如,对于housing_median_age的值,25%的区域低于18,50%的区域低于29,以及75%的区域低于37.
其中各部分值相应的意思都很清楚,这里解释一下25%,50%和75%.这三行显示相应的百分数:百分位数表示一组观测值中给定百分比的观测值都低于该值。例如,对于housing_median_age的值,25%的区域低于18,50%的区域低于29,以及75%的区域低于37.
另一种快速了解数据类型的方法是绘制每个数值属性的直方图。直方图用来显示给定值范围(横轴)的实例数量(纵轴)。代码实现如下:
%matplotlib inline
import matplotlib.pyplot as plt
housing.hist(bins=50, figsize=(20,15))
plt.show()
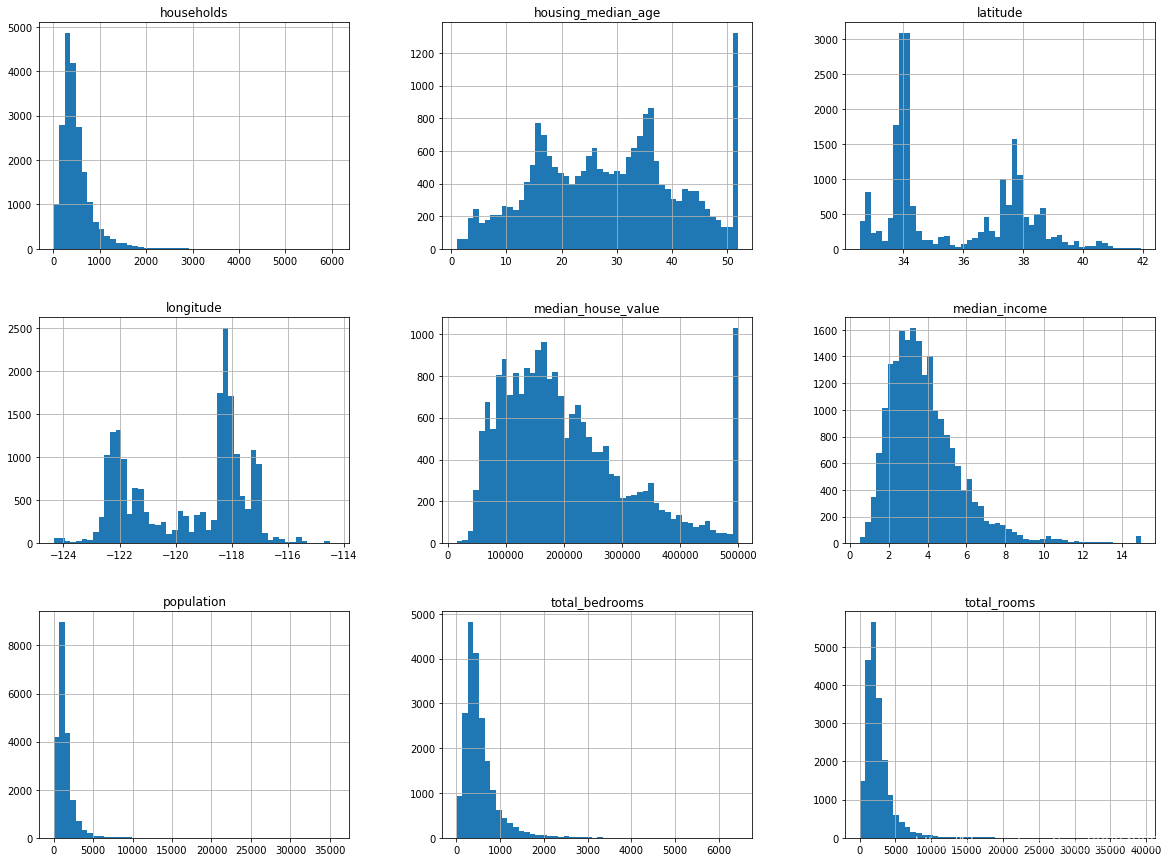 从直方图可以看出几点我们需要注意的地方:
从直方图可以看出几点我们需要注意的地方:
- 这些属性被缩放的程度各不相同,在文章的后面,我们对特征的缩放做出讨论。
- 许多直方图都表现出重尾的情况:图形在中位数右侧的延伸比左侧要远得多。这可能会导致某些机器学习算法难以检查模式。稍后会继续讨论一些对应的转化方法,将这些属性转化为更偏向钟形的分布。
创建测试集
理论上,创建测试集非常简单:只需要随机选择一些实例,通常是数的20%,然后将它们放在一边。代码实现如下:
import numpy as np
def split_train_test(data, test_ratio):
shuffled_indices = np.random.permutation(len(data))
test_set_size = int(len(data * test_ratio))
test_indices = shuffled_indices[:test_set_size]
train_indices = shuffled_indices[test_set_size:]
return data.iloc[train_indices], data.iloc[test_indices]
这个片段的代码确实能行,但是却并不完美,每运行一次就会产生一个不同的数据集。解决方案之一是在第一次运行程序后保存测试集,随后的运行只是加载它而已。另一种方法是调用 np.random.permutation( ) 之前设置一个随机数生成的种子,例如,np.random.seed(42),从而让它始终生成相同的随机索引。
但是,这两种解决方案在下一次获取更新的数据时都会中断。常见的解决办法是每个实例都用一个标识符来决定是否进入测试集。举例来说,可以计算每个实例标识符的hash值,只取hash值的最后一个字节,如果该值小于等于51(约为256的20%),则将该实例加入测试集中。这样可以确保测试集在多个运行里都是一致。实现方式如下:
import hashlib
def test_set_check(identifier, test_ratio, hash):
return hash(np.int64(identifier)).digest()[-1] < 256 * test_ratio
def split_train_test_by_id(data, test_ratio, id_column, hash=hashlib.md5):
ids = data[id_column]
in_test_set = ids.apply(lambda id_: test_set_check(id_, test_ratio, hash))
return data.loc[~in_test_set], data.loc[in_test_set]
不幸的是,housing数据集没有标识符列,最简单的解决办法是使用行索引作为ID.如果使用行索引作为唯一标识符,便需要确保在数据集的末尾添加新数据,并不会删除任何的行。如果不能保证,那则需要使用其他的稳定特征来创建唯一标识符。
例如,这里我们取一个地区的经纬度组合形成ID:
housing_with_id = housing.reset_index() # add an index column
housing_with_id["id"] = housing["longitude"] * 1000 + housing["latitude"]
train_set, test_set = split_train_test_by_id(housing_with_id, 0.2, "id")
Scikit-Learn提供了一些函数,可以通过多种方式将数据集分成多个子集,最简单的函数是 train_test_split . 首先,它也有 random_state 参数,让你可以像上面我们自定义的函数实现一样设置随机生成种子。其次,可以把行数相同的多个数据集一次性发送给它,它会根据相同的索引将其拆分:
from sklearn.model_selection import train_test_split
train_set, test_set = train_test_split(housing, test_size=0.2, random_state=42)
当数据集足够大时,纯随机采样是完全可以的。但是,当数据集并不是很大时,这样的采样便会产生明显的误差。这里,我们引入分层抽样的方法。
下面的代码是这样创建收入类别的属性:将收入中位数除以1.5(限制收入类别的数量),然后使用 ceil 进行取整(得到离散类别),最后将所有大于5的类别合并为类别5:
housing["income_cat"] = np.ceil(housing["median_income"] / 1.5)
housing["income_cat"].where(housing["income_cat"] < 5, 5.0, inplace=True)
现在,就可以根据收入类别进行分层抽样了。
from sklearn.model_selection import StratifiedShuffleSplit
split = StratifiedShuffleSplit(n_splits=1, test_size=0.2, random_state=42)
for train_index, test_index in split.split(housing, housing["income_cat"]):
start_train_set = housing.loc[train_index]
start_test_set = housing.loc[test_index]
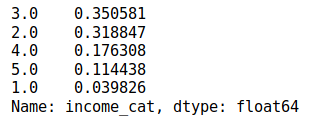
housing["income_cat"].value_counts() / len(housing)
我们可以看到所有住房数据根据收入类别的比例分布为:
采样完成后,我们就可以删除 income_cat属性:
for set in (start_train_set, start_test_set):
set.drop(["income_cat"], axis=1, inplace=True)
