1.什么样的数据需要删除
- 很多条数据,删除这个无所谓
- 这一列的数据缺失的太多导致,没有办法使用
- 比如邮编等不可填充
2.pandas常用的数据删除处理的方法
删除
//删除行
df.dropna(axis=0)
//删除列
df.dropna(axis=1)
简单填充
//用前面的填充
df.fillna(method='pad')
//用用后边的填充
df.fillna(method='bfill')
复杂填充
df.interpolate()
除此之外,interpolate()方法还有 linear, time, index, values, nearest, zero, slinear, quadratic, cubic, barycentric, krogh, polynomial, spline, piecewise_polynomial, from_derivatives, pchip, akima 等插值方法可供选择。
- 如果你的数据增长速率越来越快,可以选择
method='quadratic'二次插值。 - 如果数据集呈现出累计分布的样子,推荐选择
method='pchip'。 - 如果需要填补缺省值,以平滑绘图为目标,推荐选择
method='akima'。 - 另外,
method='akima',method='barycentric'和method='pchip'需要 Scipy 才能使用。
3.独热填充
某种参数的特征是0,1 ,2这样的离散分布,可以采用独热填充
onehot = pd.get_dummies(df[['status', 'color']])
onehot
3.重复数据
pandas.DataFrame.duplicated() 可以用来标识重复数据,数据集中重复数据行会返回布尔类型 True
pd.DataFrame.duplicated(df)
pd.DataFrame.drop_duplicates(df)
pandas.DataFrame.drop_duplicates() 可以返回一个去重后的数据集。
4.重复数据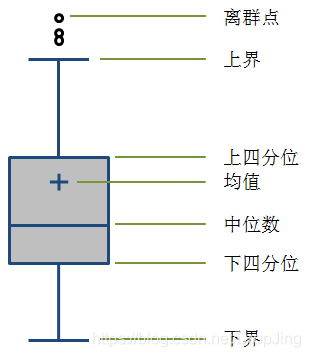
from matplotlib import pyplot as plt
%matplotlib inline
data = pd.read_csv("test_file.csv", header=0)
total_population = data["Total Population"]
plt.boxplot(total_population)
P = plt.boxplot(total_population)
outlier = P['fliers'][0].get_ydata()
outlier
5.读取文件实践
# -*- coding: utf-8 -*-
import json
import pandas as pd
def analysis(file, user_id):
times = 0
minutes = 0
# 读取 JSON 文件
with open(file, 'r') as ori_file:
# 读取 JSON 编码格式的数据
ori_json = json.load(ori_file)
# 将 JSON 数据转换为 DataFrame
df = pd.DataFrame(ori_json)
# 使用 Pandas 选择相应用户的数据
df_user = df[df['user_id'] == user_id]
# 统计该用户的总学习次数和总学习时间
times = len(df_user)
minutes = df_user['minutes'].sum()
return times, minutes
6.用四分点寻找异常值
# -*- coding: utf-8 -*-
import numpy as np
def find_outlier(data):
outlier = []
data_array = np.array(data)
# 使用 numpy 提供的 percentile 方法计算百分位数
Q1 = np.percentile(data_array, 25) # 上四分位
Q3 = np.percentile(data_array, 75) # 下四分位
# 计算 IQR 值
IQR = Q3 - Q1
outlier1 = Q1 - 1.5 * IQR
outlier2 = Q3 + 1.5 * IQR
# 确定异常值
for i in data:
if i < outlier1 or i > outlier2:
outlier.append(i)
return outlier
