【知识点】
1、时间模块:
(1)时间戳时间,格林威治时间,float数据类型
英国伦敦的时间:1970.1.1 0:0:0
北京时间:1970.1.1 8:0:0
(2)结构化时间,时间对象
时间对象 能够通过.属性名来获取对象中的值
(3)格式化时间,字符串时间,str数据类型
可以根据你需要的格式来显示时间
1 import time 2 3 # 1.时间戳时间 格林威治时间,float数据类型(给机器用的) 4 print(time.time()) 5 6 # 2.格式化时间 7 print(time.strftime('%Y-%m-%d')) # Y——2020,y——20(2020年) 8 print(time.strftime('%Y-%m-%d %H:%M:%S %A')) # 2020-02-20 20:05:51 Thursday 9 print(time.strftime('%c')) # Thu Feb 20 20:06:57 2020 10 11 # 3.结构化时间 12 time_obj=time.localtime() 13 print(time_obj) 14 print(time_obj.tm_year) # 2020(年) 15 print(time_obj.tm_mday) # 20(日)
(4)几种时间格式之间的转换
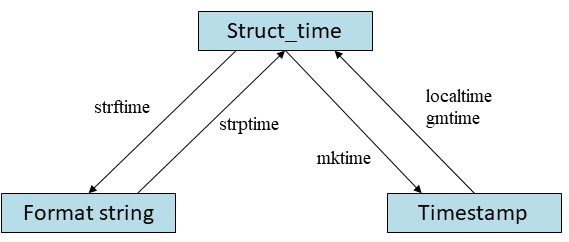
1 # 几种时间格式之间的转换 2 import time 3 4 print(time.localtime(15000000000)) 5 # time.struct_time(tm_year=2445, tm_mon=5, tm_mday=1, tm_hour=10, tm_min=40, \ 6 # tm_sec=0, tm_wday=0, tm_yday=121, tm_isdst=0) 7 8 # Timestamp ——> Struct_time ——> Format string 9 time_obj=time.localtime(15000000000) 10 format_time=time.strftime('%Y-%m-%d %H:%M:%S %A',time_obj) 11 print(format_time) # 2445-05-01 10:40:00 Monday 12 13 # Format string ——> Struct_time ——> Timestamp 14 s='2008-8-8' 15 struct_time=time.strptime(s,'%Y-%m-%d') 16 print(struct_time) # 结构化时间 17 print(time.mktime(struct_time)) # 1218124800.0
练习题:计算本月一号的时间戳时间
1 import time 2 3 ret=time.strftime('%Y-%m-1') 4 struct_time=time.strptime(ret,'%Y-%m-%d') 5 print(time.mktime(struct_time)) # 1580486400.0
2、sys模块
(1)sys.path
(2)sys.modules
(3)sys.exit()——结束处理
(4)sys.argv
1 import sys 2 3 # 程序启动时,在后面输入用户名,密码,通过sys.argv索取 4 name=sys.argv[1] 5 pwd=sys.argv[2] 6 7 if name == 'alex' and pwd == '123': 8 print('执行代码了') 9 else: 10 exit()
3、os模块
(1)创建文件夹:os.mkdir('文件名') os.mkdirs(‘文件名1/文件名2/文件名3’,exist_ok=True) 有这个文件名就跳过,没有就创建,不报错。
(2)删除文件夹
os.rmdir(‘文件名1/文件名2/文件名3’) 不能删除一个非空文件夹
os.removedirs(‘文件名1/文件名2/文件名3’) 递归向上删除文件夹,只要删除当前目录之后,发现上一级目录也为空,就把上一级目录也删掉,如果发现上一级目录有其他文件夹,就停止。
(3)os.listdir() 查看某个路径下的文件夹,返回一个列表
(4)os.sep 当前你所在的操作系统的目录分隔符
(5)os.linesep 输出当前平台使用的行终止符,win下为"\r\n",linux系统下为"\n"
(6)os.pathsep 输出用于分割文件路径的字符串,win下为";",linux系统下为":"
(7)os.name 输出字符串指示当前使用平台,win—>:‘nt’,Linux—>'posix'
(8)os.system("bash command") 运行shell命令,直接显示
(9)os.popen("bash command") .read() 运行shell命令,获取执行结果(查看当前路径 查看某些信息)
(10)os.path.abspath(path) 返回path规范化的绝对路径,os.path.split(path) 将path分割成目录和文件名二元组返回。
(11)os.path.dirname(path) 返回path目录,第一个元素。 os.path.basename(path) 返回path的文件名。
(12)os.path.exists(path) 如果path存在返回True,否则返回False
(13)os.path.isfile(path) 如果path是一个存在的文件,返回True,否则返回False
(14)os.path.isdir(path) 如果path是一个存在的目录,返回True,否则返回False
(15)os.path.join(path,srt1,str2) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
1 import os 2 3 ret=os.path.join('D:\wendang\PyCharmCode\MyPycharm\day27 sys os模块','aaa','bbb') 4 print(os.path.abspath(ret)) 5 # D:\wendang\PyCharmCode\MyPycharm\day27 sys os模块\aaa\bbb
(16)os.path.getsize(path) 返回path的大小
4、序列化模块
为什么要序列化?
A、要把内容写入文件 序列化
B、网络传输数据 序列化
(1)json模块:
能处理数据类型:有限,限制比较多——数字,字典,字符串,列表
能使用的语言:所有语言
方法:dump\load (序列化与反序列化) dumps/loads(直接接触内存)
1 import json 2 3 dic={'sss':'aaa','ccc':'qqq'} 4 str_dic=json.dumps(dic) 5 6 # print(dic) 7 # print(str_dic,type(str_dic)) 8 9 with open('json_dump3','w') as f: 10 json.dump(dic,f) # 写入 11 12 with open('json_dump3') as f2: 13 print(json.load(f2)) # 读取 14 15 ret=json.loads(str_dic) 16 print(ret,type(ret))
① json格式限制1:json格式的key必须是字符串数据类型,如果是数字为key,那么dump之后会强行转成字符串数据类型。
1 import json 2 3 # json格式的限制1,json格式的key必须是字符串数据类型 4 dic={1:2,3:4} 5 str_dic=json.dumps(dic) 6 print(str_dic) # {"1": 2, "3": 4} 7 new_dic=json.loads(str_dic) 8 print(new_dic) # {'1': 2, '3': 4}
json支持元组做value,对元组做value的字典会把元组强制转换成列表(json不支持元组做key)
1 import json 2 3 dic={'abc':(1,2,3)} 4 str_dic=json.dumps(dic) 5 print(str_dic) # {"abc": [1, 2, 3]} 6 new_dic=json.loads(str_dic) 7 print(new_dic) # {'abc': [1, 2, 3]}
②json格式限制2:json格式中的字符串只能是" "(双引号)
③dump限制的问题:
# 能不能多次dump数据到文件里? 可以多次dump但是不能load出来
# 想要dump多个数据进入文件,用dumps
1 # 想dump多个数据进入文件,用dumps 2 import json 3 4 dic={'abc':(1,2,3)} 5 lst=['aaa',123,'bbb',23.453] 6 7 with open('json_dump3','w') as f: 8 str_dic=json.dumps(dic) 9 str_lst=json.dumps(lst) 10 f.write(str_dic+'\n') 11 f.write(str_lst+'\n') 12 13 with open('json_dump3','r') as f1: 14 for line in f1: 15 ret=json.loads(line) 16 print(ret) #{'abc': [1, 2, 3]} ['aaa', 123, 'bbb', 23.453]
# 中文格式问题(ensure_ascii=False)
1 import json 2 3 dic={'abc':(1,2,3),'country':'中国'} 4 ret=json.dumps(dic) 5 6 print(ret) # {"abc": [1, 2, 3], "country": "\u4e2d\u56fd"} 7 8 new_dic=json.loads(ret) 9 print(new_dic) # {'abc': [1, 2, 3], 'country': '中国'} 10 11 ret=json.dumps(dic,ensure_ascii=False) 12 print(ret) # {"abc": [1, 2, 3], "country": "中国"}
④ json的其他参数:是为了用户看的方便,但是会相对浪费存储空间
1 # json其他参数 2 import json 3 4 data={'username':['李华','二愣子'],'sex':'male','age':16} 5 # indent为缩进 separators分隔符 6 json_dic2=json.dumps(data,sort_keys=True,indent=4,separators=(',',':'),ensure_ascii=False) 7 print(json_dic2) 8 # { 9 # "age":16, 10 # "sex":"male", 11 # "username":[ 12 # "李华", 13 # "二愣子" 14 # ] 15 # }
(2)pickle模块
① pickle支持的dumps和loads
1 import pickle 2 3 dic={1:{12,3,5},('a','b'):4} 4 5 pic_dic=pickle.dumps(dic) 6 print(pic_dic) # bytes类型 7 8 new_dic=pickle.loads(pic_dic) 9 print(new_dic) # {1: {3, 12, 5}, ('a', 'b'): 4}原封不动
② pickle支持几乎所有对象的
1 # pickle支持几乎所有对象的 2 import pickle 3 4 class Student: 5 def __init__(self,name,age): 6 self.name=name 7 self.age=age 8 9 alex=Student('alex',32) 10 # print(pickle.dumps(alex)) # bytes类型 11 ret=pickle.dumps(alex) 12 小华=pickle.loads(ret) 13 print(小华.name) # alex
③ 对于对象的序列化需要这个对象对应的类在内存中
【注意】dump用的f文件句柄需要以“wb”的形式打开,load所用的f是“r'b”形式打开
④ 文件中dump多个值,怎么取出来?
1 # 文件中dump多个值,怎么取出来? 2 import pickle 3 4 # 写入 5 # with open('pickle_dump','wb') as f: 6 # pickle.dump({'k1': 'v1'}, f) 7 # pickle.dump({'k2': 'v2'}, f) 8 # pickle.dump({'k3': 'v3'}, f) 9 # pickle.dump({'k4': 'v4'}, f) 10 # pickle.dump({'k5': 'v5'}, f) 11 # pickle.dump({'k6': 'v6'}, f) 12 13 # 读出 14 with open('pickle_dump','rb') as f: 15 while True: 16 try: 17 print(pickle.load(f)) # 依次打印出 18 except EOFError: 19 break
(3)shelve模块(不建议使用)
只有一个open功能
1 import shelve 2 3 # 写入 4 # f=shelve.open('shelve_demo') 5 # f['key']={'k1':(1,2,3),'k2':'v2'} 6 # f.close() 7 8 # 读出 9 f=shelve.open('shelve_demo') 10 content=f['key'] 11 f.close() 12 print(content) # {'k1': (1, 2, 3), 'k2': 'v2'}
shelve的适用场景:
如果你写定一个文件,改动比较少,读文件的操作比较多,而且你大部分的读取都基于某个key获得某个value
时间:2020-02-21 19:35:09