我这边已经创建好一个名为scrapy_pipeline的项目了。
然后创建一个爬虫为douban:项目目录如下:
爬取豆瓣网需要伪装浏览器,修改settings.py文件的内容:
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'scrapy_pipeline (+http://www.yourdomain.com)'
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3493.3 Safari/537.36'
douban.py 代码:
# -*- coding: utf-8 -*-
import scrapy
class DoubanSpider(scrapy.Spider):
name = 'douban'
allowed_domains = ['douban.com']
start_urls = ['https://movie.douban.com/top250']
def parse(self, response):
item_list = response.xpath('//*[@id="content"]/div/div[1]/ol//li/div')
f = open('douban.txt', 'a+', encoding='utf-8')
for item in item_list:
href = item.xpath('.//a/@href').extract_first()
name = item.xpath('.//a/span[@class="title"]/text()').extract_first()
print(name, href)
f.write(name)
f.write(href+'\n')
使用命令抓取保存的内容
douban.txt里:
这样写代码也不是不行,但是代码量一旦多了,加上数据库的那些操作就会显得杂乱,这样就很不好了。但是使用pipeline就可以进行解耦。
首先编写pipelines.py的代码:
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
from scrapy_pipeline.settings import MY_FILE
from scrapy.exceptions import DropItem
"""
源码内容:
1. 判断当前MyPipeline类中是否有from_crawler
有:
obj = MyPipeline.from_crawler(....)
否:
obj = MyPipeline()
2. obj.open_spider()
3. obj.process_item()/obj.process_item()/obj.process_item()/obj.process_item()/obj.process_item()
4. obj.close_spider()
"""
class MyPipeline(object):
def __init__(self, path):
self.f = None
self.path = path
@classmethod
def from_crawler(cls, crawler):
"""
初始化时,用于创建pipeline对象
:param crawler:
:return:
"""
print('my.........test')
path = crawler.settings.get('MY_FILE')
return cls(path)
# 可以在这里面打开文件操作,避免重复操作
def open_spider(self, spider):
"""
爬虫开始时调用
:param spider:
:return:
"""
# self.f = open('name.txt', 'a+', encoding='utf-8') # 这个不好,文件太固定
# self.f = open(MY_FILE, 'a+', encoding='utf-8') # 只是自定义settings
print('my.............start')
self.f = open(self.path, 'a+', encoding='utf-8')
然后有关持久化的都可以放在pipelines里面。open_spider可以进行数据库操作开始前准备工作,process_item进行数据库操作之类的,close_spider进行结束操作的方法。这里面就可以进行分工合作了。
然后我的douban.py:
# -*- coding: utf-8 -*-
import scrapy
from scrapy_pipeline.items import ScrapyPipelineItem
class DoubanSpider(scrapy.Spider):
name = 'douban'
allowed_domains = ['douban.com']
start_urls = ['https://movie.douban.com/top250']
def parse(self, response):
item_list = response.xpath('//*[@id="content"]/div/div[1]/ol//li/div')
for item in item_list:
href = item.xpath('.//a/@href').extract_first()
name = item.xpath('.//a/span[@class="title"]/text()').extract_first()
print(name, href)
# 这里每yield一次就调用一次pipeline
yield ScrapyPipelineItem(name=name, href=href)
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class ScrapyPipelineItem(scrapy.Item):
# define the fields for your item here like:
# 添加要写入的东东
name = scrapy.Field()
href = scrapy.Field()
settings.py中添加:
ITEM_PIPELINES = {
# 'scrapy_pipeline.pipelines.ScrapyPipelinePipeline': 300,
'scrapy_pipeline.pipelines.MyPipeline': 666,
}
# 保存的文件
MY_FILE = 'test.txt'
然后就可以进行爬取了
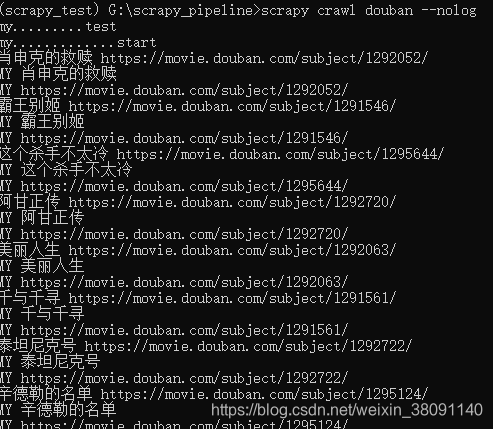
不止可以设置一个pipeline,还可以设置多个pipeline
pipelines.py:
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
from scrapy_pipeline.settings import MY_FILE
from scrapy.exceptions import DropItem
"""
源码内容:
1. 判断当前MyPipeline类中是否有from_crawler
有:
obj = MyPipeline.from_crawler(....)
否:
obj = MyPipeline()
2. obj.open_spider()
3. obj.process_item()/obj.process_item()/obj.process_item()/obj.process_item()/obj.process_item()
4. obj.close_spider()
"""
class MyPipeline(object):
def __init__(self, path):
self.f = None
self.path = path
@classmethod
def from_crawler(cls, crawler):
"""
初始化时,用于创建pipeline对象
:param crawler:
:return:
"""
print('my.........test')
path = crawler.settings.get('MY_FILE')
return cls(path)
# 可以在这里面打开文件操作,避免重复操作
def open_spider(self, spider):
"""
爬虫开始时调用
:param spider:
:return:
"""
# self.f = open('name.txt', 'a+', encoding='utf-8') # 这个不好,文件太固定
# self.f = open(MY_FILE, 'a+', encoding='utf-8') # 只是自定义settings
print('my.............start')
self.f = open(self.path, 'a+', encoding='utf-8')
def process_item(self, item, spider):
"""
这个方法在爬虫进行时调用
:param item:
:param spider:
:return:
"""
print('MY', item['name'])
print('MY', item['href'])
# 写文件操作
self.f.write(item['name'])
self.f.write(item['href'] + '\n')
return item # 交给下一个pipeline的proce_item方法
# raise DropItem # 后续的pipeline的process_item方法不再执行
# 可以在这里关闭文件操作,一次执行
def close_spider(self, spider):
"""
爬虫结束时调用
:param spider:
:return:
"""
print('my.......stop ')
self.f.close()
class DbPipeline(object):
def __init__(self, path):
self.f = None
self.path = path
@classmethod
def from_crawler(cls, crawler):
"""
初始化时,用于创建pipeline对象
:param crawler:
:return:
"""
print('DB.........test')
path = crawler.settings.get('DB_FILE')
return cls(path)
# 可以在这里面打开文件操作,避免重复操作
def open_spider(self, spider):
"""
爬虫开始时调用
:param spider:
:return:
"""
# self.f = open('name.txt', 'a+', encoding='utf-8') # 这个不好,文件太固定
# self.f = open(MY_FILE, 'a+', encoding='utf-8') # 只是自定义settings
print('DB...start')
def process_item(self, item, spider):
print('db', item)
print('db', item)
return item
# 可以在这里关闭文件操作,一次执行
def close_spider(self, spider):
"""
爬虫结束时调用
:param spider:
:return:
"""
print('db............stop')
settings.py中也添加:
ITEM_PIPELINES = {
# 'scrapy_pipeline.pipelines.ScrapyPipelinePipeline': 300,
'scrapy_pipeline.pipelines.MyPipeline': 666,
'scrapy_pipeline.pipelines.DbPipeline': 667,
}
后面的666和667代表等级。数字越高就越后面执行。
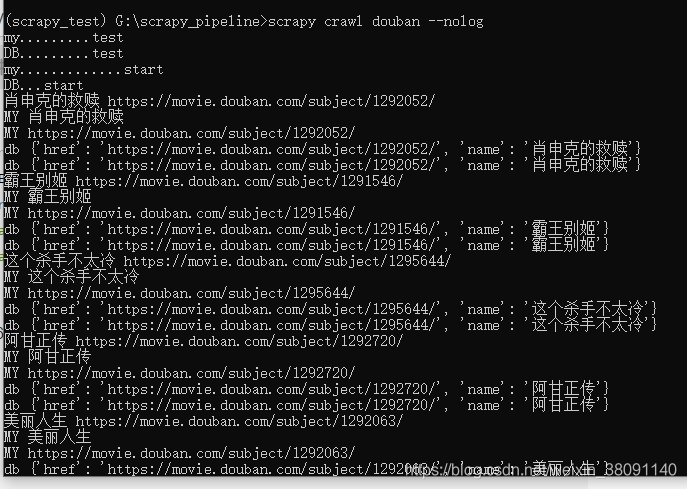
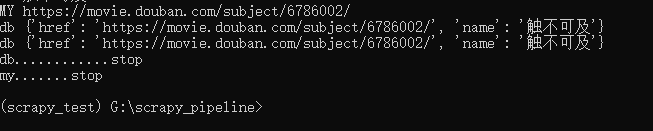
但是结束的是相反的。先执行的后关闭。
还有就是如果前面的process_item没有return的话后面的process_item是不会执行
我们把这一行注释了:return item # 交给下一个pipeline的proce_item方法
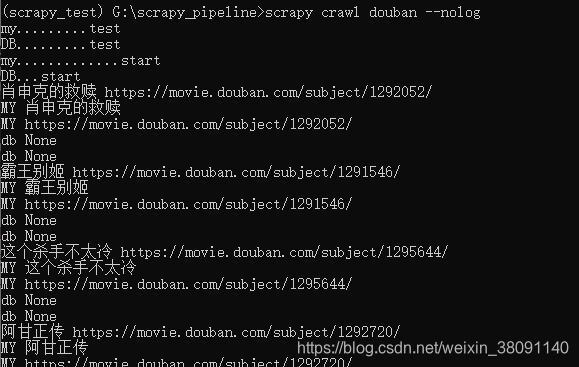
有关db的都是为none了,所以要想执行后面的pipeline就要return item,如果你想跳过不执行的话也可以:
#return item # 交给下一个pipeline的proce_item方法
raise DropItem # 后续的pipeline的process_item方法不再执行
把return改为raise DropItem这样就不会执行后面的process_item了。
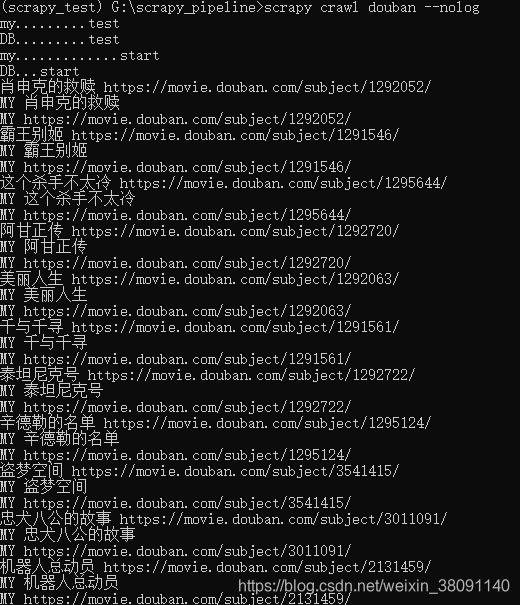
通过这里可以发现只是中间的操作没有进行而已,open_spider和close_spider还是会正常进行的。
