背景
了解MySQL的架构图,对MySQL有一个整体的把握,对于以后深入理解MySQL是有很大帮助的。比如:很多查询优化工作实际上就是遵循一些原则让MySQL的优化器能够按照预想的合理方式运行。 MySQL从概念上分为四层,如下图:
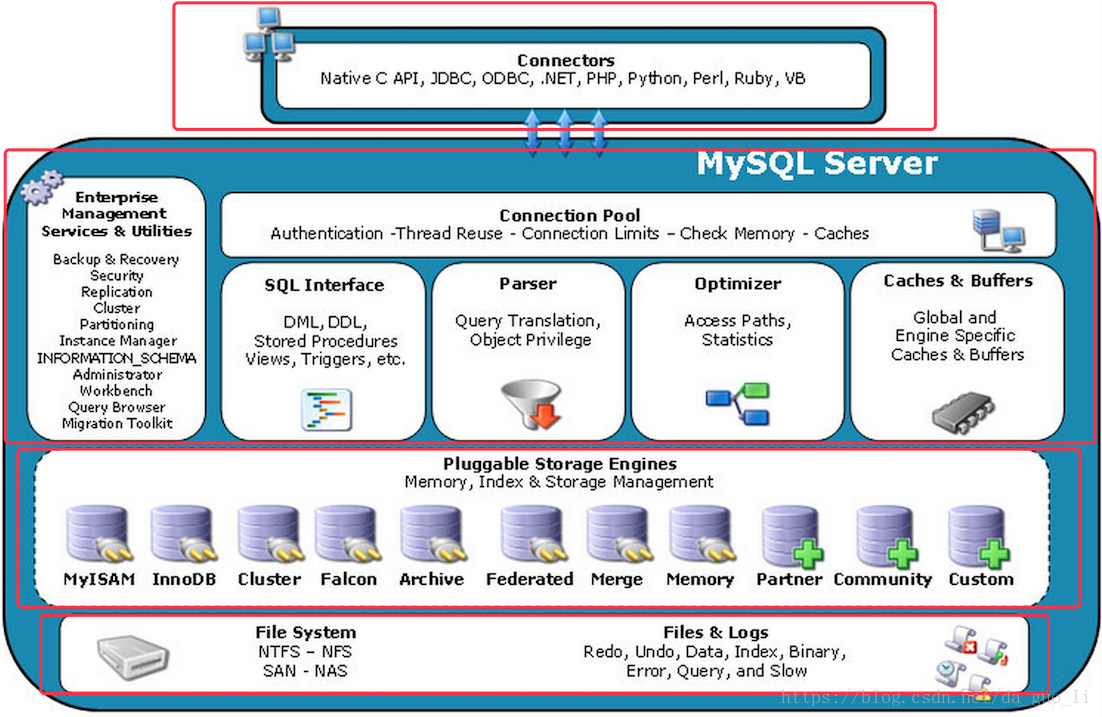
这四层自顶向下分别是
网络连接层,服务层(核心层),存储引擎层,系统文件层
。我们自顶向下开始讲解。
网络接入层
作用
主要负责连接管理、授权认证、安全等等。每个客户端连接都对应着服务器上的一个线程。服务器上维护了一个线程池,避免为每个连接都创建销毁一个线程。当客户端连接到MySQL服务器时,服务器对其进行认证。可以通过用户名与密码认证,也可以通过SSL证书进行认证。登录认证后,服务器还会验证客户端是否有执行某个查询的操作权限。这一层并不是MySQL所特有的技术。
为什么要设计成线程池?
在服务器内部,每个client都要有自己的线程。这个连接的查询都在一个单独的线程中执行。想象现实场景中数据库访问连接实在是太多了,如果每次连接都要创建一个线程,同时还要负责该线程的销毁。对于系统来说是多么大的消耗。由于线程是操作系统宝贵的资源。这时候线程池的出现就显得自然了,服务器缓存了线程,因此不需要为每个Client连接创建和销毁线程。
服务层
作用
第二层服务层是MySQL的核心,MySQL的核心服务层都在这一层,查询解析,SQL执行计划分析,SQL执行计划优化,查询缓存。以及跨存储引擎的功能都在这一层实现:存储过程,触发器,视图等。通过下图来观察服务层的内部结构:
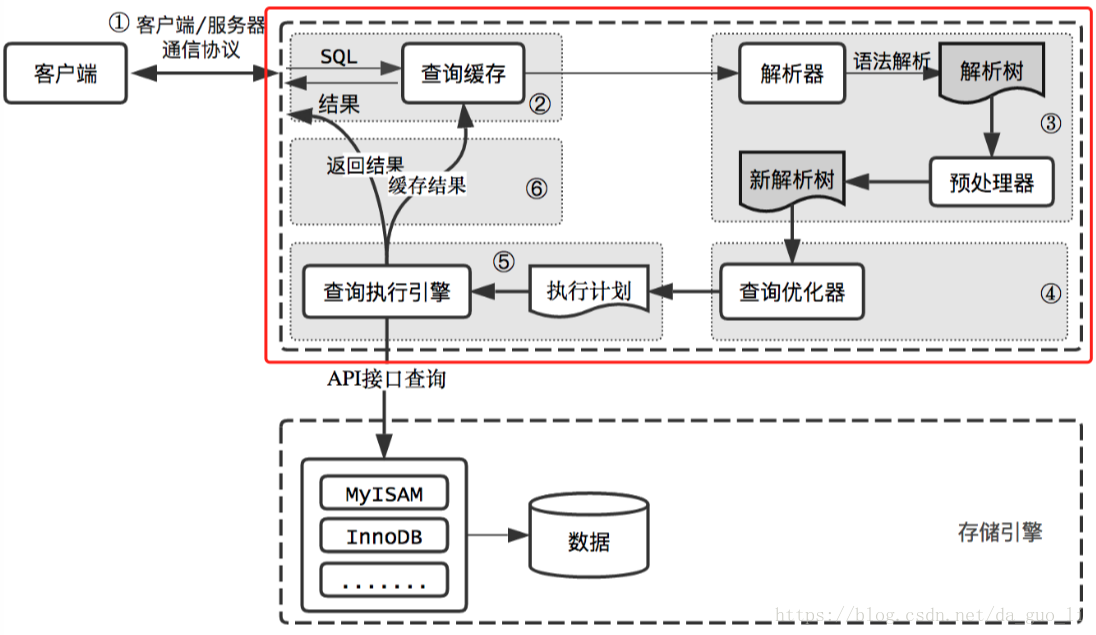
图中红色框中标出来的就是MySQL服务层内部执行的过程
下面来简单分析SQL语句在服务层中具体的流程:
查询缓存
在解析查询之前,服务器会检查查询缓存,如果能找到对应的查询,服务器不必进行查询解析、优化和执行的过程,直接返回缓存中的结果集。
解析器与预处理器
MySQL会解析查询,并创建了一个内部数据结构(解析树)。这个过程解析器主要通过语法规则来验证和解析。比如SQL中是否使用了错误的关键字或者关键字的顺序是否正确等等。预处理会根据MySQL的规则进一步检查解析树是否合法。比如要查询的数据表和数据列是否存在等。
查询优化器
优化器将其转化成查询计划。多数情况下,一条查询可以有很多种执行方式,最后都返回相应的结果。优化器的作用就是找到这其中最好的执行计划。优化器并不关心使用的什么存储引擎,但是存储引擎对优化查询是有影响的。优化器要求存储引擎提供容量或某个具体操作的开销信息来评估执行时间。
查询引擎
在完成解析和优化阶段以后,MySQL会生成对应的执行计划,查询执行引擎根据执行计划给出的指令调用存储引擎的接口得出结果。
存储引擎层
作用
负责MySQL中数据的存储与提取。 服务器中的查询执行引擎通过API与存储引擎进行通信,通过接口屏蔽了不同存储引擎之间的差异。MySQL采用插件式的存储引擎。MySQL为我们提供了许多存储引擎,每种存储引擎有不同的特点。我们可以根据不同的业务特点,选择最适合的存储引擎。如果对于存储引擎的性能不满意,可以通过修改源码来得到自己想要达到的性能。例如阿里巴巴的X-Engine,为了满足企业的需求facebook与google都对InnoDB存储引擎进行了扩充。
特点:
存储引擎是针对于表的而不是针对库的(一个库中不同表可以使用不同的存储引擎),服务器通过API与存储引擎进行通信,用来屏蔽不同存储引擎之间的差异。
下面大致介绍一下MySQL中常见的的存储引擎
InnoDB
特点:支持事务,适合OLTP应用,假设没有什么特殊的需求,一般都采用InnoDB作为存储引擎。支持行级锁,从MySQL5.5.8开始,InnoDB存储引擎是默认的存储引擎。
MyISAM
特点
不支持事务,表锁设计,支持全文索引,主要应用于OLAP应用
场景
在排序、分组等操作中,当数量超过一定大小之后,由查询优化器建立的临时表就是MyISAM类型
报表,数据仓库
Memory
特点
数据都存放在内存中,数据库重启或崩溃,表中的数据都将消失,但是标的结构还是会保存下来。默认使用Hash索引。
场景
适合存储OLTP应用的临时数据或中间表。
用于查找或是映射表,例如邮编和地区的对应表。
除此之外还有CSV,Federated、Archive等等。后面会开一篇博客专门讲解MySQL存储引擎。
系统文件层
作用
该层主要是将数据库的数据存储在文件系统之上,并完成与存储引擎的交互。
MyISAM物理文件结构为
为了掩饰我先建一个MyISAM存储引擎的表:
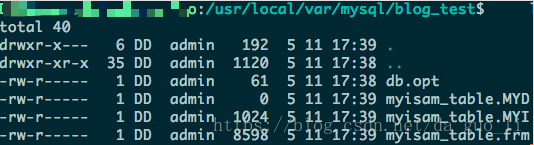
进入MySQL数据存储目录查看数据表在文件上的体现:
扫描二维码关注公众号,回复:
9301472 查看本文章

.frm文件:与表相关的元数据信息都存放在frm文件,包括表结构的定义信息等。
.MYD文件:MyISAM存储引擎专用,用于存储MyISAM表的数据
.MYI文件:MyISAM存储引擎专用,用于存储MyISAM表的索引相关信息
InnoDB物理文件结构
先建两个InnoD存储引擎的表:

进入MySQL数据存储目录查看数据表在文件上的体现:
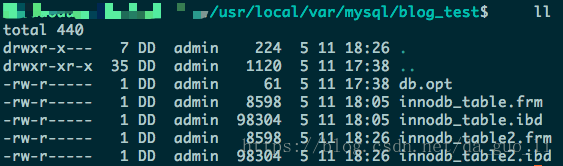
注意上面的每个表都有一个*.frm与*.ibd后缀文件他们的作用分别是:
.frm文件:与表相关的元数据信息都存放在frm文件,包括表结构的定义信息等。
.ibd文件:存放innodb表的数据文件。
除了.ibd文件InnoDB还有一种文件的存储格式为.ibdata文件,那么他们之间有什么区别呢?
这两种文件都是存放innodb数据的文件,之所以用两种文件来存放innodb的数据,是因为InnoDB的数据存储方式能够通过配置来决定是使用共享表空间存放存储数据,还是用独享表空间存放存储数据。独享表空间存储方式使用.ibd文件,并且每个表一个ibd文件。共享表空间存储方式采用.ibdata文件,所有的表共同使用一个ibdata文件,即所有的数据文件都存在一个文件中。决定使用哪种表的存储方式可以通过mysql的配置文件中 innodb_file_per_table选项来指定。InnoDB默认使用的是独享表的存储方式,这种方式的好处是当数据库产生大量文件碎片的时,整理磁盘碎片对线上运行环境的影响较小。
