定义数据库和实例
在数据库领域中有两个词很容易混淆,这就是“数据库”(database)和“实例”(instance)。作为常见的数据库术语,这两个词的定义如下:
- 数据库:物理操作系统文件或其他形式文件类型的集合。在MySQL数据库中,数据库文件可以是fm、MYD、MYI、ibd结尾的文件。当使用NDB引擎时,数据库的文件可能不是操作系统上的文件,而是存放在内存之中的文件,但是定义仍然不变。
- 实例:MySQL数据库由后台线程以及一个共享内存区组成。共享内存可以被运行的后台线程所共享。要注意的是,数据库实例才可以真正用于操作数据库系统文件。
这两个词有时可以互换使用,但概念完全不同。在MySQL数据库中,实例与数据库的关系通常是一一对应的,即一个实例对应一个数据库,一个数据库与一个实例对应。但是,在集群情况下可能存在一个数据库被多个数据库实例使用的情况。MySQL被设计为一个单进程多线程架构的数据库,这点与SQL Server比较类似,但与Oracle多进程的架构有所不同(Oracle的Windows版本也是单进程多线程架构)。也就是说,MySQL数据库实例在系统上的表现就是一个进程。
在Linux操作系统中通过以下命令启动MySQL数据库实例,并通过命令ps观察MySQL数据库启动后的进程情况:
# ./mysqld_safe& # ps -ef | grep mysql mysql 1 0 0 22:37 ? 00:00:28 mysqld root 180 175 0 22:38 ? 00:00:00 mysql -h 127.0.0.1 -u root -p root 520 518 0 23:36 ? 00:00:00 grep mysql
进程号为180的进程,为MySQL实例。启动MySQL实例的方法还有很多,在各个平台下的方式可能会有所不同,这里不一一例举。
在启动实例时,MySQL数据库会去读取配置文件,根据配置文件的参数来启动数据库实例。这与Oracle的参数文件(spfile)相似,不同的是,Oracle中如果没有参数文件,在启动实例时会提示找不到该参数文件,数据库启动失败。而MySQL数据库中,可以没有配置文件,在这种情况下,MySQL会按照编译时的默认参数设置启动实例。用以下命令可以查看当MySQL数据库实例启动时,会在哪些位置查找配置文件
# mysql --help | grep my.cnf
order of preference, my.cnf, $MYSQL_TCP_PORT,
/etc/my.cnf /etc/mysql/my.cnf ~/.my.cnf
可以看到,MySQL数据库是按/etc/my.cnf -> /etc/mysql/my.cnf ->~/.my.cnf的顺序读取配置文件的。那么问题来了,当多个文件存在同一个参数的配置时,以哪个文件为准?MySQL数据库会以读取到的最后一个配置文件中的参数为准。
配置文件中还有一个参数datadir,该参数指定了数据库所在的路径:
mysql> SHOW VARIABLES LIKE 'datadir'\G;
*************************** 1. row ***************************
Variable_name: datadir
Value: /var/lib/mysql/
1 row in set (0.41 sec)
mysql> system ls -lh /var/lib/mysql/
total 175M
-rw-r----- 1 mysql mysql 56 Oct 5 22:37 auto.cnf
-rw-r----- 1 mysql mysql 3.0M Oct 5 22:38 binlog.000001
-rw-r----- 1 mysql mysql 155 Oct 5 22:38 binlog.000002
-rw-r----- 1 mysql mysql 32 Oct 5 22:38 binlog.index
-rw------- 1 mysql mysql 1.7K Oct 5 22:37 ca-key.pem
-rw-r--r-- 1 mysql mysql 1.1K Oct 5 22:37 ca.pem
-rw-r--r-- 1 mysql mysql 1.1K Oct 5 22:37 client-cert.pem
-rw------- 1 mysql mysql 1.7K Oct 5 22:37 client-key.pem
-rw-r----- 1 mysql mysql 6.9K Oct 5 22:38 ib_buffer_pool
-rw-r----- 1 mysql mysql 48M Oct 5 22:38 ib_logfile0
-rw-r----- 1 mysql mysql 48M Oct 5 22:37 ib_logfile1
-rw-r----- 1 mysql mysql 12M Oct 5 22:38 ibdata1
-rw-r----- 1 mysql mysql 12M Oct 5 22:38 ibtmp1
drwxr-x--- 2 mysql mysql 143 Oct 5 22:37 mysql
-rw-r----- 1 mysql mysql 30M Oct 5 22:38 mysql.ibd
drwxr-x--- 2 mysql mysql 4.0K Oct 5 22:37 performance_schema
-rw------- 1 mysql mysql 1.7K Oct 5 22:37 private_key.pem
-rw-r--r-- 1 mysql mysql 452 Oct 5 22:37 public_key.pem
-rw-r--r-- 1 mysql mysql 1.1K Oct 5 22:37 server-cert.pem
-rw------- 1 mysql mysql 1.7K Oct 5 22:37 server-key.pem
drwxr-x--- 2 mysql mysql 28 Oct 5 22:37 sys
-rw-r----- 1 mysql mysql 12M Oct 5 22:38 undo_001
-rw-r----- 1 mysql mysql 10M Oct 5 22:38 undo_002
mysql> SHOW VARIABLES LIKE 'datadir'\G;
*************************** 1. row ***************************
Variable_name: datadir
Value: /var/lib/mysql/
1 row in set (0.00 sec)
MySQL体系结构
从概念上来说,数据库是文件的集合,是依照某种数据模型组织起来并存放于二级存储器中的数据集合;数据库实例是程序,是位于用户与操作系统之间的一层数据管理软件,用户对于数据库数据的任何操作,包括数据库定义、数据查询、数据维护、数据库运行控制等都是在数据库实例下进行的,应用程序只有通过数据库实例才能和数据库打交道。或者我们说的更直白点:数据库是由一个个文件组成(一般来说是二进制文件),要对这些文件执行诸如SELECT、INSERT、UPDATE、DELETE之类的数据库操作是不能通过简单的操作文件来更改数据库的内容,需要通过数据库实例来完成数据库的操作。
下面,让我们来看看MySQL数据库的体系结构了,其结构如图1-1所示
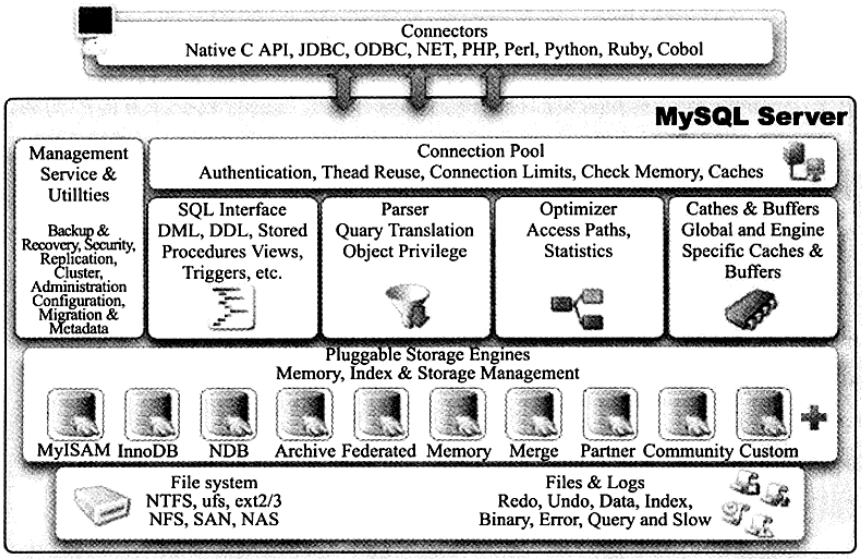
图1-1 MySQL体系结构
从图1-1可以发现,MySQL由以下几部分组成:
- 连接池组件
- 管理服务和工具组件
- SQL接口组件
- 查询分析器组件
- 优化器组件
- 缓冲(Cache)组件
- 插件式存储引擎
- 物理文件
从图1-1还可以发现,MySQL数据库区别于其他数据库的最重要一个特点就是其插件式的表存储引擎。MySQL插件式的存储引擎架构提供了一系列标准的管理和服务支持,这些标准与存储引擎本身无关,可能是每个数据库系统本身都必须的,如SQL分析器和优化器等,而存储引擎是底层物理结构的实现,每个存储引擎开发者可以按照自己的需求来开发。需要注意的是,存储引擎是基于表的,而不是数据库的。
MySQL存储引擎
每个存储引擎都有各自的特点,能够根据具体的应用建立不同的存储引擎表。
InnoDB存储引擎
InnoDB存储引擎支持事物,其设计目标主要面向在线事物处理(OLTP)的应用。其特点是行锁设计、支持外键,并支持类似于Oracle的非锁定读,即默认读操作不会产生锁。InnoDB存储引擎将数据放在一个逻辑的表空间中,这个表空间就像黑盒一样由InnoDB存储引擎自身管理。从MySQL4.1(包括4.1)版本开始,它可以将每个InnoDB存储引擎的表单独存放到一个独立的ibd文件中。此外,InnoDB存储引擎支持裸设备(row disk)用来建立表空间
InnoDB通过使用多版本并发控制(MVCC)来获得高并发性,并且实现了SQL标准的4种隔离级别,默认是REPEATABLE-READ级别。同时,使用一种被称为next-key locking的策略来避免幻读(phantom)现象的产生。除此之外,InnoDB存储引擎还提供了插入缓冲(insert buffer)、二次读写(double write)、自适应哈希索引(adaptive hash index)、预读(read ahead)等高性能和高可用的功能。
对于表中数据的存储,InnoDB存储引擎采用了聚集(clustered)的方式,因此每张表的存储都是按主键的顺序进行存放。如果没有显示地在表定义时指定主键,InnoDB存储引擎会为每一行生成一个6字节的ROWID,并以此作为主键。
MyISAM存储引擎
MyISAM存储引擎不支持事物、表锁设计,支持全文索引,主要面向一些OLAP数据库应用。数据库系统与文件系统很大的一个不同之处在于对事物的支持,然而MyISAM存储引擎是不支持事物的,毕竟并非所有的应用都需要事物,如果对数据仅仅只有查询的需求,那就没有支持事物的必要。此外,MyISAM存储引擎的另一个与众不同的地方是它的缓冲池只缓存(cache)索引文件,而不缓冲数据文件。
MyISAM存储引擎表由MYD和MYI组成,MYD用来存放数据文件,MYI用来存放索引文件。在MySQL5.0之前,MyISAM默认支持的表大小为4GB,如果需要修改这一限制需要制定MAX_ROWS和AVG_ROW_LENGTH属性。从MySQL5.0开始,MyISAM默认支持256TB的单表数据
NDB存储引擎
NDB存储引擎是一个集群存储引擎,类似于Oracle的RAC集群,不过与Oracle RAC share everything架构不同的是,其结构是share nothing的集群架构,因此能提供更高的可用性。NDB的特点是数据全部放在内存中(从MySQL5.1开始,可以将非索引数据存放在磁盘上),因此主键查找的速度极快,并且通过添加NDB数据存储节点可以线性地提高数据库性能,是高可用、高性能的集群系统。
关于NDB存储引擎,有一点需要注意,就是NDB存储引擎的连接操作(JOIN)是在MySQL数据库层完成的,而不是在存储引擎完成的。这意味着,复杂的连接操作需要巨大的网络开销,因此查询速度慢。
Memory存储引擎
Memory存储引擎将表中的数据存放在内存中,如果数据库重启或发生崩溃,表中的数据将消失,它非常适合用于存储临时数据的临时表,以及数据仓库中的纬度表。Memory存储引擎默认使用哈希索引,而不是我们熟悉的B+树索引。虽然Memory存储引擎速度非常快,但在使用上有一定的限制。比如,只支持表锁,并发性能较差,并且不支持TEXT和BLOB列类型。最重要的是,存储变长字段(varchar)时是按照定长字段(char)的方式进行,因此会浪费内存。
此外有一点容易被忽视,MySQL数据库使用Memory存储引擎作为临时表来存放查询的中间结果集。如果中间结果集大于Memory存储引擎表的容量设置,又或者中间结果含有TEXT或BLOB列类型字段,则MySQL数据库会把其转换到MyISAM存储引擎表而存放在磁盘中。之前提到MyISAM不缓存数据文件,因此这时所产生的临时表的性能对于查询会有损失。
Archive存储引擎
Archive存储引擎只支持INSERT和SELECT操作,从MySQL5.1开始支持索引。Archive存储引适用zlib算法将数据行(row)进行压缩后存储,压缩比一般可达1:10。Archive存储引擎适合存储归档数据,如日志信息,它适用行锁来实现高并发插入操作,但其本身并不是事物安全的存储引擎,其设计目的主要是提供高速的插入和压缩功能。
Federated存储引擎
Federated存储引擎表并不存放数据,它只是指向一台远程MySQL数据库服务器上的表。这非常类似SQL Server的链接服务器和Oracle的透明网关,不同的是,当前Federated存储引擎只支持MySQL数据库表,不支持异构数据库表。
Maria存储引擎
Maria存储引擎是新开发的引擎,设计目标主要是用来取代原有的MyISAM存储引擎,从而成为MySQL的默认存储引擎。Maria存储引擎的特点是:支持缓存数据和索引文件,应用了行锁设计,提供了MVCC功能,支持事物和非事物安全的选项,以及更好的BLOB字符类型的处理性能。
其他存储引擎
除了上面提到的7种存储引擎外,MySQL数据库还有很多其他的存储引擎,包括Merge、CSV、Sphinx和Infobright,它们都有各自使用的场合。这里,我们回答几个MySQL常被人质疑的问题:
- 为什么MySQL数据库不支持全文索引?不!MySQL支持的,MyISAM、InnoDB(1.2版本)和Sphinx存储引擎都支持全文索引。
- MySQL数据库快是因为不支持事物?错!虽然MySQL的MyISAM存储引擎不支持事物,但InnoDB支持。“快”是针对于不同应用来说,对于ETL这种操作,MyISAM会有优势,但在OLTP环境中,InnoDB存储引擎的效率更高。
- 当表的数据量大于1000万时MySQL的性能会急剧下降吗?不!MySQL是数据库,不是文件,随着数据行数的增加,性能当然后有所下降,但是这些下降不是线性的,如果用户选择了正确的存储引擎,以及正确的配置,再多的数据量MySQL也能承受。
各存储引擎之间的比较
图1-2取自于MySQL的官方手册,展现了一些常用的MySQL存储引擎的不同之处,包括存储容量的限制、事物支持、锁的粒度、MVCC支持、支持的索引、备份和复制等。
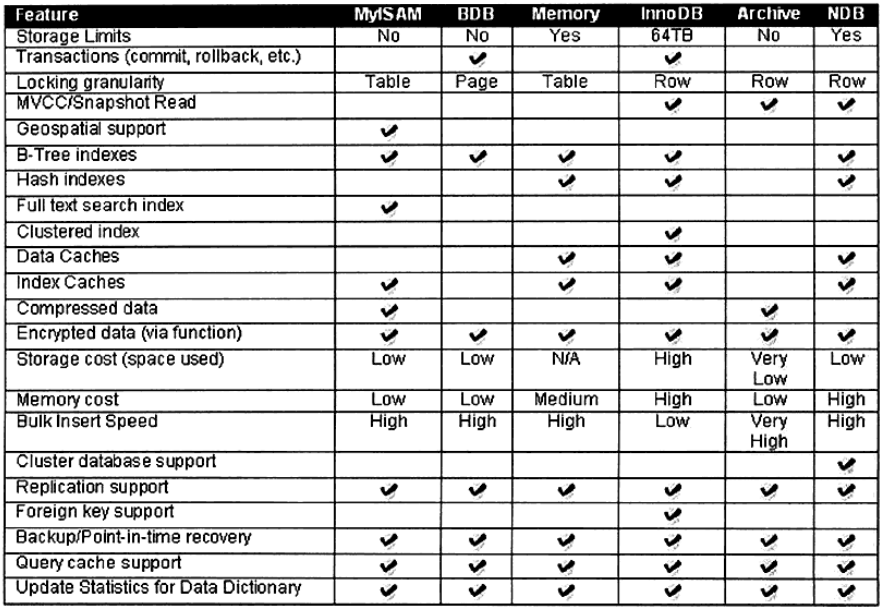
图1-2 不同MySQL存储引擎相关特性比较
可以通过SHOW ENGINES语句查看当前使用的MySQL数据库所支持的存储引擎,也可以通过查找information_schema架构下的ENGINES表,如下所示:
mysql> SHOW ENGINES\G;
*************************** 1. row ***************************
Engine: FEDERATED
Support: NO
Comment: Federated MySQL storage engine
Transactions: NULL
XA: NULL
Savepoints: NULL
*************************** 2. row ***************************
Engine: MEMORY
Support: YES
Comment: Hash based, stored in memory, useful for temporary tables
Transactions: NO
XA: NO
Savepoints: NO
*************************** 3. row ***************************
Engine: InnoDB
Support: DEFAULT
Comment: Supports transactions, row-level locking, and foreign keys
Transactions: YES
XA: YES
Savepoints: YES
*************************** 4. row ***************************
Engine: PERFORMANCE_SCHEMA
Support: YES
Comment: Performance Schema
Transactions: NO
XA: NO
Savepoints: NO
*************************** 5. row ***************************
Engine: MyISAM
Support: YES
Comment: MyISAM storage engine
Transactions: NO
XA: NO
Savepoints: NO
*************************** 6. row ***************************
Engine: MRG_MYISAM
Support: YES
Comment: Collection of identical MyISAM tables
Transactions: NO
XA: NO
Savepoints: NO
*************************** 7. row ***************************
Engine: BLACKHOLE
Support: YES
Comment: /dev/null storage engine (anything you write to it disappears)
Transactions: NO
XA: NO
Savepoints: NO
*************************** 8. row ***************************
Engine: CSV
Support: YES
Comment: CSV storage engine
Transactions: NO
XA: NO
Savepoints: NO
*************************** 9. row ***************************
Engine: ARCHIVE
Support: YES
Comment: Archive storage engine
Transactions: NO
XA: NO
Savepoints: NO
9 rows in set (0.00 sec)
下面将通过MySQL提供的示例数据库来简单显示各存储引擎之间的不同。这里将分别运行以下语句,然后统计每次使用各存储引擎后表的大小。
mysql>CREATE TABLE mytest Engine=MyISAM AS SELECT * FROM salaries; mysql>ALTER TABLE mytest Engine=InnoDB; mysql>ALTER TABLE mytest Engine=ARCHIVE;
通过每次的统计,可以发现当最初表使用MyISAM存储引擎时,表的大小为40.7MB,使用InnoDB存储引擎时表增大到113.6MB,而使用Archive存储引擎时表的大小只有20.2MB,这个例子只是从表的大小方面揭示了各个存储引擎的不同。
连接MySQL
连接MySQL操作是一个连接进程和MySQL数据库实例进行通信的过程,本质上是进程通信。如果对进程通信比较了解,可以知道常用的进程通信方式有管道、命令管道、命名字、TCP/IP套接字、Unix域套接字。
TCP/IP
TCP/IP套接字方式是MySQL数据库在任何平台下都提供的连接方式,也是网络中使用最多的一种方式。这种方式在TCP/IP连接上建立了一个基于网络的连接请求,一般情况下客户端(client)在一台服务器上,而MySQL实例(server)可能在另一台服务器上,这两台机器通过一个TCP/IP网络连接。例如,用户可以在Linux服务器下请求另一个Linux服务器下的MySQL实例,如下所示
# mysql -h 127.0.0.1 -u root -p Enter password: Welcome to the MySQL monitor. Commands end with ; or \g. …… mysql>
在通过TCP/IP连接到MySQL实例时,MySQL数据库会先检查一张权限视图,用来判断发起请求的客户端IP是否允许连接到MySQL实例。该视图在mysql架构下,表明为user,如下所示:
mysql> use mysql
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> SELECT host,user,authentication_string FROM user\G;
*************************** 1. row ***************************
host: %
user: root
authentication_string: $A$005$aTGv+C8;XH.hxVjDY2eofMJB7w5xGtdwrqjHLIkmKxdFWAUNp3Sy/J9
*************************** 2. row ***************************
host: localhost
user: mysql.infoschema
authentication_string: $A$005$THISISACOMBINATIONOFINVALIDSALTANDPASSWORDTHATMUSTNEVERBRBEUSED
*************************** 3. row ***************************
host: localhost
user: mysql.session
authentication_string: $A$005$THISISACOMBINATIONOFINVALIDSALTANDPASSWORDTHATMUSTNEVERBRBEUSED
命名管道和共享内存
在Windows 2000、Windows XP、Windows2003和Windows Vista以及在此之上的平台上,如果两个需要进程通信的进程在同一台服务器上,那么可以使用命名管道,Microsoft SQL Server数据库默认安装后的本地连接也是使用命名管道。在MySQL数据库中须在配置文件中启用–enable-named-pipe选项。在MySQL 1.4之后的版本中,MySQL还提供了共享内存的连接方式,这是通过在配置文件中添加–shared-memory实现的。如果想使用共享内存的方式,在连接时,MySQL客户端还必须使用–protocol=memory选项。
Unix域套接字
在Linux和Unix环境下,还可以使用Unix套接字。Unix域套接字其实不是一个网络协议,所以只能在MySQL客户端和数据库实例在一台服务器上的情况下使用。用户可以在配置文件中指定套接字文件的路径,如–socket=/tmp/mysql.sock。当数据库实例启动后,用户可以通过下列命令来进行Unix域套接字文件的查找:
mysql> SHOW VARIABLES LIKE 'socket'\G;
*************************** 1. row ***************************
Variable_name: socket
Value: /var/run/mysqld/mysqld.sock
1 row in set (0.01 sec)
在知道Unix域套接字文件的路径后,就可以使用该方式进行连接了,如下所示:
# mysql -h 127.0.0.1 -u root -p123456 -S /var/run/mysqld/mysqld.sock mysql: [Warning] Using a password on the command line interface can be insecure. Welcome to the MySQL monitor. Commands end with ; or \g. …… mysql>