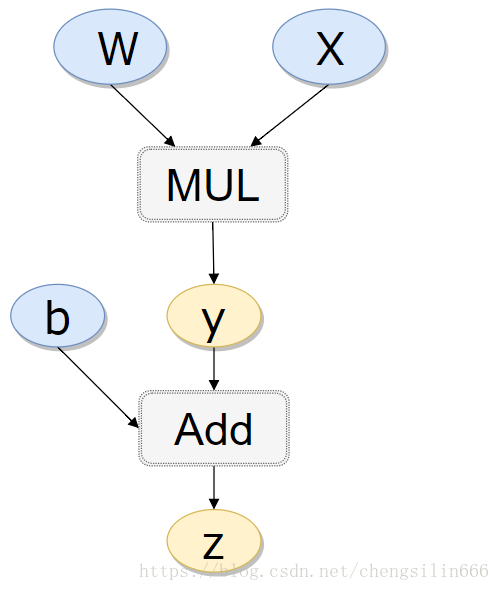
如上有向无环图中,
和
是叶子节点(leaf node),这些节点通常由用户自己创建,不依赖于其他变量。
称为根节点,是计算图的最终目标。利用链式法则很容易求得各个叶子节点的梯度。
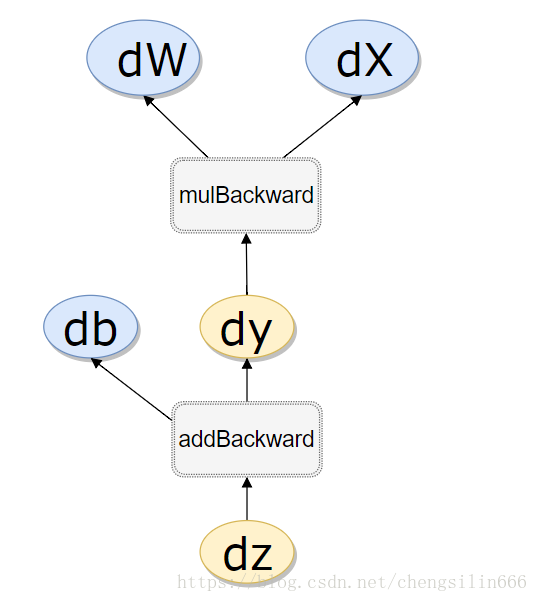
而有了计算图,上述链式求导即可利用计算图的反向传播自动完成。
在PyTorch实现中,autograd会随着用户的操作,记录生成当前variable的所有操作,并由此建立一个有向无环图。用户每进行一个操作,相应的计算图就会发生改变。更底层的实现中,图中记录了操作Function,每一个变量在图中的位置可通过其grad_fn属性在图中的位置推测得到。在反向传播过程中,autograd沿着这个图从当前变量(根节点
)溯源,可以利用链式求导法则计算所有叶子节点的梯度。每一个前向传播操作的函数都有与之对应的反向传播函数用来计算输入的各个variable的梯度,这些函数的函数名通常以Backward结尾。下面结合代码学习autograd的实现细节。
在PyTorch中计算图的特点可总结如下:
- autograd根据用户对variable的操作构建其计算图。对变量的操作抽象为
Function。 - 对于那些不是任何函数(Function)的输出,由用户创建的节点称为叶子节点,叶子节点的
grad_fn为None。叶子节点中需要求导的variable,具有AccumulateGrad标识,因其梯度是累加的。 - variable默认是不需要求导的,即
requires_grad属性默认为False,如果某一个节点requires_grad被设置为True,那么所有依赖它的节点requires_grad都为True。 - variable的
volatile属性默认为False,如果某一个variable的volatile属性被设为True,那么所有依赖它的节点volatile属性都为True。volatile属性为True的节点不会求导,volatile的优先级比requires_grad高。 - 多次反向传播时,梯度是累加的。反向传播的中间缓存会被清空,为进行多次反向传播需指定
retain_graph=True来保存这些缓存。 - 非叶子节点的梯度计算完之后即被清空,可以使用
autograd.grad或hook技术获取非叶子节点的值。 - variable的grad与data形状一致,应避免直接修改variable.data,因为对data的直接操作无法利用autograd进行反向传播
- 反向传播函数
backward的参数grad_variables可以看成链式求导的中间结果,如果是标量,可以省略,默认为1 - PyTorch采用动态图设计,可以很方便地查看中间层的输出,动态的设计计算图结构。
这些知识不懂大多数情况下也不会影响对pytorch的使用,但是掌握这些知识有助于更好的理解pytorch,并有效的避开很多陷阱
