1.protobuf简介
protobuf(Protocol Buffers )是google的开源项目,官网见:click这里,源码见:github。更准确的官方描述是:protobuf是google的中立于语言,平台,可扩展的用于序列化结构化数据的解决方案。
简单的说,protobuf是用来对数据进行序列化和反序列化。那么什么是数据的序列化和反序列化呢?见下文。
protobuf支持目前主流的开发语言,包括C++、Java、Python、Objective-C、C#、JavaNano、JavaScript、Ruby、Go、PHP等。只要你使用以上语言,都可以用protobuf来序列化和反序列化你的数据。
2.数据的序列化和反序列化
序列化 (Serialization):将数据结构或对象转换成二进制串的过程
反序列化(Deserialization):将在序列化过程中所生成的二进制串转换成数据结构或者对象的过程。
我们为什么要序列化数据,貌似很多人并没有使用过,但是序列化数据却无处不在。我们要存储或者传输数据时,需要将当前数据对象转换成字节流便于网络传输或者存储。当我们需要再次使用这些数据时,需要将接收到的或者读取的字节流进行反序列化,重建我们的数据对象。
多说无益,举个例子。假如程序中你用到了如下结构的对象,以C++为例:
//学生类型
struct Student{
char ID[20]
char name[10];
int age;
int gender;
};
//定义一个学生对象
Student student;
strcpy(student.ID,"312822199204085698");
strcpy(student.name,"dablelv");
student.age=18;
student.gender=0;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
现在我需要将学生对象从客户端程序发送到远程的服务端程序。那们这个时候我们就需要对学生对象student进行序列化操作。以Linux的socket进行发送,我们需要调用系统为我们提供的网络IO相关的API,它们有如下几组:
#include <unistd.h>
ssize_t read(int fd, void *buf, size_t count);
ssize_t write(int fd, const void *buf, size_t count);
#include <sys/types.h>
#include <sys/socket.h>
ssize_t send(int sockfd, const void *buf, size_t len, int flags);
ssize_t recv(int sockfd, void *buf, size_t len, int flags);
ssize_t sendto(int sockfd, const void *buf, size_t len, int flags,
const struct sockaddr *dest_addr, socklen_t addrlen);
ssize_t recvfrom(int sockfd, void *buf, size_t len, int flags,
struct sockaddr *src_addr, socklen_t *addrlen);
ssize_t sendmsg(int sockfd, const struct msghdr *msg, int flags);
ssize_t recvmsg(int sockfd, struct msghdr *msg, int flags);- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
假设套接字描述符为sockfd,这里采用UDP通信,无需建立连接,但是要指定地址,假设地址为dest_addr那么我们就可以使用如下语句将学生对象student发送到服务端。
//flags调用方式一般设置为0
sendto(sockfd,&student,sizeof(Student),0,dest_addr,sizeof(struct sockaddr));- 1
- 2
服务端采用如下语句进行接收:
char buf[1024]="";//假设我们接收的数据不超过1024B
recvfrom(sockfd, buf, 1024, 0,NULL,NULL);//这里不保存数据包的来源地址与地址类型长度
Student* pStudent=(Student*)buf;
//下面就可以访问接收的学生对象
cout<<cout<<pStudent->ID; //访问学生ID
cout<<cout<<pStudent->name; //访问学生ID
//... //and so on- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
写了一大堆,可能你会发现,我并没有将学生对象student转换成字节流进行传输。事实上,我们确实是以字节流进行传输的,我们所使用的数据对于计算来说都是二进制的字节而已。我们这里也进行了序列化,就是简单的将传输的对象默认转换成void*进行传输。收到数据后,其实我们也进行了反序列化,进行了强制类型转换,以指定的格式去解析我们收到的字节流。
请注意了,我们收到的字节流,当我们对其解析时是利用了强制类型转换,转换成现有的数据类型去读取。这里有个问题,如果我们服务端的数据类型和客户端的不一样,或者说客户端需要在学生类型中增加一个专业major字段,那么这个major添加到了客户端的Student类型的后面,添加如下:
//客户端类型
struct Student{
char ID[20]
char name[10];
int age;
int gender;
char major[10]; //new added
};
//服务端类型不变
struct Student{
char ID[20]
char name[10];
int age;
int gender;
};- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
你会发现,在服务端使用现有的Student类型去解析还是可以正确解析。但是如果major字段并不是添加在Student类型的最后而是其它的位置,或者说客户端和服务端类型中的字段顺序不同,你就会发现读取的数据是错误的。
这个时候,我们就需要设计序列化的协议,或者说是设计传输的数据格式,以满足对数据类型不同,某些字段相同的情况下,解析出我们想要的数据。至于如何设计,我们以json为例。
2.1JSON简介
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式。它基于ECMAScript的一个子集。 JSON采用完全独立于语言的文本格式,这些特性使JSON成为理想的数据交换语言,易于人阅读和编写,同时也易于机器解析和生成,一般用于网络传输。
比如上面的学生对象,我们以json表的话,可以表示为:
{"ID":"312822199204085698","gender":0,"major":"math","name":18}- 1
JSON 语法规则:
JSON 语法是 JavaScript 对象表示语法的子集。
数据在键值对中
数据由逗号分隔
花括号保存对象
方括号保存数组
json支持的类型有:
数字(整数或浮点数)
字符串(在双引号中)
逻辑值(true 或 false)
数组(在方括号中)
对象(在花括号中)
null
2.2JSON的简单实例
当网络中不同主机进行数据传输时,我们就可以采用json进行传输。将现有的数据对象转换为json字符串就是对对象的序列化操作,将接收到的json字符串转换为我需要的对象,就是反序列化操作。下面以jsoncpp作为C++的json解析库,来演示一下将对象序列化为json字符串,并从json字符串中解析出我们想要的数据。
#include <string.h>
#include <string>
#include <iostream>
using namespace std;
#include "json/json.h"
struct Student{
char ID[20];
char name[10];
int age;
int gender;
char major[10];
};
string serializeToJson(const Student& student);
Student deserializeToObj(const string& strJson);
int main(int argc, char** argv) {
Student student;
strcpy(student.ID,"312822199204085698");
strcpy(student.name,"dablelv");
student.age=18;
student.gender=0;
strcpy(student.major,"math");
string strJson=serializeToJson(student);
cout<<"strJson:"<<strJson<<endl;
string strJsonNew="{\"ID\":\"201421031059\",\"name\":\"lvlv\",\"age\":18,\"gender\":0}";
Student resStudent=deserializeToObj(strJsonNew);
cout<<"resStudent:"<<endl;
cout<<"ID:"<<resStudent.ID<<endl;
cout<<"name:"<<resStudent.name<<endl;
cout<<"age:"<<resStudent.age<<endl;
cout<<"gender:"<<resStudent.gender<<endl;
cout<<"major:"<<resStudent.major<<endl;
return 0;
}
//@brief:将给定的学生对象序列化为json字符串
//@param:student:学生对象
//@ret:json字符串
string serializeToJson(const Student& student){
Json::FastWriter writer;
Json::Value person;
person["ID"] = student.ID;
person["name"] = student.name;
person["age"]=student.age;
person["gender"]=student.gender;
person["major"]=student.major;
string strJson=writer.write(person);
return strJson;
}
//@brief:将给定的json字符串反序列化为学生对象
//@param:strJson:json字符串
//@ret:学生对象
Student deserializeToObj(const string& strJson){
Json::Reader reader;
Json::Value value;
Student student;
memset(&student,0,sizeof(Student));
if (reader.parse(strJson, value)){
strcpy(student.ID,value["ID"].asString().c_str());
strcpy(student.name,value["name"].asString().c_str());
student.age=value["age"].asInt();
student.gender=value["gender"].asInt();
strcpy(student.major,value["major"].asString().c_str());
}
return student;
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
程序输出结果:

上面的major输出之所以为空,是因为json字符串中没有major字段。使用json来传输我们的数据对象,新增加的major字段可以放在任意的位置,并不影响我们从json中解析我们想要的字段。这样在服务端和客户端之间就可以传输不同类型的数据对象了!
2.3C++对象序列化的四种方法
2.3.1Google Protocol Buffers
Google Protocol Buffers (GPB)是Google内部使用的数据编码方式,旨在用来代替XML进行数据交换。可用于数据序列化与反序列化。主要特性有:
(1)高效;
(2)语言中立(Cpp, Java, Python);
(3)可扩展。
官方文档请点击这里。
2.3.2 Boost.Serialization
Boost.Serialization可以创建或重建程序中的等效结构,并保存为二进制数据、文本数据、json、XML或者有用户自定义的其他文件。该库具有以下吸引人的特性:
(1)代码可移植(实现仅依赖于ANSI C++)。
(2)深度指针保存与恢复。
(3)可以序列化STL容器和其他常用模版库。
(4)数据可移植。
(5)非入侵性。
2.3.3 MFC Serialization
Windows平台下可使用MFC中的序列化方法。MFC 对 CObject 类中的序列化提供内置支持。因此,所有从 CObject 派生的类都可利用 CObject 的序列化协议。详见MSDN中的介绍。
2.3.4 Net Framework
.NET的运行时环境用来支持用户定义类型的流化的机制。它在此过程中,先将对象的公共字段和私有字段以及类的名称(包括类所在的程序集)转换为字节流,然后再把字节流写入数据流。在随后对对象进行反序列化时,将创建出与原对象完全相同的副本。
2.3.5 简单总结
这几种序列化方案各有优缺点,各有自己的适用场景。其中MFC和.Net框架的方法适用范围很窄,只适用于Windows下,且.Net框架方法还需要.Net的运行环境。参考文献1从序列化时间、反序列化时间和产生数据文件大小这几个方面比较了前三种序列化方案,得出结论如下(仅供参考):
Google Protocol Buffers效率较高,但是数据对象必须预先定义,并使用protoc编译,适合要求效率,允许自定义类型的内部场合使用。Boost.Serialization使用灵活简单,而且支持标准C++容器。相比而言,MFC的效率较低,但是结合MSVS平台使用最为方便。
为了考虑平台的移植性、适用性和高效性,推荐大家使用Google的protobuf和Boost的序列化方案,下面我重点介绍protobuf的使用方法及注意事项。
3.ProtoBuf的用法用例
protobuf相对而言效率应该是最高的,不管是安装效率还是使用效率,protobuf都很高效,而且protobuf不仅用于C++序列化,还可用于Java和Python的序列化,使用范围很广。
关于ProtoBuf示例代码包含在源代码包中的“examples”目录下。点击此处下载。
3.1ProtoBuf数据类型
首先看一下ProtoBuf支持的数据类型。protobuf属于轻量级的,因此不能支持太多的数据类型,下面是protobuf支持的基本类型列表,一般都能满足需求,不过在选择方案之前,还是先看看是否都能支持,以免前功尽弃。同样该表也值得收藏,作为我们在定义类型时做参考。
| proto文件消息类型 | C++ 类型 | 说明 |
|---|---|---|
| double | double | |
| float | float | |
| int32 | int32 | 使用可变长编码方式,负数时不够高效,应该使用sint32 |
| int64 | int64 | 同上 |
| uint32 | uint32 | 使用可变长编码方式 |
| uint64 | uint64 | 同上 |
| sint32 | int32 | 使用可变长编码方式,有符号的整型值,负数编码时比通常的int32高效 |
| sint64 | sint64 | 同上 |
| fixed32 | uint32 | 总是4个字节,如果数值总是比2^28大的话,这个类型会比uint32高效 |
| fixed64 | uint64 | 总是8个字节,如果数值总是比2^56大的话,这个类型会比uint64高效 |
| sfixed32 | int32 | 总是4个字节 |
| sfixed64 | int64 | 总是8个字节 |
| bool | bool | |
| string | string | 一个字符串必须是utf-8编码或者7-bit的ascii编码的文本 |
| bytes | string | 可能包含任意顺序的字节数据 |
3.2ProtoBuf使用的一般步骤
知道了ProtoBuf的作用与支持的数据类型。我么需要知道ProtoBuf使用的一般步骤,下面以C++中使用ProtoBuf为例来描述使用的一般步骤。
第一步:定义proto文件,文件的内容就是定义我们需要存储或者传输的数据结构,也就是定义我们自己的数据存储或者传输的协议。
第二步:编译安装protocol buffer编译器来编译自定义的.proto文件,用于生成.pb.h文件(proto文件中自定义类的头文件)和 .pb.cc(proto文件中自定义类的实现文件)。
第三步: 使用protoco buffer的C++ API来读写消息。
下面将具体讲解每一步的实现。
3.3定义proto文件
定义proto文件就是定义自己的数据存储或者传输的协议格式。我们以上面需要传输的Student对象为例。要想序列化Student对象进行网络传输,那么我们需要从编写一个.proto文件开始。.proto文件的定义是比较简单的:为每一个你需要序列化的数据结构添加一个消息(message),然后为消息(message)中的每一个字段(field)指定一个名字、类型和修饰符以及唯一标识(tag)。每一个消息对应到C++中就是一个类,嵌套消息对应的就是嵌套类,当然一个.proto文件中可以定义多个消息,就像一个头文件中可以定义多个类一样。下面就是一个自定义的嵌套消息的.proto文件student.proto。
package tutorial;
message Student{
required uint64 id = 1;
required string name =2;
optional string email = 3;
enum PhoneType {
MOBILE = 0;
HOME = 1;
}
message PhoneNumber {
required string number = 1;
optional PhoneType type = 2 [default = HOME];
}
repeated PhoneNumber phone = 4;
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
正如你所看到的一样,该语法类似于C++或Java的语法。让我们依次来看看文件的每一部分的作用。
关于package声明。
.proto文件以一个package声明开始。这个声明是为了防止不同项目之间的命名冲突。对应到C++中去,你用这个.proto文件生成的类将被放置在一个与package名相同的命名空间中。
关于字段类型。
再往下看,就是若干消息(message)定义了。一个消息就是某些类型的字段的集合。许多标准的、简单的数据类型都可以用作字段类型,包括bool,int32,float,double以及string。你也可以使用其他的消息(message)类型来作为你的字段类型——在上面的例子中,消息PhoneNumber 就是一个被用作字段类型的例子。
关于修饰符。
每一个字段都必须用以下之一的修饰符来修饰:
required:必须提供字段值,否则对应的消息就会被认为是“未初始化的”。如果libprotobuf是以debug模式编译的,序列化一个未初始化的消息(message)将会导致一个断言错误。在优化过的编译情况下(译者注:例如release),该检查会被跳过,消息会被写入。然而,解析一个未初始化的消息仍然会失败(解析函数会返回false)。除此之外,一个required的字段与一个optional的字段就没有区别了。
optional:字段值指定与否都可以。如果没有指定一个optional的字段值,它就会使用默认值。对简单类型来说,你可以指定你自己的默认值,就像我们在上面的例子中对phone number的type字段所做的一样。如果你不指定默认值,就会使用系统默认值:数据类型的默认值为0,string的默认值为空字符串,bool的默认值为false。对嵌套消息(message)来说,其默认值总是消息的“默认实例”或“原型”,即:没有任何一个字段是指定了值的。调用访问类来取一个未显式指定其值的optional(或者required)的字段的值,总是会返回字段的默认值。
repeated:字段会重复N次(N可以为0)。重复的值的顺序将被保存在protocol buffer中。你只要将重复的字段视为动态大小的数组就可以了。
注意: required是永久性的:在把一个字段标识为required的时候,你应该特别小心。如果在某些情况下你不想写入或者发送一个required的字段,那么将该字段更改为optional可能会遇到问题——旧版本的读者(译者注:即读取、解析消息的一方)会认为不含该字段的消息(message)是不完整的,从而有可能会拒绝解析。在这种情况下,你应该考虑编写特别针对于应用程序的、自定义的消息校验函数。Google的一些工程师得出了一个结论:使用required弊多于利;他们更愿意使用optional和repeated而不是required。当然,这个观点并不具有普遍性。
关于标识。
在每一项后面的、类似于“= 1”,“= 2”的标志指出了该字段在二进制编码中使用的唯一“标识(tag)”。标识号1~15编码所需的字节数比更大的标识号使用的字节数要少1个,所以,如果你想寻求优化,可以为经常使用或者重复的项采用1~15的标识(tag),其他经常使用的optional项采用≥16的标识(tag)。在重复的字段中,每一项都要求重编码标识号(tag number),所以重复的字段特别适用于这种优化情况。
你可以在Language Guide (proto3)一文中找到编写.proto文件的完整指南(包括所有可能的字段类型)。但是,不要想在里面找到与类继承相似的特性,因为protocol buffers不是拿来做这个的。
3.4编译安装Protocol Buffers编译器来编译自定义的.proto文件
在得到一个.proto文件之后,下一步你就要生成可以读写Student消息(当然也就包括了PhoneNumber消息)的类了。此时你需要运行protocol buffer编译器来编译你的.proto文件。
3.4.1编译安装Protocol Buffers
如果你还没有安装该编译器,下载protobuf源码 ,或直接到github上下载,详情请参照README.md文件中的说明来安装。
To build and install the C++ Protocol Buffer runtime and the Protocol
Buffer compiler (protoc) execute the following:
构建和安装C++ Protocol Buffer runtime和ProProtocol
Buffer compiler (protoc) 需要执行如下命令:
$ ./configure
$ make
$ make check
$ make install- 1
- 2
- 3
- 4
如果上面的命令没有出错,那么恭喜你,你就完成了对ProtoBuf源码的编译和安装的工作。下面我们就可以使用ProtoBuf的编译器protoc对我们的.proto文件啦。
我的make check的结果如下:
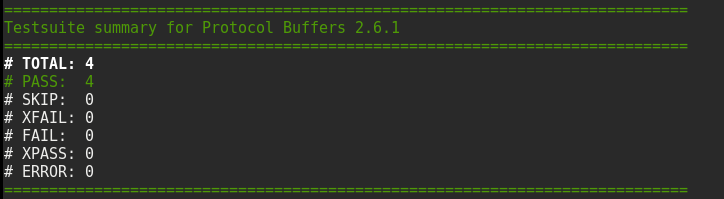
make install注意权限问题,最好使用sudo make install。安装成功之后,使用which protoc就可以查看protoc已经安装成功了。ProtoBuf默认安装的路径在/usr/local,当然我们可以在配置的时候改变安装路径,使用如下命令:
./configure --prefix=/usr- 1
安装成功后,我们执行protoc --version 查看我们的Protocol Buffer的版本,我使用的版本是:libprotoc 2.6.1。
3.4.2编译我们的.proto文件
有了Protocol Buffers的编译器protoc,我们就可以来编译我们自定义的.proto文件来产生对应的消息类,生成一个头文件 ( 定义.proto文件中的消息类 ),和一个源文件(实现.proto文件中的消息类)。
编译方法。指定源目录(即你的应用程序源代码所在的目录——如果不指定的话,就使用当前目录)、目标目录(即生成的代码放置的目录,通常与$SRC_DIR是一样的),以及你的.proto文件所在的目录。命令如下:
protoc -I=$SRC_DIR --cpp_out=$DST_DIR $SRC_DIR/addressbook.proto- 1
因为需要生成的是C++类,所以使用了–cpp_out选项参数——protocol buffers也为其他支持的语言提供了类似的选项参数,如--java_out=OUT_DIR,指定java源文件生成目录。
以上面自定义的student.proto为例,来编译产生我们的student消息类。运行如下命令:
protoc student.proto --cpp_out=./- 1
这样就可以在我指定的当前目录下生成如下文件:
student.pb.h:声明你生成的类的头文件。
student.pb.cc:你生成的类的实现文件。- 1
- 2

protoc的详细用法参见protoc -h。
3.5了解Protocol Buffer API
让我们看一下生成的代码,了解一下编译器为你创建了什么样的类和函数。如果你看了编译器protoc为我们生成的student.pb.h文件,就会发现你得到了一个类,它对应于student.proto文件中写的每一个消息(message)。更深入一步,看看Student类:编译器为每一个字段生成了读写函数。例如,对name,id,email以及phone字段,分别有如下函数:
// required uint64 id = 1;
inline bool has_id() const;
inline void clear_id();
static const int kIdFieldNumber = 1;
inline ::google::protobuf::uint64 id() const;
inline void set_id(::google::protobuf::uint64 value);
// required string name = 2;
inline bool has_name() const;
inline void clear_name();
static const int kNameFieldNumber = 2;
inline const ::std::string& name() const;
inline void set_name(const ::std::string& value);
inline void set_name(const char* value);
inline void set_name(const char* value, size_t size);
inline ::std::string* mutable_name();
inline ::std::string* release_name();
inline void set_allocated_name(::std::string* name);
// optional string email = 3;
inline bool has_email() const;
inline void clear_email();
static const int kEmailFieldNumber = 3;
inline const ::std::string& email() const;
inline void set_email(const ::std::string& value);
inline void set_email(const char* value);
inline void set_email(const char* value, size_t size);
inline ::std::string* mutable_email();
inline ::std::string* release_email();
inline void set_allocated_email(::std::string* email);
// repeated .tutorial.Student.PhoneNumber phone = 4;
inline int phone_size() const;
inline void clear_phone();
static const int kPhoneFieldNumber = 4;
inline const ::tutorial::Student_PhoneNumber& phone(int index) const;
inline ::tutorial::Student_PhoneNumber* mutable_phone(int index);
inline ::tutorial::Student_PhoneNumber* add_phone();
inline const ::google::protobuf::RepeatedPtrField< ::tutorial::Student_PhoneNumber >& phone() const;
inline ::google::protobuf::RepeatedPtrField< ::tutorial::Student_PhoneNumber >* mutable_phone();- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
正如你所看到的,getter函数具有与字段名一模一样的名字,并且是小写的,而setter函数都是以set_前缀开头。此外,还有has_前缀的函数,对每一个单一的(required或optional的)字段来说,如果字段被置(set)了值,该函数会返回true。最后,每一个字段还有一个clear_前缀的函数,用来将字段重置(un-set)到空状态(empty state)。
然而,数值类型的字段id就只有如上所述的基本读写函数,name和email字段则有一些额外的函数,因为它们是string——前缀为mutable_的函数返回string的直接指针(direct pointer)。除此之外,还有一个额外的setter函数。注意:你甚至可以在email还没有被置(set)值的时候就调用mutable_email(),它会被自动初始化为一个空字符串。在此例中,如果有一个单一消息字段,那么它也会有一个mutable_ 前缀的函数,但是没有一个set_ 前缀的函数。
重复的字段也有一些特殊的函数——如果你看一下重复字段phone 的那些函数,就会发现你可以:
(1)得到重复字段的_size(换句话说,这个Person关联了多少个电话号码)。
(2)通过索引(index)来获取一个指定的电话号码。
(3)通过指定的索引(index)来更新一个已经存在的电话号码。
(3)向消息(message)中添加另一个电话号码,然后你可以编辑它(重复的标量类型有一个add_前缀的函数,允许你传新值进去)。
关于编译器如何生成特殊字段的更多信息,请查看文章C++ generated code reference。
关于枚举和嵌套类(Enums and Nested Classes)。
生成的代码中包含了一个PhoneType 枚举,它对应于.proto文件中的那个枚举。你可以把这个类型当作Student::PhoneType,其值为Student::MOBILE和Student::HOME(实现的细节稍微复杂了点,但是没关系,不理解它也不会影响你使用该枚举)。
编译器还生成了一个名为Student::PhoneNumber的嵌套类。如果你看看代码,就会发现“真实的”类实际上是叫做Student_PhoneNumber,只不过Student内部的一个typedef允许你像一个嵌套类一样来对待它。这一点所造成的唯一的一个区别就是:如果你想在另一个文件中对类进行前向声明(forward-declare)的话,你就不能在C++中对嵌套类型进行前向声明了,但是你可以对Student_PhoneNumber进行前向声明。
关于标准消息函数(Standard Message Methods)。
每一个消息(message)还包含了其他一系列函数,用来检查或管理整个消息,包括:
bool IsInitialized() const; //检查是否全部的required字段都被置(set)了值。
void CopyFrom(const Person& from); //用外部消息的值,覆写调用者消息内部的值。
void Clear(); //将所有项复位到空状态(empty state)。
int ByteSize() const; //消息字节大小- 1
- 2
- 3
- 4
- 5
- 6
- 7
关于Debug的API。
string DebugString() const; //将消息内容以可读的方式输出
string ShortDebugString() const; //功能类似于,DebugString(),输出时会有较少的空白
string Utf8DebugString() const; //Like DebugString(), but do not escape UTF-8 byte sequences.
void PrintDebugString() const; //Convenience function useful in GDB. Prints DebugString() to stdout.- 1
- 2
- 3
- 4
- 5
- 6
- 7
这些函数以及后面章节将要提到的I/O函数实现了Message 的接口,它们被所有C++ protocol buffer类共享。更多信息,请查看文章complete API documentation for Message。
关于解析&序列化(Parsing and Serialization)。
最后,每一个protocol buffer类都有读写你所选择的消息类型的函数。它们包括:
bool SerializeToString(string* output) const; //将消息序列化并储存在指定的string中。注意里面的内容是二进制的,而不是文本;我们只是使用string作为一个很方便的容器。
bool ParseFromString(const string& data); //从给定的string解析消息。
bool SerializeToArray(void * data, int size) const //将消息序列化至数组
bool ParseFromArray(const void * data, int size) //从数组解析消息
bool SerializeToOstream(ostream* output) const; //将消息写入到给定的C++ ostream中。
bool ParseFromIstream(istream* input); //从给定的C++ istream解析消息。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
这些函数只是用于解析和序列化的几个函数罢了。请再次参考Message API reference以查看完整的函数列表。
注意:
protocol buffers和面向对象的设计 protocol buffer类通常只是纯粹的数据存储器(就像C++中的结构体一样);它们在对象模型中并不是一等公民。如果你想向生成的类中添加更丰富的行为,最好的方法就是在应用程序中对它进行封装。如果你无权控制.proto文件的设计的话,封装protocol buffers也是一个好主意(例如,你从另一个项目中重用一个.proto文件)。在那种情况下,你可以用封装类来设计接口,以更好地适应你的应用程序的特定环境:隐藏一些数据和方法,暴露一些便于使用的函数,等等。但是你绝对不要通过继承生成的类来添加行为。这样做的话,会破坏其内部机制,并且不是一个好的面向对象的实践。
3.6使用Protocol Buffer来读写消息
下面让我们尝试使用protobuf为我们产生的消息类来进行序列化和反序列的操作。你想让你的Student程序完成的第一件事情就是向Student消息类对象进行 赋值,并且进行序列化操作。然后在从序列化结果进行反序列话操作,解析我们需要的字段信息。具体参考如下示例代码:
//test.cpp
#include <iostream>
#include <string>
#include "student.pb.h"
using namespace std;
int main(int argc, char* argv[]){
GOOGLE_PROTOBUF_VERIFY_VERSION;
tutorial::Student student;
//给消息类Student对象student赋值
student.set_id(201421031059);
*student.mutable_name()="dablelv";
student.set_email("[email protected]");
//增加一个号码对象
tutorial::Student::PhoneNumber* phone_number = student.add_phone();
phone_number->set_number("15813354925");
phone_number->set_type(tutorial::Student::MOBILE);
//再增加一个号码对象
tutorial::Student::PhoneNumber* phone_number1 = student.add_phone();
phone_number1->set_number("0564-4762652");
phone_number1->set_type(tutorial::Student::HOME);
//对消息对象student序列化到string容器
string serializedStr;
student.SerializeToString(&serializedStr);
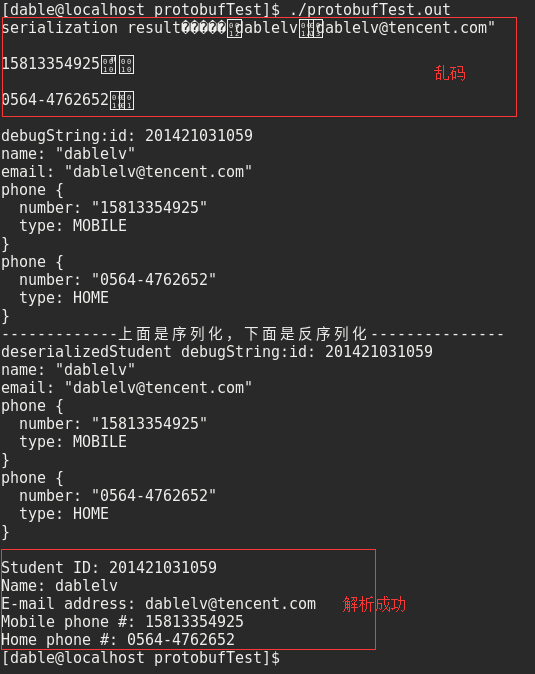
cout<<"serialization result:"<<serializedStr<<endl; //序列化后的字符串内容是二进制内容,非可打印字符,预计输出乱码
cout<<endl<<"debugString:"<<student.DebugString();
/*----------------上面是序列化,下面是反序列化-----------------------*/
//解析序列化后的消息对象,即反序列化
tutorial::Student deserializedStudent;
if(!deserializedStudent.ParseFromString(serializedStr)){
cerr << "Failed to parse student." << endl;
return -1;
}
cout<<"-------------上面是序列化,下面是反序列化---------------"<<endl;
//打印解析后的student消息对象
cout<<"deserializedStudent debugString:"<<deserializedStudent.DebugString();
cout <<endl<<"Student ID: " << deserializedStudent.id() << endl;
cout <<"Name: " << deserializedStudent.name() << endl;
if (deserializedStudent.has_email()){
cout << "E-mail address: " << deserializedStudent.email() << endl;
}
for (int j = 0; j < deserializedStudent.phone_size(); j++){
const tutorial::Student::PhoneNumber& phone_number = deserializedStudent.phone(j);
switch (phone_number.type()) {
case tutorial::Student::MOBILE:
cout << "Mobile phone #: ";
break;
case tutorial::Student::HOME:
cout << "Home phone #: ";
break;
}
cout <<phone_number.number()<<endl;
}
google::protobuf::ShutdownProtobufLibrary();
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
编译上面的测试程序,可使用如下命令:
g++ -o protobufTest.out -lprotobuf test.cpp student.pb.cc- 1
编译成功后,运行protobufTest.out程序,可能会报如下错误:
error while loading shared libraries: libprotobuf.so.9: cannot open shared object file: No such file or directory- 1
原因是protobuf的连接库默认安装路径是/usr/local/lib,而/usr/local/lib 不在常见Linux系统的LD_LIBRARY_PATH链接库路径这个环境变量里,所以就找不到该lib。LD_LIBRARY_PATH是Linux环境变量名,该环境变量主要用于指定查找共享库(动态链接库)。所以,解决办法就是修改环境变量LD_LIBRARY_PATH的值。
方法一:
使用export命令临时修改LD_LIBRARY_PATH,只对当前shell会话有效:
export LD_LIBRARY_PATH=/usr/local/lib:$LD_LIBRARY_PATH- 1
方法二:
或者永久修改,在~/目录下打开.bash_profile文件,设置环境变量如下:
LD_LIBRARY_PATH=/usr/local/lib:$LD_LIBRARY_PATH
export LD_LIBRARY_PATH - 1
- 2
注意Linux下点号开头的文件都是隐藏文件,使用ls -a 可查看指定目录下的所有文件,包括隐藏文件。
方法三:
永久有效的话,可以创建protobuf的动态连接库配置文件/etc/ld.so.conf.d/libprotobuf.conf并包含如下内容:
/usr/local/lib - 1
然后运行动态链接库的管理命令ldconfig。
sudo ldconfig- 1
ldconfig通常在系统启动时运行,而当用户安装了一个新的动态链接库时,就需要手工运行这个命令。
测试程序输出结果:
3.7扩展一个protocol buffer(Extending a Protocol Buffer)
无论或早或晚,在你放出你那使用protocol buffer的代码之后,你必定会想“改进“protocol buffer的定义,即我们自定义定义消息的proto文件。如果你想让你的新buffer向后兼容(backwards-compatible),并且旧的buffer能够向前兼容(forward-compatible),你一定希望如此,那么你在新的protocol buffer中就要遵守其他的一些规则了:
(1)对已存在的任何字段,你都不能更改其标识(tag)号。
(2)你绝对不能添加或删除任何required的字段。
(3)你可以添加新的optional或repeated的字段,但是你必须使用新的标识(tag)号(例如,在这个protocol buffer中从未使用过的标识号——甚至于已经被删除过的字段使用过的标识号也不行)。
(有一些例外情况,但是它们很少使用。)
如果你遵守这些规则,老的代码将能很好地解析新的消息(message),并忽略掉任何新的字段。对老代码来说,已经被删除的optional字段将被赋予默认值,已被删除的repeated字段将是空的。新的代码也能够透明地读取旧的消息。但是,请牢记心中:新的optional字段将不会出现在旧的消息中,所以你要么需要显式地检查它们是否由has_前缀的函数置(set)了值,要么在你的.proto文件中,在标识(tag)号的后面用[default = value]提供一个合理的默认值。如果没有为一个optional项指定默认值,那么就会使用与特定类型相关的默认值:对string来说,默认值是空字符串。对boolean来说,默认值是false。对数值类型来说,默认值是0。还要注意:如果你添加了一个新的repeated字段,你的新代码将无法告诉你它是否被留空了(被新代码),或者是否从未被置(set)值(被旧代码),这是因为它没有has_标志。
3.8优化小技巧(Optimization Tips)
Protocol Buffer 的C++库已经做了极度优化。但是,正确的使用方法仍然会提高很多性能。下面是一些小技巧,用来提升protocol buffer库的最后一丝速度能力:
(1)如果有可能,重复利用消息(message)对象。即使被清除掉,消息(message)对象也会尽量保存所有被分配来重用的内存。这样的话,如果你正在处理很多类型相同的消息以及一系列相似的结构,有一个好办法就是重复使用同一个消息(message)对象,从而使内存分配的压力减小一些。然而,随着时间的流逝,对象占用的内存也有可能变得越来越大,尤其是当你的消息尺寸(译者注:各消息内容不同,有些消息内容多一些,有些消息内容少一些)不同的时候,或者你偶尔创建了一个比平常大很多的消息(message)的时候。你应该自己监测消息(message)对象的大小——通过调用SpaceUsed函数——并在它太大的时候删除它。
(2)在多线程中分配大量小对象的内存的时候,你的操作系统的内存分配器可能优化得不够好。在这种情况下,你可以尝试用一下Google’s tcmalloc。
3.9高级使用(Advanced Usage)
Protocol Buffers的作用绝不仅仅是简单的数据存取以及序列化。请阅读C++ API reference全文来看看你还能用它来做什么。
protocol消息类所提供的一个关键特性就是反射。你不需要编写针对一个特殊的消息(message)类型的代码,就可以遍历一个消息的字段,并操纵它们的值,就像XML和JSON一样。“反射”的一个更高级的用法可能就是可以找出两个相同类型的消息之间的区别,或者开发某种“协议消息的正则表达式”,利用正则表达式,你可以对某种消息内容进行匹配。只要你发挥你的想像力,就有可能将Protocol Buffers应用到一个更广泛的、你可能一开始就期望解决的问题范围上。
“反射”是由Message::Reflection interface提供的。
4.小结
断断续续,历时将近三周的时间,终于坚持完成了本篇blog。最初出于对protobuf的好奇以及对数据对象在传输过程中的序列化和反序列化的不解,所以就尝试去查阅资料,独自了解序列化和反序列化的概念,方法,以及protobuf的用法。本篇主要介绍了protobuf的编译安装,API简介以及对数据的序列化和反序列的简单操作,可供网友参考。
坚持不一定会胜利,至少会看到结果。
参考文献
[1]protobuf官网
[2]protobuf github源码
[3]序列化和反序列化
[4]最常用的两种C++序列化方案的使用心得(protobuf和boost serialization)
[5]Protocol Buffer Basics: C++中文翻译(Google Protocol Buffers中文教程)
[6]Protobuf C++英文教程
[7]LD_LIBRARY_PATH环境变量的设置
[8]LD_LIBRARY_PATH.百度百科
[9] ubuntu下编译protobuf