00. 目录
参考代码下载:02_demo.rar
01. ProtoBuf操作步骤
知道了 ProtoBuf 的作用与支持的数据类型。我们需要知道 ProtoBuf 使用的一般步骤,下面以 C++ 中使用 ProtoBuf 为例来描述使用的一般步骤。
第一步:定义 proto 文件,文件的内容就是定义我们需要存储或者传输的数据结构,也就是定义我们自己的数据存储或者传输的协议。
第二步:编译安装 ProtoBuf 编译器 protoc 来编译自定义的 proto 文件,用于生成 .pb.h 文件(proto 文件中自定义类的头文件)和 .pb.cc(proto文件中自定义类的实现文件)。
第三步:使用 ProtoBuf 的 C++ API 来读写消息。
ProtoBuf C++编程指南:https://developers.google.com/protocol-buffers/docs/cpptutorial
02. 消息格式
syntax = "proto3"; //指定版本信息,不指定会报错
message Person //message为关键字,作用为定义一种消息类型
{
string name = 1; //姓名
int32 id = 2; //id
string email = 3; //邮件
}
消息由至少一个字段组合而成,类似于C语言中的结构体,每个字段都有一定的格式:
格式:数据类型 字段名称 = 唯一的编号标签值;
-
字段名称:protobuf建议以下划线命名而非驼峰式
-
唯一的编号标签:代表每个字段的一个唯一的编号标签,在同一个消息里不可以重复。这些编号标签用与在消息二进制格式中标识你的字段,并且消息一旦定义就不能更改。需要说明的是标签在1到15范围的采用一个字节进行编码,所以通常将标签1到15用于频繁发生的消息字段。编号标签大小的范围是1到229。此外不能使用protobuf系统预留的编号标签(19000 ~19999)。
03. 数据类型
| proto文件消息类型 | C++ 类型 | 说明 |
|---|---|---|
| double | double | 双精度浮点型(64位) |
| float | float | 单精度浮点型(32位) |
| int32 | int32 | 使用可变长编码方式,负数时不够高效,应该使用sint32 |
| int64 | int64 | 使用可变长编码方式,负数时不够高效,应该使用sint64 |
| uint32 | uint32 | 32位无符号整数 |
| uint64 | uint64 | 64位无符号整数 |
| sint32 | sint32 | 使用可变长编码方式,有符号的整型值,负数编码时比通常的int32高效 |
| sint64 | sint64 | 使用可变长编码方式,有符号的整型值,负数编码时比通常的int64高效 |
| fixed32 | uint32 | 总是4个字节,如果数值总是比2^28大的话,这个类型会比uint32高效 |
| fixed64 | uint64 | 总是8个字节,如果数值总是比2^56大的话,这个类型会比uint64高效 |
| sfixed32 | int32 | 总是4个字节 |
| sfixed64 | int64 | 总是8个字节 |
| bool | bool | 布尔类型 |
| string | string | 一个字符串必须是utf-8编码或者7-bit的ascii编码的文本 |
| bytes | string | 可能包含任意顺序的字节数据,处理多字节的语言字符、如中文 |
| enum | enum | 枚举 |
| message | object of class | 自定义的消息类型 |
更多类型请参考:https://developers.google.com/protocol-buffers/docs/encoding
04. 定义 proto 文件
定义 proto 文件就是定义自己的数据存储或者传输的协议格式。
deng@itcast:~/test01/02_demo$ ls
addressbook.proto
deng@itcast:~/test01/02_demo$ cat addressbook.proto
syntax = "proto3";
message Person {
string name = 1;
int32 id = 2; // Unique ID number for this person.
string email = 3;
}
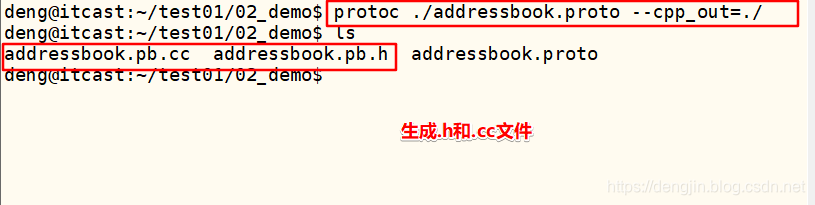
deng@itcast:~/test01/02_demo$ protoc ./addressbook.proto --cpp_out=./
deng@itcast:~/test01/02_demo$ ls
addressbook.pb.cc addressbook.pb.h addressbook.proto
deng@itcast:~/test01/02_demo$
通过查看头文件,可以发现针对每个字段都会大致生成如下几种函数,以name为例:
// string name = 1;
void clear_name();
const std::string& name() const;
void set_name(const std::string& value);
void set_name(std::string&& value);
void set_name(const char* value);
void set_name(const char* value, size_t size);
std::string* mutable_name();
std::string* release_name();
void set_allocated_name(std::string* name);
private:
const std::string& _internal_name() const;
void _internal_set_name(const std::string& value);
std::string* _internal_mutable_name();
说明:
可以看出,对于每个字段会生成一个clear清除函数(clear_name)、set函数(set_name)、get函数(name和mutable_name)。
解释下get函数中的两个函数的区别: 对于原型为const std::string &number() const的get函数而言,返回的是常量字段,不能对其值进行修改。但是在有一些情况下,对字段进行修改是必要的,所以提供了一个mutable版的get函数,通过获取字段变量的指针,从而达到改变其值的目的。
05. 参考
参考博客:https://www.cnblogs.com/royenhome/archive/2010/10/29/1864860.html