一.Beautiful soup安装


二.理解






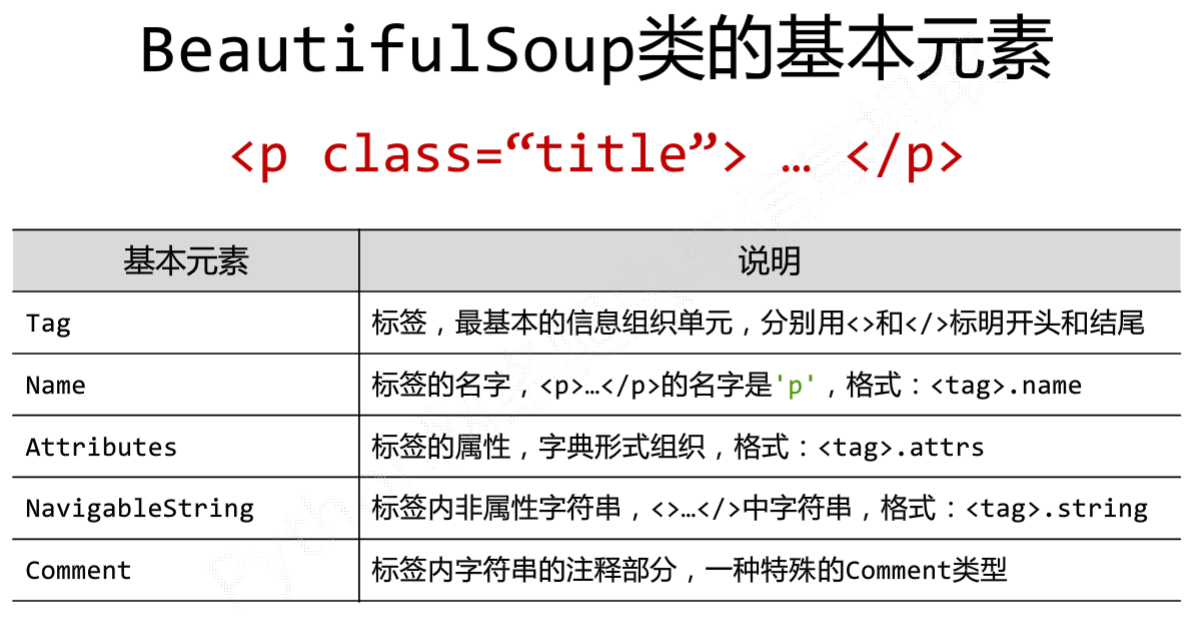
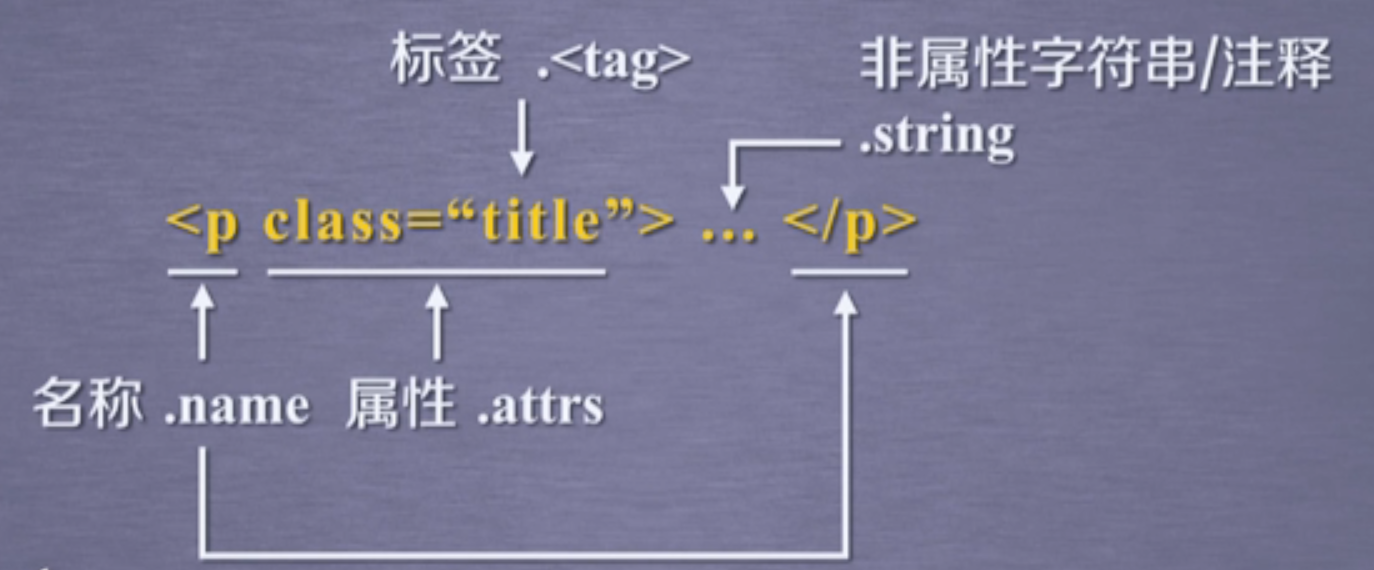
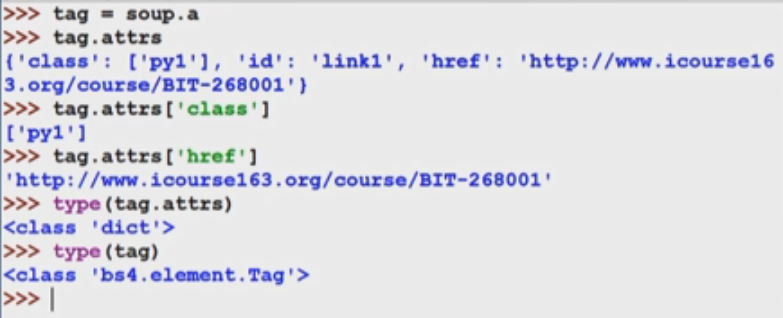
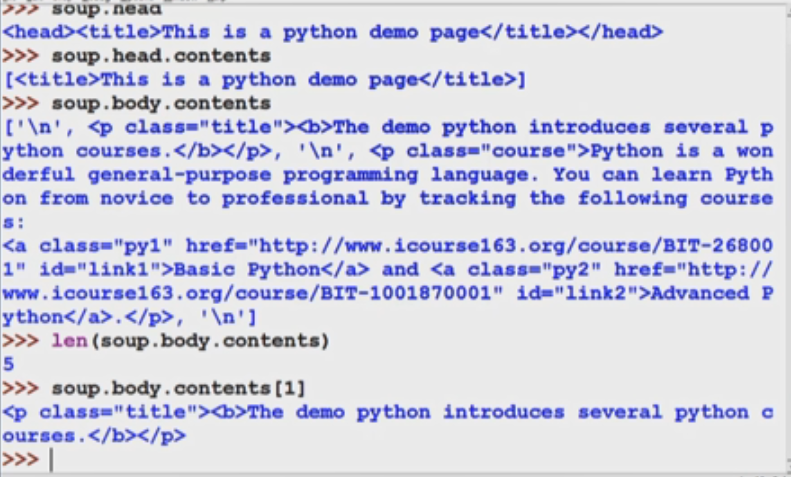
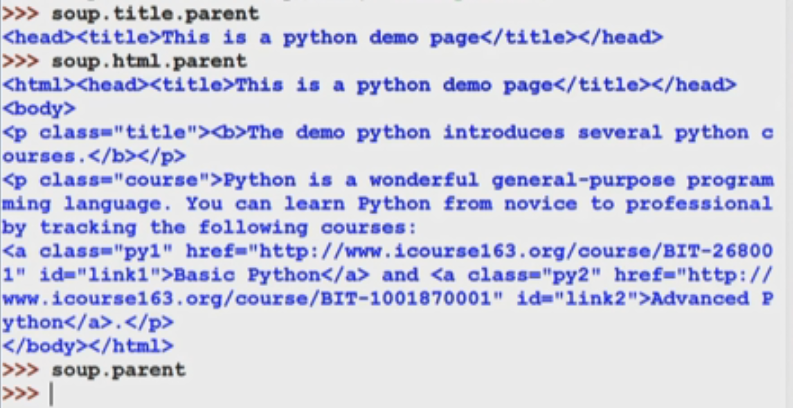
三.页面遍历方法







四.bs4的格式化与编码
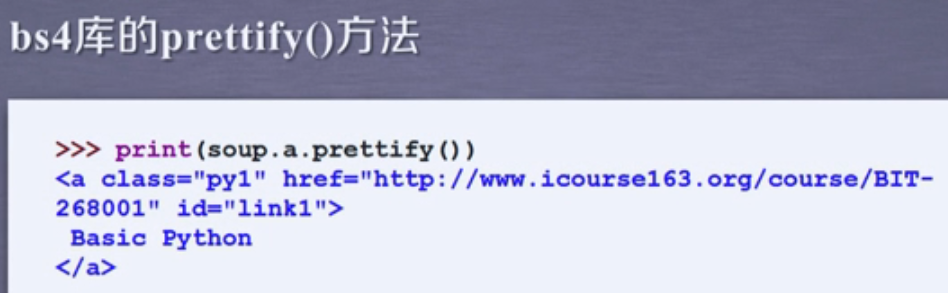 prettify函数能够通过添加缩进使代码更直观。
prettify函数能够通过添加缩进使代码更直观。
五.信息标记


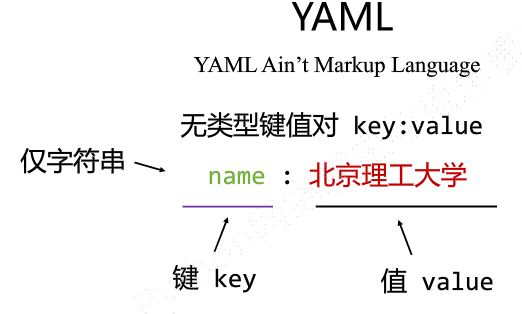
不同语言的信息格式:








实例:








 re为正则表达式库
re为正则表达式库





七.实例:大学排名爬取
1 import requests 2 from bs4 import BeautifulSoup 3 import bs4 4 5 def getHtmlText(url): 6 try: 7 r=requests.get(url,timeout=30) 8 r.raise_for_status() 9 r.encoding=r.apparent_encoding 10 return r.text 11 except: 12 return "" 13 14 def fillUnivList(ulist,html): 15 soup=BeautifulSoup(html,"html.parser") 16 for tr in soup.find('tbody').children:#通过对源代码分析,是从body标签里的tr标签提取内容, 17 if isinstance(tr,bs4.element.Tag): 18 tds=tr('td') 19 ulist.append([tds[0].string,tds[1].string,tds[4].string]) 20 21 def printUnivList(ulist,num): 22 print("{:^10}\t{:^16}\t{:^16}".format("排名","学校名称","总分")) 23 for i in range(num): 24 u=ulist[i] 25 print("{:^10}\t{:^16}\t{:^16}".format(u[0],u[1],u[2])) 26 27 def main(): 28 uinfo=[] 29 url='http://www.zuihaodaxue.cn/zuihaodaxuepaiming2018.html' 30 html=getHtmlText(url) 31 fillUnivList(uinfo,html) 32 printUnivList(uinfo,50) 33 34 main()
1 def printUnivList(ulist,num): 2 textout="{0:^10}\t{1:{3}^16}\t{2:^16}" 3 print(textout.format("排名","学校名称","总分",chr(12288))) 4 for i in range(num): 5 u=ulist[i] 6 print(textout.format(u[0],u[1],u[2],chr(12288)))
格式优化,如果不规定空格填充,默认使用英文空格,中西结合的格式会使得排列很乱
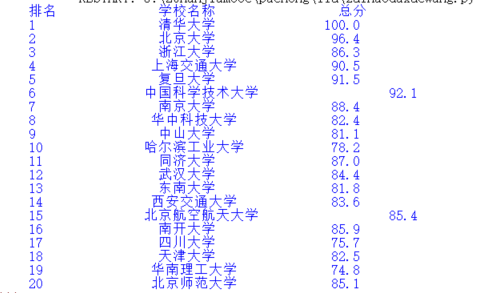

前后对比,这个中文排版问题会一直出现,之后记得就好。