一、第一种(本人验证)
更详细的在:https://blog.csdn.net/zjl477595675/article/details/47310901
1.下载 zookeeper-3.4.6.tar.gz
2.解压压缩包 tar -zxvf zookeeper-3.4.6.tar.gz
3.重命名文件夹zookeeper-3.4.6为zookeeper1
4.同样的步骤执行2遍
5.cd zookeeper1/conf/
6.vi zoo.cfg
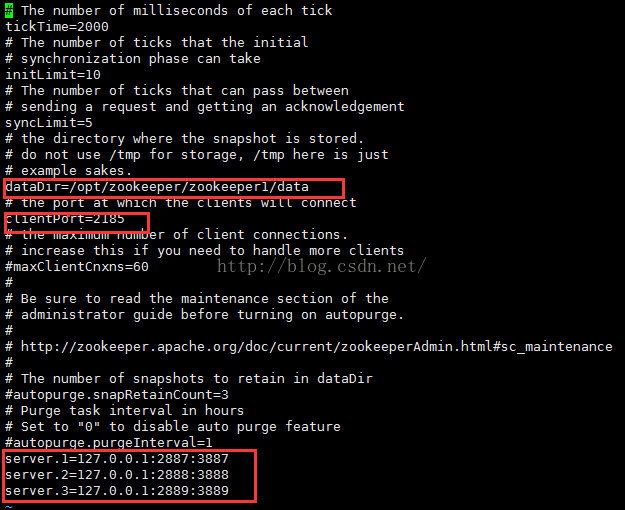
7.修改 Zookeeper 保存数据的目录-------- dataDir=/opt/zookeeper/zookeeper1/data 。
8.客户端连接 Zookeeper 服务器的端口,Zookeeper 会监听这个端口,接受客户端的访问请求------ clientPort=2185 。
9。添加server.X=A:B:C 其中X是一个数字, 表示这是第几号server. A是该server所在的IP地址. B配置该server和集群中的leader交换消息所使用的端口. C配置选举leader时所使用的端口. 由于配置的是伪集群模式, 所以各个server的B, C参数必须不同。
server.1=127.0.0.1:2887:3887
server.2=127.0.0.1:2888:3888
server.3=127.0.0.1:2889:3889
10.进入data目录,touch myid文件,vi myid ,写入1。
11.重复操作两次,注意修改dataDir=/opt/zookeeper/zookeeper2/data 、dataDir=/opt/zookeeper/zookeeper3/data ; clientPort=2186, clientPort=2187;myid 写入2,myid写入3。
12 分别进入 zookeeper1下的bin目录。
13启动zookeeper1 ./zkServer.sh start(注:bin目录下由日志文件zookeeper.out,起不了的话可以在这里看错误原因)。
14分别启动zookeeper2,zookeeper3。
15查看是否启动成功(集群中所有zookeeper启动了才能查看) ./zkServer.sh status。

二、第二种
zookeeper伪分布安装
关于为何zookeeper集群集群必须至少3个节点机器的原因,是因为zookeeper集群提供服务的机制决定的。zookeeper集群认为超多半数集群内部机器正常,就认为集群是正常的,可对外提供协调服务。
1、安装jdk,在系统变量添加JAVA_HOMEvi /etc/profile
export JAVA_HOME=/usr/local/jdk
export PATH=$PATH:$JAVA_HOME/bin
保存后刷新文件,使之立刻生效
source /etc/profile
验证是否生效
java -version
2、download zookeeper安装程序,解压安装包到安装目录下
地址http://zookeeper.apache.org/releases.html
3、配置ZK_HOME环境变量
vi /etc/profile
export ZK_HOME=/usr/local/zookeeper
export PATH=$PATH:$JAVA_HOME/bin:$ZK_HOME
保存后刷新文件,使之立刻生效
source /etc/profile
验证是否生效
zkServer.sh status
4、添加修改zookeeper配置文件
/etc/usr/local/zookeeper/conf
cp zoo_sample.cfg zoo.cfg
vi zoo.cfg
在zoo.cfg中添加配置参数,下面是必须要配置的参数
tickTime=2000
dataDir=/usr/local/data/zookeeper/
dataLogDir=/usr/local/data/zookeeper/
clientPort=2181
initLimit=5
syncLimit=2
server.1=zoo1:2888:3888
server.2=zoo2:2888:3888
server.3=zoo3:2888:3888
tickTime为心跳会话超时世间,毫秒单位,如果超过该时间心跳监测没有回应(ack),判定该节点已死。
initLimit zookeeper follow和leader进行数据同步容许的最大时长,更具业务需要可调整该参数。
syncLimit 容许zookeeper follow 数据落后leader的最大数据
dataDir zookeeper存储内存数据快照的本地磁盘位置。zookeeper在运行期间会将数据存储在内存中,保证了访问的时效性。
clientPort 监听客户端连接的端口;也即开放给客户连接的端口
dataLogDir 配置zookeeper存储事务日志的地方,不配置默认使用dataDir配置。目的是为了将事务日志和内存数据镜像分开存储
server.x 用户配置zookeeper集群服务器主机列表配置。配置规则server.x=[hostname]:nnnnn[:nnnnn], etc
第一个参数为机器主机名,后面两个为机器端口参数,例如2888用于和leader的通讯,3888为用于集群leader的选举,
注意x为集群中该机器的编号(集群中唯一),该配置需要和dataDir目录下文件myid中的内容一致,为数字。集群启动的时候
会去dataDir目录下查找myid,检查编号是否一致。
5、进入dataDir创建名为myid的文件,内容为上面server.x配置的对应的编号
6、由于是伪分布式部署。就是在一台服务器上面启动多个zookeeper实例,模拟组成集群。所以上面zoo.cfg配置要注意,例如你模拟3台机器,
你就需要配置3个zoo.cfg文件,名称可以任意,下面启动zookeeper实例的时候你指定使用的配置文件即可。注意伪分布的时候clientPort需要不同,
server.x的hostname可以是localhost或者是主机名(如果你已经配置的话),但是后面的端口必须不一样。例如你可以配置为;
server.1=yarn001:2888:3888
server.2=yarn001:2889:3889
server.3=yarn001:2890:3890
7、启动zookeeper实例
准备工作做好后,启动.我们在启动脚本的时候,制定启动脚本使用的cfg配置文件的名称和位置(依据你自己配置的位置为准,如果是和默认的cfg在统一目录,
你可以如下启动即可)zkServer.sh start zoo.cfg
zkServer.sh start zoo2.cfg
zkServer.sh start zoo3.cfg
8、验证是否启动成功,jps指令,会发现3个QuorumPeerMain进程(个数依据你的实例数配置)
[root@yarn001 conf]# jps
5055 Jps
4670 QuorumPeerMain
2606 -- process information unavailable
4876 ZooKeeperMain
4650 QuorumPeerMain
4686 QuorumPeerMain
[root@yarn001 conf]#
9、验证leader和follow
zkServer.sh status zoo.cfgzkServer.sh status zoo2.cfg
zkServer.sh status zoo3.cfg