前言
学过Python爬虫的都知道,Chrome浏览器自带的“检查”功能很强大(别反驳(’∇’)シ┳━┳我知道其他浏览器也行,但我是Chrome的忠实粉)
利用Chrome浏览器配合Python可拿到网页上我们能看见的所有数据(我肯定是还没有到那个境界的~)
今天就以我很喜欢的一首歌为例,其他数据的获取基本都是同样的套路
快速拿到网页中的音乐
如下,百度直接搜索“南山南”

点击进入子页后,在子页空白处右击选择 “检查” 看到如下页面
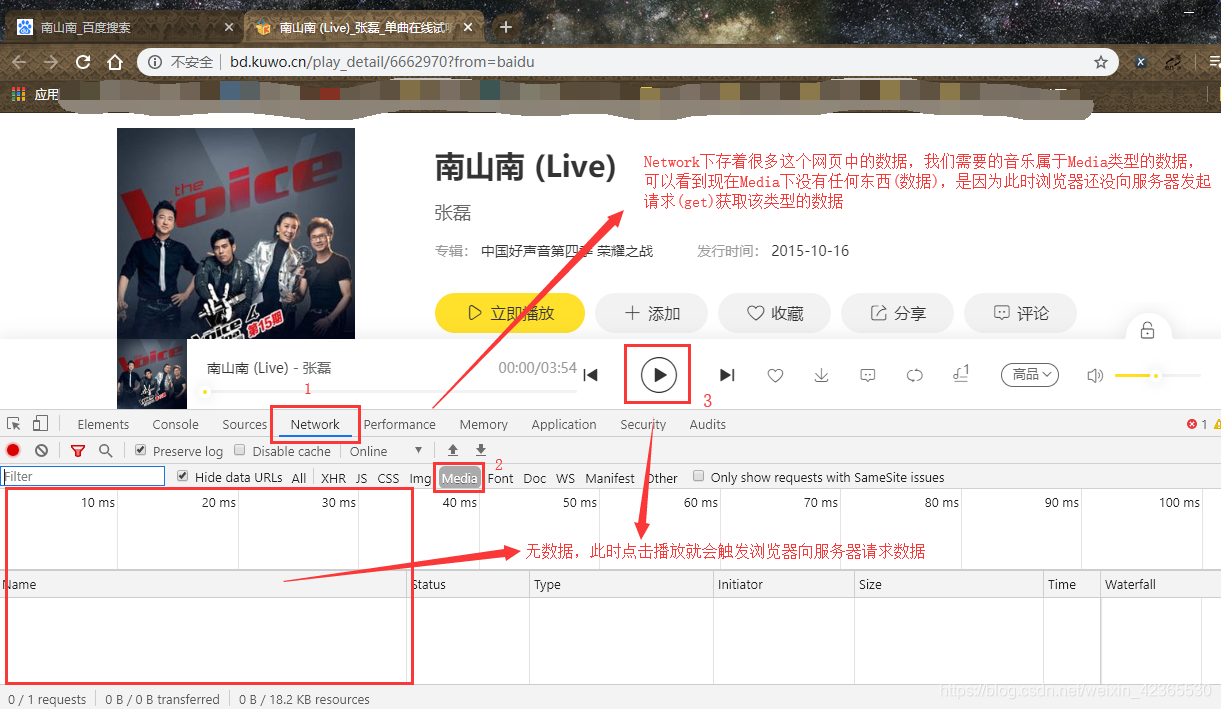
浏览器发起请求后就有如下数据
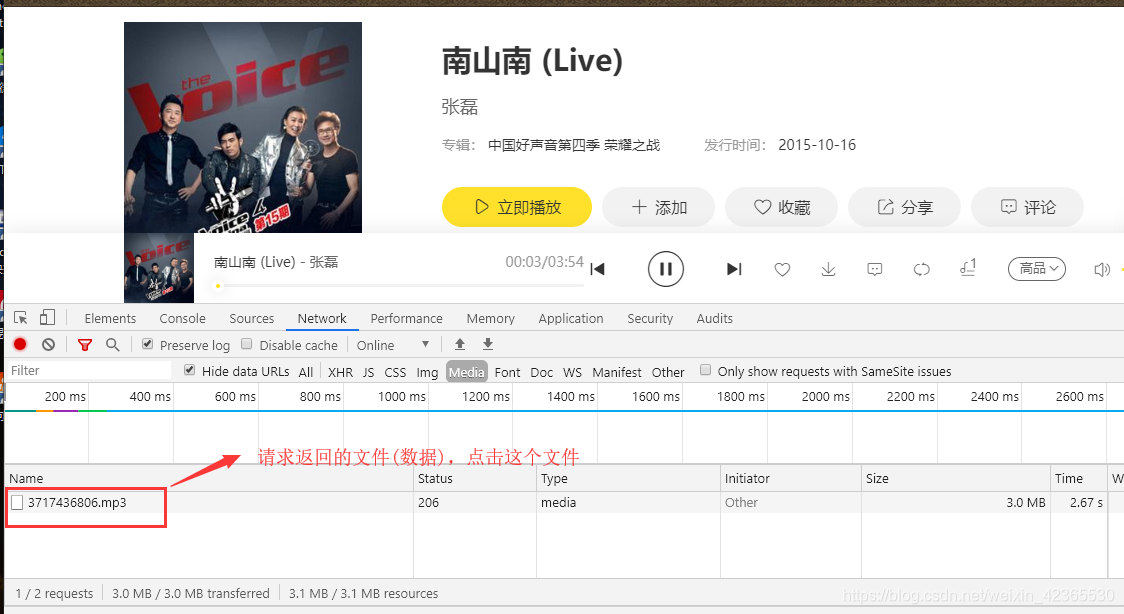
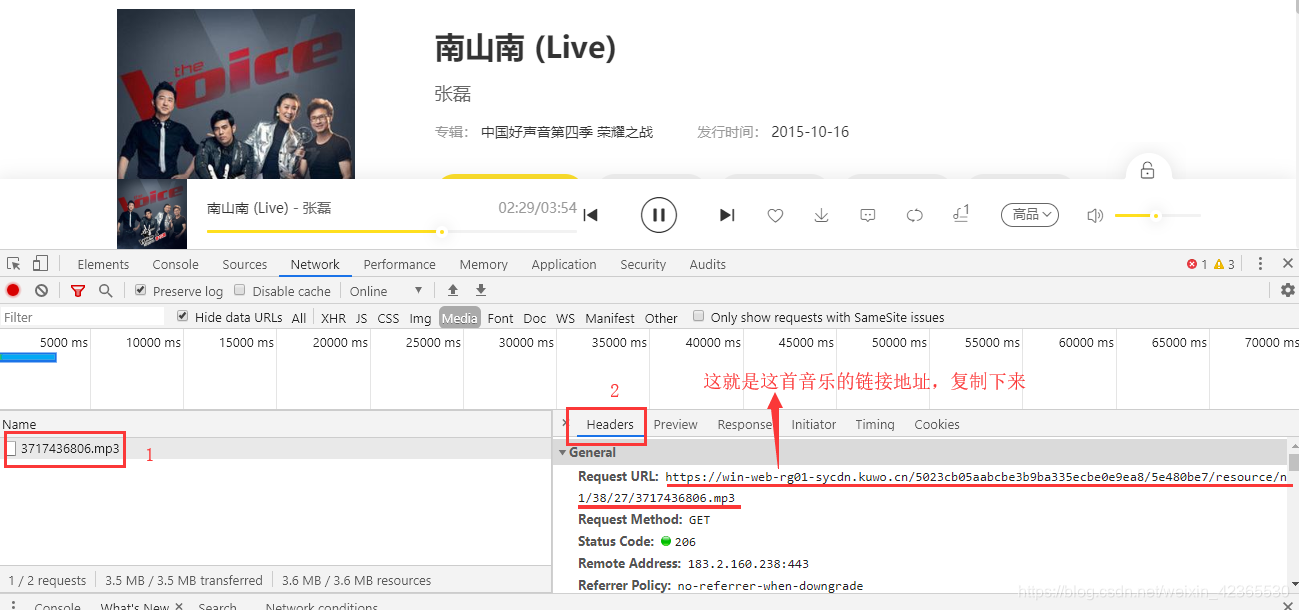
将复制的链接在浏览器中打开即可
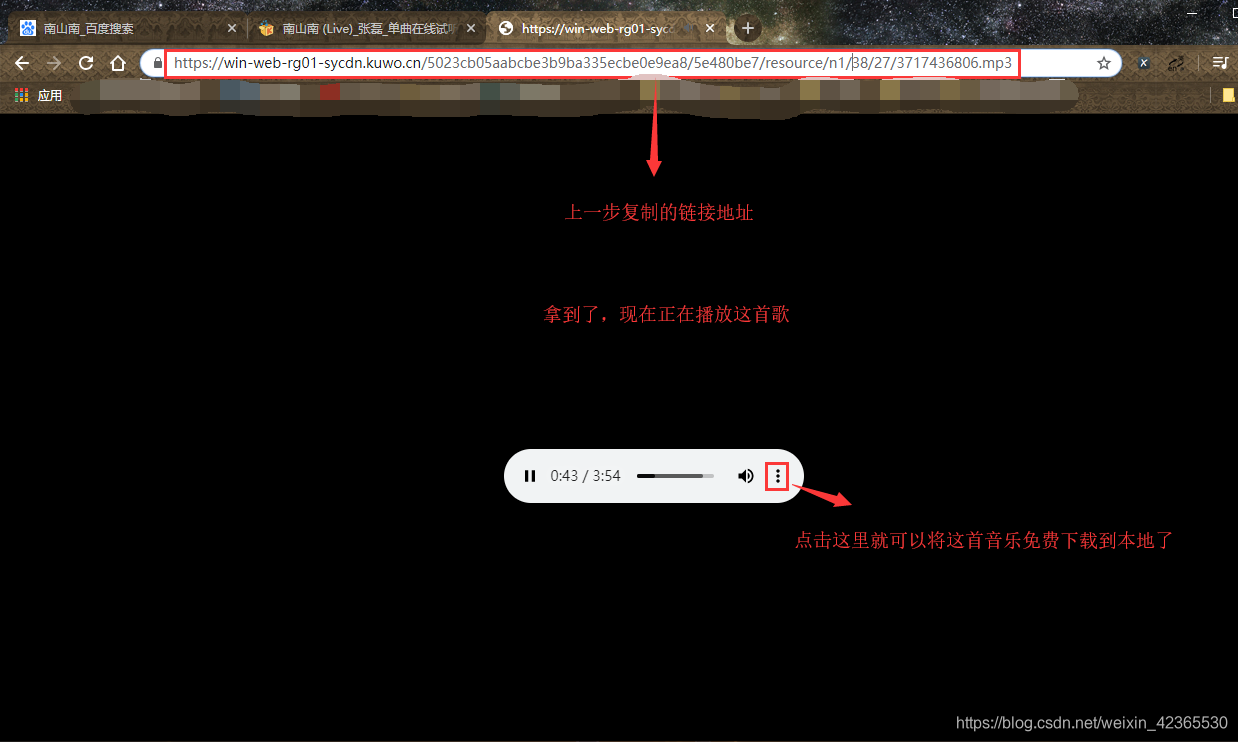
这是比较理想的状态,一下就拿到了,其他不那么理想就拿到的数据,就要花一点时间去查找了(有经验了就很快了),其他数据的获取大致思路步骤都是这样,向服务器发请求——>筛选查找,有加密或有反爬处理的数据就不那么容易拿到了
分享一小段歌词:
他不再和谁谈论相逢的孤鸟
因为心里早已荒无人烟
他的心里再装不下一个家
做一个只对自己说谎的哑巴
他说你任何为人称道的美丽
不及他第一次遇见你
时光苟延残喘
无可奈何
如果所有土地连在一起
走上一生
只为拥抱你
喝醉了他的梦
晚安
关于博主
一个粗略的小技巧适合小白,纯属在家闲,又不能骂网友(●—●)
“武汉加油!”“中国加油!”
https://blog.csdn.net/weixin_42365530/article/details/104084800
