本文利用了软件源码的结构化信息进行漏洞的挖掘,结合了静态分析,鲁棒的分析和机器学习的方法。本文主要包含4个步骤:
- 抽象语法树的抽取
- 向向量空间映射
- 结构化样式的识别
- 漏洞推断
原理
鲁棒的AST抽取
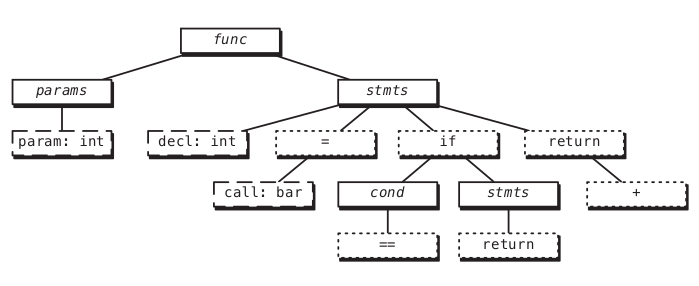
我们利用一个基于island grammars的C/C++的鲁棒的分析器来抽取程序的抽象语法树(AST),这一分析器无需验证代码的语法,而是旨在从代码中抽取尽可能多的信息。
对于我们的分析,我们从语法树中识别不同类型的结点。我们将所有与参数类型,声明类型和函数调用作为API结点,因为它们定义了代码是如何与其他函数和库交互的。并且我们将所有描述语法元素的结点作为语法结点。例如对于下面的代码,抽象语法树如下图所示,其中API结点是虚线表示,而语法结点是由小圆点连线表示。
int foo(int y)
{
int n = bar(y);
if(n == 0)
return 1;
return (n + y);
}
将AST映射到向量空间
为了让机器学习方法处理我们抽取的AST信息,需要将它们映射到向量空间。为构建这一映射,我们利用子树
描述代码基中每个函数的AST。特别地,我们利用以下三种定义进行实验:
1. API结点。这一方法中集合
仅仅由AST中所有的API结点组成,而不考虑其他结点。
2. API子树。这一方法中集合
被定义为代码基中包含至少一个API结点的深度为D的所有子树组成,其中所有非API结点都用占位符(空结点)来代替。
3. API/S子树。这一方法中集合
由所有深度为D的,包含至少一个API结点或语法结点的子树组成。同样地,非API或语法结点用占位符来代替。
基于
的定义,我们能够从不同的角度审视我们代码基中的函数。如果我们只考虑API结点,我们抽取的特征是浅层的,并且只抓住了函数的接合(interfacing);如果我们选择API子树,我们利用了API结点和结点的结构信息来描述函数;如果我们采用API/S子树,我们就得到了一个既与API使用有关,又与函数中语法元素有关的视角。
下面我们固定D为3,这样能够在浅层表示和过于复杂的子树之间取得一个平衡。
基于集合
,我们可以定义一个映射
,将一个语法树映射到向量空间,向量空间中的一维表示
中的一个元素。这个映射如下:
其中 指代代码基中所有函数的语法树, 返回x中出现的所有子树 ,为方便起见,我们将所有的语法树向量存储在矩阵M中,M的一个单元定义为 , 表示TF-IDF权重。这一权重确保了频繁出现的子树对函数相似性有很小的影响。
识别结构化模式
通过计算向量间的距离,在之前步骤中得到的表示已经能够对函数进行比较。然而我们还不能利用更加相关的模式去比较函数。例如一个服务器应用的代码基可能包含于网络通信,消息解析和线程调度相关的函数,因此比起单纯看AST的子树,把函数功能加进来一起比较效果可能更好。
我们可以通过应用潜在语义分析来解决这一问题。潜在语义分析是自然语言处理中常用的技术,用来从文本中识别话题。每个话题用一系列相关单词组成。在我们的设定中,这些话题与代码基中的功能类型相关,并且相关向量与和这些功能相关的子树联系在一起。
潜在语义分析通过确定向量空间的主方向来识别话题,也就是通过代码基的AST中频繁出现在一起的子树。我们将这些与子树相关的方向叫做结构化模式。我们利用矩阵的奇异值分解来进行潜在语义分析,也就是说矩阵
被分解为
三个矩阵。
这种分解提供了丰富的信息,并且包含了矩阵M中的结构化模式。
1. 矩阵U的d列表示向量空间的d个方向,并且定义了代码基中识别出的子树的d个结构化模式。
2. 矩阵 包含M的奇异值。此值代表了这一方向的方差,并且告诉我们这d个结构化模式的重要程度。
3. 矩阵V的每行代表每个AST的表示,每个AST用矩阵U中的d个结构化模式混合描述。
漏洞推断
在矩阵分解后,下面三个操作能够帮助程序分析人员分析代码:
- 漏洞推断。矩阵V的每一行都利用结构化模式的混合描述了一个函数,因此,寻找在结构上相似的函数可以直接通过计算行间的余弦距离来进行。
- 代码基分解。
- 异常函数检测。
实验评估
我们选择了4个开源项目LibTIFF,FFmpeg,Pidgin和Asterisk作为目标项目,对每一个项目,选择了一个已知漏洞作为漏洞推断的开始。
数量评估
第一个实验我们研究在已知某个漏洞的情况下,我们的方法识别与之有共同点的函数的能力。为进行可控的实验,我们人工检查了每个代码基,并且手动标注了所有候选函数,也就是所有可能含有相同漏洞的函数。
对每个代码基,我们都应用了我们的方法,并且标出了标注的函数的排名。我们分别利用API结点,API子树和API/S子树进行实验,并且利用了不同的结构化模式数量进行实验。评级性能的指标选择了查出所有候选函数所需要检查的代码量。

上图是FFmpeg和LibTIFF的实验结果,可以看出API子树明显优于其他两种方法。

上表是四个项目分别查到75%,90%,100%时需要检查的函数数量。
质量评估:案例分析
FFmpeg
数组索引缺陷在媒体库中是一种常见的问题。在这一案例中,我们利用FLIC媒体文件中一个已知的漏洞发现了三个相似的漏洞,其中两个是以前没有发现的。
原始漏洞视频解码过程包括对图像数据的处理。图像框架包含编码的像素以及图像的元数据,例如宽度和偏置值等。解码器通常会为其分配一个数组,然后利用视频提供的偏置值,用图像数据填充数组。因此在上下文中必须对偏置值小心验证。而在下图代码中没有这类的验证。

关键的写数组的一步在32行,其中用户提供的整数line_packets的低位被写进数组pixels的指定位置。被人忽视的是数组的偏置取决于y_ptr和s->frame.linesize[0],这两个数都能够被攻击者控制,并且没有对于偏置是否还在数组内的检测。
推断利用我们的方法得到的排名如图2,此排名从6941个函数中挑选出了30个与目标函数最相似的函数。候选函数已经用浅阴影标出,而找出的漏洞用深色阴影标出。

首先我们看出30个函数中20个是候选函数,然后可以看出4个有漏洞的函数,对应以下3个漏洞:
1. flic_decode_frame_15_16BPP,它与原始漏洞位于同一个文件中,并且也是处理FLIC视频框架。此漏洞已被FFmpeg开发者发现,我们的方法为其返回了一个98%的相似度。
2. 函数vmd_decode
3. 函数vqa_decode_chunk