概述
最近在看hbase源码,里面有对象占用内存大小的计算。正好笔记记录一下。
一般来说,int占4个字节,long占8个字节,等等。但是对象在队中的存储不止其包含的字段所占用的空间,还包括对象头,对齐填充等信息。接下来就结合hbase源码分析一下对象在堆中的存储情况。
原生类型(primitive type)的内存占用
| 类型 | 占用空间 |
|---|---|
| boolean | 在数组中占1个字节,单独使用时占4个字节 |
| byte | 1 |
| short | 2 |
| char | 2 |
| int | 4 |
| float | 4 |
| long | 8 |
| double | 8 |
boolean占用内存空间说明
《Java虚拟机规范》一书中的描述:“虽然定义了boolean这种数据类型,但是只对它提供了非常有限的支持。在Java虚拟机中没有任何供boolean值专用的字节码指令,Java语言表达式所操作的boolean值,在编译之后都使用Java虚拟机中的int数据类型来代替,而boolean数组将会被编码成Java虚拟机的byte数组,每个元素boolean元素占8位”。这样我们可以得出boolean类型占了单独使用是4个字节,在数组中又是1个字节。
那虚拟机为什么要用int来代替boolean呢?为什么不用byte或short,这样不是更节省内存空间吗。大多数人都会很自然的这样去想,我同样也有这个疑问,经过查阅资料发现,使用int的原因是,对于当下32位的处理器(CPU)来说,一次处理数据是32位(这里不是指的是32/64位系统,而是指CPU硬件层面),具有高效存取的特点。
另外也解决了伪共享问题,boolean类型的数据不会因为占用空间小而与其他数据类型的数据一起使用,注意这一点是我个人的一个猜测。欢迎来辩。
对象分布基本概念
如图,java对象在内存中占用的空间分为3类,
- 对象头(Header);
- 实例数据(Instance Data);
- 对齐填充(Padding)。
而我们常说的基础数据类型大小主要是指第二类实例数据。
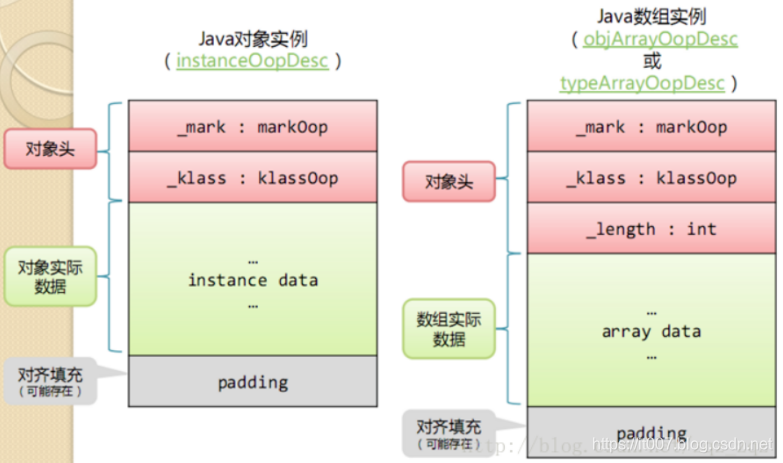
对象头
上图中可以看到,对象头分为三个部分:
- Mark Word
- 指向类的指针
- 数组长度(只有数组对象才有)
Mark Word
Mark Word记录了对象和锁有关的信息,当这个对象被synchronized关键字当成同步锁时,围绕这个锁的一系列操作都和Mark Word有关。
Mark Word在32位JVM中的长度是32bit,在64位JVM中长度是64bit。
Mark Word在不同的锁状态下存储的内容不同,在32位JVM中是这么存的:

其中无锁和偏向锁的锁标志位都是01,只是在前面的1bit区分了这是无锁状态还是偏向锁状态。
JDK1.6以后的版本在处理同步锁时存在锁升级的概念,JVM对于同步锁的处理是从偏向锁开始的,随着竞争越来越激烈,处理方式从偏向锁升级到轻量级锁,最终升级到重量级锁。
JVM一般是这样使用锁和Mark Word的:
1,当没有被当成锁时,这就是一个普通的对象,Mark Word记录对象的HashCode,锁标志位是01,是否偏向锁那一位是0。
2,当对象被当做同步锁并有一个线程A抢到了锁时,锁标志位还是01,但是否偏向锁那一位改成1,前23bit记录抢到锁的线程id,表示进入偏向锁状态。
3,当线程A再次试图来获得锁时,JVM发现同步锁对象的标志位是01,是否偏向锁是1,也就是偏向状态,Mark Word中记录的线程id就是线程A自己的id,表示线程A已经获得了这个偏向锁,可以执行同步锁的代码。
4,当线程B试图获得这个锁时,JVM发现同步锁处于偏向状态,但是Mark Word中的线程id记录的不是B,那么线程B会先用CAS操作试图获得锁,这里的获得锁操作是有可能成功的,因为线程A一般不会自动释放偏向锁。如果抢锁成功,就把Mark Word里的线程id改为线程B的id,代表线程B获得了这个偏向锁,可以执行同步锁代码。如果抢锁失败,则继续执行步骤5。
5,偏向锁状态抢锁失败,代表当前锁有一定的竞争,偏向锁将升级为轻量级锁。JVM会在当前线程的线程栈中开辟一块单独的空间,里面保存指向对象锁Mark Word的指针,同时在对象锁Mark Word中保存指向这片空间的指针。上述两个保存操作都是CAS操作,如果保存成功,代表线程抢到了同步锁,就把Mark Word中的锁标志位改成00,可以执行同步锁代码。如果保存失败,表示抢锁失败,竞争太激烈,继续执行步骤6。
6,轻量级锁抢锁失败,JVM会使用自旋锁,自旋锁不是一个锁状态,只是代表不断的重试,尝试抢锁。从JDK1.7开始,自旋锁默认启用,自旋次数由JVM决定。如果抢锁成功则执行同步锁代码,如果失败则继续执行步骤7。
7,自旋锁重试之后如果抢锁依然失败,同步锁会升级至重量级锁,锁标志位改为10。在这个状态下,未抢到锁的线程都会被阻塞。
指向类的指针
该指针在32位JVM中的长度是32bit,在64位JVM中长度是64bit。
Java对象的类数据保存在方法区(java8以后在元数据区)。
数组长度
只有数组对象保存了这部分数据。
该数据在32位和64位JVM中长度都是32bit。
实例数据
我们在java类中定义的属性。
对齐填充
HotSpot的对齐方式为8字节对齐。
8字节填充的含义也就是不足8字节(或8字节的倍数)则将其填充至8字节(或8字节的倍数,这里指的是大于当前值的最小一个8的倍数)。如:
| 原始长度 | 8字节对齐后长度 |
|---|---|
| 6 | 8 |
| 7 | 8 |
| 8 | 8 |
| 9 | 16 |
| 10 | 16 |
我们来看一下hbase的计算对齐填充后长度的算法:
/**
* Aligns a number to 8.
* @param num number to align to 8
* @return smallest number >= input that is a multiple of 8
*/
public long align(long num) {
//The 7 comes from that the alignSize is 8 which is the number of bytes
//stored and sent together
return ((num + 7) >> 3) << 3;//????
}
这里采用的是二进制位运算算法,位运算在计算机内是性能最高的算法,所以在阅读开源软件时,会大量看到二进制位运算。
8字节填充的长度计算其实很简单,将数值先转为2进制,然后将倒数第四位置为1,如果本来是1则不变。然后将后三位置为0即可。
以26为例,26的二进制表述为11010,那么如何才能将倒数第四位置为1呢?上面算法中加上7,即可以完成进位操作,7是比8小的最大的一个数,二进制是111。然后进位操作以后,如何清除后面的三位置为0呢?简单,右移3位在左移3位即可完成。这也就是上述算法的实现原理。
指针压缩
不压缩时指针占8字节。在64位开启指针压缩的情况下 -XX:+UseCompressedOops,存放Class指针的空间大小是4字节。
对象头占用空间总结
- 在32位系统下,存放Class指针的空间大小是4字节,MarkWord是4字节,对象头为8字节。
- 在64位系统下,存放Class指针的空间大小是8字节,MarkWord是8字节,对象头为16字节。
- 在64位开启指针压缩的情况下 -XX:+UseCompressedOops,存放Class指针的空间大小是4字节,MarkWord是8字节,对象头为12字节。
- 如果对象是数组,那么额外增加4个字节。
hbase源码分析–对象占用空间计算
这里先简单介绍一下下面示例的背景。
以hbase 读取wal日志文件输出为例,里面计算了对象占用堆内存大小情况(里面的total_size_sum和edit heap size就是指对象占用空间的就算结果):
{
"sequence": 15,
"region": "c06475acdfec83fd5a6bf6d06c796bd1",
"actions": [
{
"qualifier": "HBASE::FLUSH",
"vlen": 103,
"row": "\\x00",
"family": "METAFAMILY",
"value": "\\x08\\x00\\x12\\x02t2\\x1A c06475acdfec83fd5a6bf6d06c796bd1 \\x0E*\\x06\\x0A\\x010\\x12\\x01023t2,,1574775527767.c06475acdfec83fd5a6bf6d06c796bd1.",
"timestamp": 1574840582064,
"total_size_sum": 200
}
],
"table": {
"name": "dDI=",
"nameAsString": "t2",
"namespace": "ZGVmYXVsdA==",
"namespaceAsString": "default",
"qualifier": "dDI=",
"qualifierAsString": "t2",
"systemTable": false,
"nameWithNamespaceInclAsString": "default:t2"
}
}
edit heap size: 240
position: 283
给出对象的java代码:
public class KeyValue implements ExtendedCell, Cloneable {
protected byte [] bytes = null; // an immutable byte array that contains the KV
protected int offset = 0; // offset into bytes buffer KV starts at
protected int length = 0; // length of the KV starting from offset.
private long seqId = 0;
//省略其他代码
}
背景:byte数组内存储的实际字节大小为146。
那么根据上面第一节的描述,KeyValue对象占用,情况为:
对象头:8(Mark Word)+4(指向类的指针,启用了压缩,所以指针占4字节,下同)=12
byte[] 数组对象头:8(Mark Word)+4(指向类的指针) + 4(数组长度,占4字节)=16
keyvalue大小 = 12(KeyValue对象头) + 4(bytes属性对byte[]数组引用) + 4(int类型 offset) + 4(int类型 length ) + 8(long类型 seqId )=32
byte数组字节实际长度:146+16=162. byte数组是一个独立的对象,所以需要对齐填充。162需要对齐填充,填充结果为 168
固total_size_sum =
keyvalue大小 + bytes数组大小 = 32 + 168(byte[] 数组对象实际占用存储空间) = 200
edit heap size = 240 是统计的WALEdit ,源码在下面。cells 是一个ArrayList,所以在计算的时候,除了上面的200字节,还要加上ArrayList占用的空间。计算方式跟上面一样。
public class WALEdit implements HeapSize {
private ArrayList<Cell> cells = null; // KeyValue是Cell的实现类
}
由于不同的JVM实现,或者不同的机器,不同的启动参数,都可能造成实际占用空间不同,所以需要再实际运行过程中统计真实的占用情况,而不是简单的使用上面的公式计算。
在hbase中有专门统计对象大小的工具类ClassSize:
REFERENCE = memoryLayout.oopSize();
OBJECT = memoryLayout.headerSize();
ARRAY = memoryLayout.arrayHeaderSize();
ARRAYLIST = align(OBJECT + REFERENCE + (2 * Bytes.SIZEOF_INT)) + align(ARRAY);
//headerSize源码:
private static class UnsafeLayout extends MemoryLayout {
@SuppressWarnings("unused")
private static final class HeaderSize {
private byte a;
}
public UnsafeLayout() {
}
@Override
int headerSize() {
try {//这里使用Unsafe本地方法,来获取对象中第一个元素的偏移量。
return (int) UnsafeAccess.theUnsafe.objectFieldOffset(
HeaderSize.class.getDeclaredField("a"));
} catch (NoSuchFieldException | SecurityException e) {
LOG.error(e.toString(), e);
}
return super.headerSize();
}
//省略其他代码
}
ObjectFieldOffSet
JAVA中对象的字段的定位可能通过staticFieldOffset方法实现,该方法返回给定field的内存地址偏移量,这个值对于给定的filed是唯一的且是固定不变的。
第一个属性之前的空间也就是对象头占用的空间。以此来判断对象的大小情况更加准确一些。
其他的也是采用类似运行时动态获取占用空间的方式,具体可以阅读hbase源码查看。
end.
