1 概述
- 数据结构是数据元素的集合或者数据对象之间的关系和构造方法
Data_Structure = (D,R)
D是数据元素的集合,R是该集合中所有元素之间的关系的有限集合 - 数据逻辑结构:反映数据元素之间的逻辑关系的结构(前后件关系,与存储位置无关)
- 数据存储结构:顺序,链接,索引,散列
数据逻辑结构

2 线性表
N个元素的有限序列,N>=0
2.1 顺序存储结构:顺序表
- 依次存储线性表各个元素
- 节省存储空间
- 插入删除需要移动大量元素
细分
- 带头结点:头结点为了操作的统一和方便,不放数据(可放链表的长度),此结点不能算作链表长度值

- 不带头结点
2.2 链式存储结构:链表
- 有数据域与指针域两个部分组成,增加了存储空间
- 物理不一定相邻
- 插入删除灵活
- 查找慢
- 簇4随机分配,数据删除后覆盖率低,恢复的可能性高
1)分类
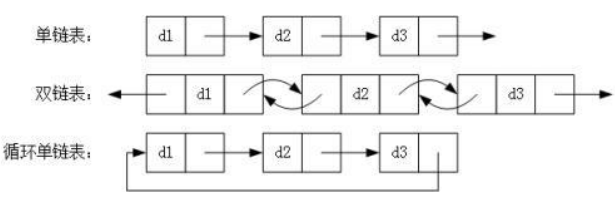
2)链表的操作
插入和删除结点
双链表插入结点时先链入后删除
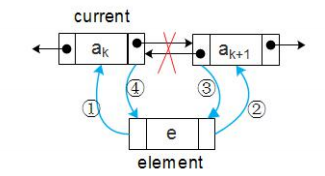
2.3 区别

2.4 队列与栈
循环队列


队列与栈的例题

2.5 串
串是一组特殊的线性表,其数据元素为字符。
- 空串:长度为0
- 空格串:里面为空格
- 子串:空串是任意串的子串;子串的位置为子串首先出现在主串中的位置
- 串比较:串长优先,其次第一个字符开始对比,字符码值(ASCII)大者为大
3 数组 array
地址计算:
- 一维数组数组的起始地址a+ 元素下标i*每个数组元素所占的存储空间
- 二维按行:n代表整个数组列的长度
- m代表行的长度


例题:
已知5行5列的二维数组a中的各元素占两个字节,求元素a[2][3]按行有限存储的存储地址?
解:a + (2*5+3)*2 = a+26
4 矩阵
稀疏矩阵
矩阵中非零元素的总数比上矩阵所有元素总数的值小于等于0.05时,则称该矩阵为稀疏矩阵(sparse matrix)
特殊矩阵

例题

5 广义表(Lists,又称列表)
是一种非线性的数据结构,是线性表的一种推广。即广义表中放松对表元素的原子限制,容许它们具有其自身结构
- 广义表是n(n≥0)个元素a1,a2,…,ai,…,an的有限序列。
- ai–或者是原子或者是一个广义表。
- 广义表通常记作:Ls=( a1,a2,…,ai,…,an)。
- Ls是广义表的名字,n为它的长度。
- 若ai是广义表,则称它为Ls的子表。
例:
- 有广义表LS1(a,(b,c),(d,e)),则长度为3 深度为2
- 有广义表LS1(a,(b,c),(d,e)),则将其中b字母取出,操作为:head(head(tail(LS1))
广义表基本操作
- 取表头head(LS)。非空广义表LS的第一个元素称为表头,它可以是一个单元素,也可以是一个子表。
- 取表尾tail(LS)。非空广义表中,除表头元素之外,由其余元素所构成的表称为表为表尾,非空广义表的表尾必定是一个表。(只有表头表尾)
例:LS1=(a,(b,c),(d,e)),取字符b的操作为,head(head(tail(LS1))
广义表特点
- 多层次结构,因广义表的元素可以是子表,而子表的元素还可以是子表。
- 广义表的元素可以是已经定义的广义表的名字,所以一个广义表可被其他广义表所共享。
- 广义表可以是一个递归表,及广义表中的元素也可以是本广义表的名字
广义表存储结构

6 树与二叉树

- 满二叉树:除最后一层无任何子结点外,每一层上的所有结点都有两个子结点。除叶子结点外的所有结点均有两个子结点。结点数达到最大值,所有叶子结点必须在同一层上。
- 完全二叉树:若设二叉树的深度为h,除第 h 层外,其它各层 (1~(h-1)层) 的结点数都达到最大个数,第h层所有的结点都连续集中在最左边
6.1 二叉树特性
- 在二叉树的第 i 层上至多有2i-1个结点
- 深度为 h 的二叉树, 它的结点至多为2h−1
- 对任何一颗二叉树,若它含有n0个叶子结点,n2个度为2的结点,则必存在关系式:n0=n2+1
- 具有 n 个结点的完全二叉树的深度为 [ log2n ] +1
- 如果i=1,则结点i无父结点,是二叉树的根;如果i>1,则父结点是i/2
- 如果2i>n,则结点i为叶子结点,无左子结点;否则,其左子结点是结点2i
- 如果2i+1>n,则结点i无右子节点,否则,其右子节点是节点2i+1
6.2 二叉树遍历
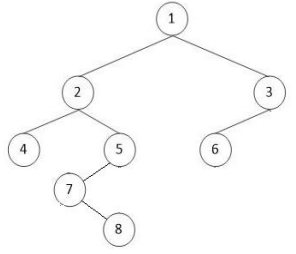
- 前序遍历:根->前序遍历左子树->前序遍历右子树
(1、2、4、5、7、8、3、6) - 中序遍历:中序遍历左子树->根->中序遍历右子树
(4、2、7、8、5、1、6、3) - 后序遍历:后序遍历左子树->后序遍历右子树->根
(4、8、7、5、2、6、3、1) - 层次遍历:从上至下、从左至右逐层访问各节点
(1、2、3、4、5、6、7、8)
6.3 树与反向构造二叉树

6.4 树转二叉树
- 孩子结点-左子树结点
- 兄弟结点-右孩子结点
- 加线,所有的兄弟结点间加一条线
- 去线,树中每个结点,只保留它与第一个孩子结点的连线,删除其他孩子结点之间的连线
- 调整,以树的根结点为轴心,调节整个树

6.5 查找二叉树
二叉排序树的节点的左子树都是小于根,节点的右子树都是大于根的,
- 插入节点
- 若该键值节点已存在,则不再插入
- 若查找二叉树为空树,则以新结点为查找二叉树;
- 将要插入节点键值与插入后父节点键值比较,就能确定新结点是父节点的左子节点,还是右子节点
- 删除结点
- 若待删除节点是叶子结点,则直接删除;
- 若待删除节点只有一个子结点,则将这个子结点与待删除节点的父结点直接连接
- 若待删除的节点p有两个子节点,则在其左子树上,用中序遍历查找关键值最大的结点s,用结点s的值代替结点p的值,然后删除节点s,节点s必属于上述1,2的情况之一
6.6 最优二叉树(哈夫曼树)
给定n个权值作为n个叶子结点,构造一棵二叉树,若该树的带权路径长度达到
最小,称这样的二叉树为最优二叉树
- 路径和路径长度:从一个结点往下可以达到的孩子或孙子结点之间的通路,称为路径。通路中分支的数目称为路径长度。
若规定根结点的层数为1,则从根结点到第L层结点的路径长度为L-1。 - 结点的权及带权路径长度:
- 权:将树中结点赋给一个有着某种含义的数值就叫该结点的权
- 带权路径长度:从根结点到该结点间的路径长度与该结点的权的乘积

- 树的带权路径长度(WPL):树的带权路径长度规定为所有叶子结点的带权路径长度之和
例题:

WPL = 7*1 + 5 *2 + (2+3) *3
6.7 线索二叉树
- 对于n个结点的二叉树,在二叉链存储 结构中有n+1个空链域
- 利用这些空链 域存放在某种遍历次序下该结点的前驱结点和后继结点的指针
- 这些指针称为线索,加上了线索的二叉链表称为线索链表,
- 相应二叉树称为线索二叉树 (Threaded BinaryTree)

解决问题:
- 解决了无法直接找到该结点在某种遍 历序列中的前驱和后继结点的问题,
- 解决了二叉链表找左、右孩子困难的 问题。
6.8 平衡二叉搜索树

- 它是一棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树,降低复杂度
- 常用算法有红黑树、AVL、Treap、伸展树等
- 任意节点的左右子树深度相差不超过1
- 每个结点的平衡度只能为-1、0或1
- 平衡度:左子树深度-右子树深度
6.9 树与森林
- 森林:多颗互不相交的树的集合
- 森林转化为二叉树:将森林中的每一颗树转化成二叉树。(广度转化深度)
- 连接新生成二叉树的每一个根结点(第一颗树的根结点为生成二叉树的树根,有指针域指向第二颗子树,依次类推)
- 以根为旋转轴顺时针旋转45度

- 二叉树转化为森林:断开从根结点开始一直向右下方的所有连线,生成多颗二叉子树,将每颗二叉子树转化成树即可构成森林(深度转广度);
7 图
图G是由集合V和E构成的二元组,记作G=(V,E),其中V是图中顶点的非空有限集合,E是图中边的有限集合。
- 有向图:图的边均有方向
- 无向图:均无方向
- 完全图:每个顶点均相连
- 度、出度和入度:关联某顶点的数目为该点的度,有向图中以该点为起点的有向边即为该点的出度、以某顶点为终点的有向边为该点的入度
- 路径:从一个顶点至另一个顶点的边,注意有向图有方向
7.1 完全图
在无向图中,若每对顶 点之间都有一条边相连, 则称该图为完全图;在有向图中,若每对项点之间都有二条方向相反 的边相互连接,则称该 图为完全图。

7.2 图的存储
邻接矩阵
用一个n阶方阵R来存放图中各结点的关联信息,其矩阵元素Rij定义为:

邻接表
首先把每个顶点的邻接顶点用链表表示出来,然后用一个一维数组来 顺序存储上面每个链表的头指针


7.3 图的遍历

-
深度优先搜索(类似树的先根\前序遍历)
- 首先访问出发顶点V
- 依次从v出发搜索V的任意一个邻接点W
- 若W未访问过,则从该点出发继续深度优先遍历
-
广度优先搜素
- 首先访问出发顶点V;
- 然后访问与顶点V邻接的全部未访问顶点W、X、Y…;
- 然后再依次访问W、X、Y…邻接的未访问的顶点
7.4 拓扑排序

带权有向图
在带权有向图中以顶点表示事件,以有向边表示活动,以边上的权值表示该活动持续的时间,则这种带权有向图称为用边表示活动的网,简称AOE网络

7.5 图的最小生成树
普利姆算法



克鲁斯卡尔算法
每一步最优(最短)

克鲁斯卡尔和普利姆算法的区别
8 算法
8.1 复杂度
8.2 静态查找表
折半查找
时间复杂度:关键词比较次数为[log2n]+1,且期望时间复杂度为O(log2n)
分块查找
- 是折半查找和顺序查找的一种改进方法
- 只要求索引表是有序的,因此特别适合于节点动态变化的情况。
- 其效率介于顺序查找与折半查找之间

- 在索引表中确定待查记录所在的块
- 在快内顺序查找。
8.3 动态查找表
平衡二叉树
于每一个节点来说,它的左右子树的高度之差不能超过1
如果插入或者删除一个节点使得高度之差大于1,就要进行节点之间的旋转
B树
- 树中每个结点最多有m棵子树。
- 若根结点不是叶子节点,则至少有两个子树;
- 除根之外的所有非终端结点最少有[m/2]棵子树;
- 所有的非终端结点中包含下列数据信息(n,A0,K1,A1,K2,A2,…,Kn,An)n为关键字个数(介于[m/2]-1至m-1之间),k为关键字,且k为有序,A为指向子树根结点的指针,且Ai-1所指子树中所有结点的关键字均小于Ki(i=1,2,…,n),An所指子树中所有节点的关键字均大于Kn
- 所有的叶子节点都出现在同一层次上,并且不带信息。

8.4 散列(哈希)查找
已知关键字集合U,最大关键字为m,
设计一个函数Hash,它以关键字为自变量,关键字的存储地址为因变量,将关键字映射到一个有限的、地址连续的区间间T0…n-1中,这个区间就称为散列表,哈希查找中使用的转换函数称为哈希函数。
- 计算位置:构造哈希函数确定关键词的位置
- 解决冲突:应用某种策略解决多个关键词位置相同的问题
线性探测法,伪随机法

9 排序
- 内部排序外部排序:存放是否为内存
- 稳定排序:两个及以上的相同元素排序前后顺序不变
冒泡,插入,基数,归并 - 不稳定排序:选择,快速,希尔,堆
- 就地排序:
9.1 插入排序
1)直接插入排序
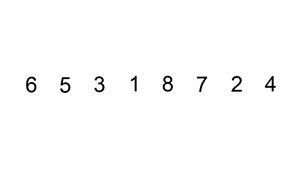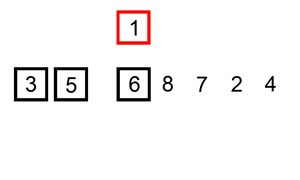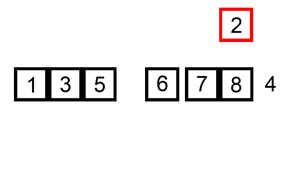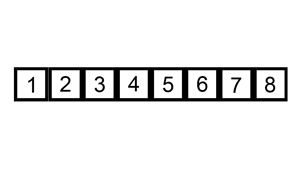
2)希尔排序(shell)

9.2 交换排序
1)冒泡排序

2)快速排序

9.3 选择排序
1)简单选择排序
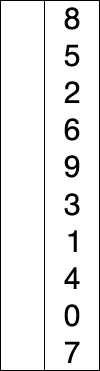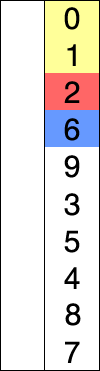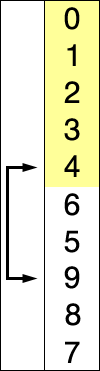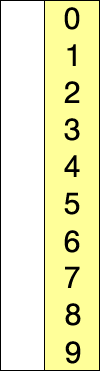
2)堆排序

- 堆分为最大堆和最小堆,其实就是完全二叉树。最大堆要求节点的元素都要不小于其孩子,最小堆要求节点元素都不大于其左右孩子,两者对左右孩子的大小关系不做任何要求,其实很好理解。有了上面的定义,我们可以得知,处于最大堆的根节点的元素一定是这个堆中的最大值。
- 其实我们的堆排序算法就是抓住了堆的这一特点,每次都取堆顶的元素,将其放在序列最后面,然后将剩余的元素重新调整为最大堆,依次类推,最终得到排序的序列。
- 排序序列,将堆顶的元素值和尾部的元素交换->重平衡->再交换…

9.4 归并排序

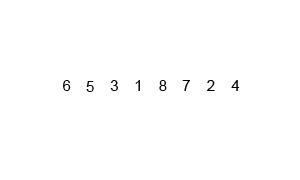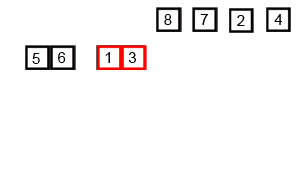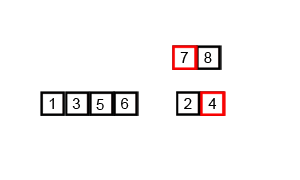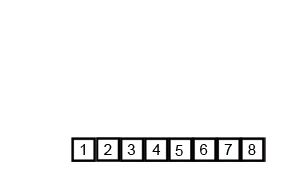
9.5 基数排序
- 基数排序是一种非比较型整数排序算法,其原理是将整数按位数切割成不同的数字,然后按每个位数分别比较。
- 由于整数也可以表达字符串(比如名字或日期)和特定格式的浮点数,所以基数排序也不是只能使用于整数。

