Docker 是一个开源的应用容器引擎,让开发者可以快速打包应用以及依赖到一个可移植的容器中,然后发布到任何流行的Linux机器上,使用docker去安装hadoop集群,可以快速的线性扩展机器,可以快速的实现部署。
本文使用docker快速的搭建伪分布式的Hadoop集群用于代码的开发和测试,生产环境的部署需要使用更多的工具或者其它技术实现快速的部署和docker的管理。
第一步:docker的安装和基础镜像的制作
1.1docker的安装
docker的安装和部分基础的操作可以参照,博文https://blog.csdn.net/weixin_40122615/article/details/102746393中的方法进行操作。
docker的命令也可以到菜鸟教程的Docker教程地址去查看:
https://www.runoob.com/docker/docker-tutorial.html
1.2docker基础镜像的制作
docker镜像制作的方式有多种,本文以Dockerfile卷的方式制作基础的镜像,也可使用其它的方式。
ssh版本的基础镜像
# 新建Dockerfile文件
vi Dockerfile
Dockerfile文件内容:
# 制作的镜像和版本号
FROM centos:centos6.6
# 作者
MAINTAINER yxb
# 安装ssh server client
RUN yum install -y openssh-server sudo
RUN sed -i 's/UsePAM yes/UsePAM no/g' /etc/ssh/sshd_config
RUN yum install -y openssh-clients
# root账户密码
RUN echo "root:hadoop" | chpasswd
RUN echo "root ALL=(ALL) ALL" >> /etc/sudoers
RUN ssh-keygen -t dsa -f /etc/ssh/ssh_host_dsa_key
RUN ssh-keygen -t rsa -f /etc/ssh/ssh_host_rsa_key
RUN mkdir /var/run/sshd
EXPOSE 22
CMD ["/usr/sbin/sshd", "-D"]
创建ssh版的新的镜像 版本centosssh:0.1.0
# 创建镜像 镜像版本 Dockerfile文件位置
docker build -t centosssh:0.1.0 .
注意:电脑要连接网络,安装过程会联网下载部分软件。
hadoopbase版本的基础镜像
Hadoop是Java语言编写的分布式文件系统,所以依赖Java的环境,因此要安装Java。
# 新建Dockerfile文件
vi Dockerfile
Dockerfile文件内容:
# 制作的镜像和版本号
FROM centosssh:0.1.0
# 作者
MAINTAINER yxb
ADD jdk-8u221-linux-x64.tar.gz /usr/local/
ENV JAVA_HOME /usr/local/jdk1.8.0_221
ENV PATH $JAVA_HOME/bin:$PATH
ADD hadoop-2.7.5.tar.gz /usr/local
ENV HADOOP_HOME /usr/local/hadoop-2.7.5
ENV PATH $HADOOP_HOME/bin:$PATH
RUN yum install -y which sudo
注意:必须将hadoop和Java的安装包与Dockerfile文件放在同一目录下
注意:build 命令最后是Dockerfile文件所在位置,下面的命令是有当前目录 “.”
创建安装hadoop和java版本的镜像,版本号:hadoopbase:0.1.0
# 创建镜像 镜像版本 Dockerfile文件位置 当前文件
docker build -t hadoopbase:0.1.0 .
第二步:Hadoop集群的安装配置文件
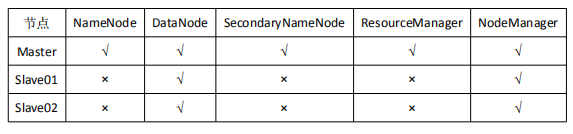
本文搭建伪分布式的三台机器的hadoop集群,用于开发和测试,即一主两从,节点的布置参数如下图:
2.1宿主机中创建自定义的docker网络
创建自定义的网络,配置固定的ip地址
# 查看已有的网络
docker network ls
# 创建自定义名称为docker的网络(网段可以自定义设置)
sudo docker network create --driver=bridge --subnet=192.168.100.1/24 docker
# 查看网络详情
sudo docker network inspect docker
2.2hadoop集群
以hadoopbase镜像为基础,在宿主机中运行容器:
# 运行docker,三台机器的hadoop
sudo docker run -itd --name master --hostname master -P -p 50070:50070 -p 8088:8088 -p 19888:19888 --net docker --ip 192.168.100.10 hadoopbase:0.1.0 /bin/bash
sudo docker run -itd --name slave01 --hostname slave01 -P --net docker --ip 192.168.100.20 hadoopbase:0.1.0 /bin/bash
sudo docker run -itd --name slave02 --hostname slave02 -P --net docker --ip 192.168.100.30 hadoopbase:0.1.0 /bin/bash
# 参数释义:
# -i: 交互式操作
# -t: 终端
# --name 容器的命名
# --hostname 主机名
# --ip 设置固定的ip地址
# --net 设置网络
# -p 指定固定的宿主机和容器的端口映射
# -P 随机的将容器内部使用的网络端口映射到宿主机
# -d 后台运行
# /bin/bash 交互式shell
# hadoopbase:0.1.0 镜像名称和版本号
设置与宿主机的时间同步
# 宿主机中拷贝宿主机的本机时间localtime到容器
sudo docker cp /etc/localtime master:/etc/
sudo docker cp /etc/localtime slave01:/etc/
sudo docker cp /etc/localtime slave02:/etc/
进入容器的交互式界面
# 进入交互式的容器中 命令为
sudo docker exec -it master /bin/bash
sudo docker exec -it slave01 /bin/bash
sudo docker exec -it slave02 /bin/bash
修改三台机器的主机名和ip的映射关系:
# 打开文件
vi /etc/hosts
# 添加内容
# ip和hostname
192.168.100.10 master
192.168.100.20 slave01
192.168.100.30 slave02
配置三台机器之间的免密登录:
三台机器都要执行的命令
# 启动sshd服务
service sshd start
# sshd 状态查看
service sshd status
# 若没有~/.ssh/目录,先执行一次ssh localhost
# 查看目录
cd ~/.ssh/
# 生成秘钥
ssh-keygen -t rsa
# 复制公钥
ssh-copy-id master
ssh-copy-id slave01
ssh-copy-id slave02
每台机器ssh配置的测试,测试能否免密登陆其他的机器:
# 测试本机
ssh localhost
ssh master
ssh slave01
ssh slave02
在master主机中配置hadoop的配置文件参数步骤如下:
# 进入hadoop的配置文件的安装目录
cd /usr/local/hadoop-2.7.5/etc/hadoop
对以下的配置文件进行修改:
core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master</value>
</property>
<property>
<!-- 临时文件目录 -->
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop-2.7.5/hadoopDatas/tempDatas</value>
</property>
<!-- 缓冲区大小,实际工作中根据服务器性能动态调整 -->
<property>
<name>io.file.buffer.size</name>
<value>2048</value>
</property>
<!-- 开启hdfs的垃圾桶机制,删除掉的数据可以从垃圾桶中回收,单位分钟 -->
<property>
<name>fs.trash.interval</name>
<value>10080</value>
</property>
<property>
<name>hadoop.native.lib</name>
<value>true</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:50090</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>master:50070</value>
</property>
<property>
<!-- 定义nameNode数据存储的节点位置 -->
<name>dfs.namenode.name.dir</name>
<value>file:///usr/local/hadoop-2.7.5/hadoopDatas/namenodeDatas,file:///usr/local/hadoop-2.7.5/hadoopDatas/namenodeDatas2</value>
</property>
<!-- 定义dataNode数据存储的节点位置,实际工作中,一般先确定磁盘的挂载目录,然后多个目录用,进行分割 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///usr/local/hadoop-2.7.5/hadoopDatas/datanodeDatas,file:///usr/local/hadoop-2.7.5/hadoopDatas/datanodeDatas2</value>
</property>
<property>
<name>dfs.namenode.edits.dir</name>
<value>file:///usr/local/hadoop-2.7.5/hadoopDatas/nn/edits</value>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>file:///usr/local/hadoop-2.7.5/hadoopDatas/snn/name</value>
</property>
<property>
<name>dfs.namenode.checkpoint.edits.dir</name>
<value>file:///usr/local/hadoop-2.7.5/hadoopDatas/dfs/snn/edits</value>
</property>
<property>
<!-- 数据保存的副本数量 -->
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<!-- 数据块的大小128M -->
<name>dfs.blocksize</name>
<value>134217728</value>
</property>
</configuration>
yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>
mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.job.ubertask.enable</name>
<value>true</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>
yarn-env.sh
hadoop-env.sh
mapred-env.sh
以上三个配置文件中加入java的路径
# java
export JAVA_HOME=/usr/local/jdk1.8.0_221
slaves
# datanode数据存储节点
master
slave01
slave02
创建配置文件中对应的文件目录:
# 创建文件夹
mkdir -p /usr/local/hadoop-2.7.5/hadoopDatas/tempDatas
mkdir -p /usr/local/hadoop-2.7.5/hadoopDatas/namenodeDatas
mkdir -p /usr/local/hadoop-2.7.5/hadoopDatas/namenodeDatas2
mkdir -p /usr/local/hadoop-2.7.5/hadoopDatas/datanodeDatas
mkdir -p /usr/local/hadoop-2.7.5/hadoopDatas/datanodeDatas2
mkdir -p /usr/local/hadoop-2.7.5/hadoopDatas/nn/edits
mkdir -p /usr/local/hadoop-2.7.5/hadoopDatas/snn/name
mkdir -p /usr/local/hadoop-2.7.5/hadoopDatas/dfs/snn/edits
添加hadoop和java环境变量到配置文件
# 打开配置文件
vi /etc/profile
# 添加Java和Hadoop的安装路径
export JAVA_HOME=/usr/local/jdk1.8.0_221
export PATH=$JAVA_HOME/bin:$PATH
export HADOOP_HOME=/usr/local/hadoop-2.7.5
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
# 更新配置文件
source /etc/profile
将master主机的hadoop安装目录发送到从机:
hadoop文件包发送到从机后,在从机配置java和haoop的环境变量,和上面的环境变量一致
# 发送Hadoop安装包到从节点
scp -r hadoop-2.7.5/ slave01:/usr/local/
scp -r hadoop-2.7.5/ slave02:/usr/local/
master主机为namenode节点,因此在master主机初始化NameNode的元数据目录,格式化文件系统
# 进入到hadoop的bin目录下,执行命令
hdfs namenode -format
测试hadoop集群是否安装成功:
# 进入sbin目录 开启
./start-all.sh
#jps查看是否存在相应的进程
jps
# 停止集群
./stop-all.sh
使用hadoop的命令上传文件:
# 查看文件
hadoop fs -ls /
# 上传本地的文件
hadoop fs -put test.txt /
通过浏览器的可视化界面查看HDFS的运行情况,,端口号为:50070(宿主机ip:50070),也可通过8088端口查看hadoop集群的状态。
