大三上学期,学习编译原理这门课,老师布置课后作业,要使用C/C++语言实现C/C++语言词法分析器。
本偏博文适合初学者想用,博主知识挑选了几个词法进行分析,望周知。
1、学习目的
掌握词法分析器程序设计的开发过程,可以实现简单基本的词法分析,掌握基本技能(本篇博客适合初学者,如果想深入探索,请另找资料)。
2、实验步骤
(1)写出需要分析的词的语言说明
标识符:以字母或下划线开头,后跟若干字母、下划线或数字组成的字符串;
保留字:标识符的子集;
无符号整数:
浮点数:
关系运算符:>、<、>=、<=、!=、==;
标点符号:+、-、*、/、(、)、[、]、{、}、:、;;
赋值符号:=;
注释标记:单行注释 // 多行注释/* … */
单词符号间的分割符:空格
(2)写出文法,正则文法(非终结符→终结符 非终结符 | 终结符)
标识符:
id → letter rid | _rid
rid → £| digit rid | letter rid | _rid
整数:
uNum → digit remainder
remainder → £| digit remainder
关系运算符:
relop → < | < equal | > | >equal | =equal | !equal
equal → =
赋值号:
assign_op → =
标点符号
single → + | - | * | / | ( | ) | { | } | [ | ] | “
注释
注释头:note → / start
start → / | *
注释尾:note → *
end → /
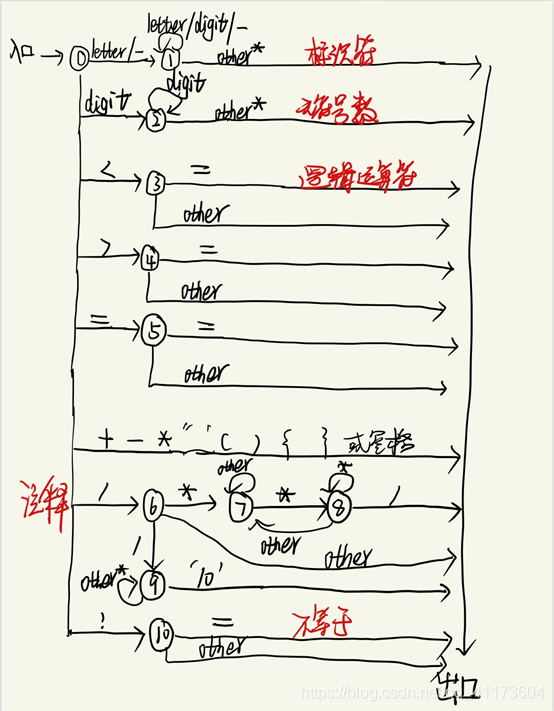
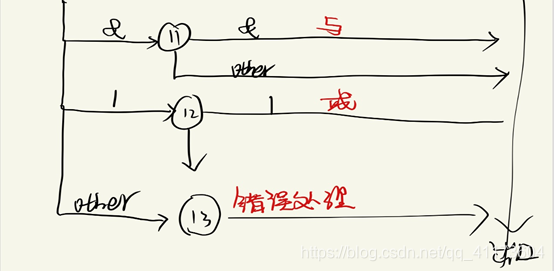
(3)根据以上正则文法,画出每个词法的状态转换图,化简并合并(计划使用visio画的,现在ipad随便画了画,后期补上)
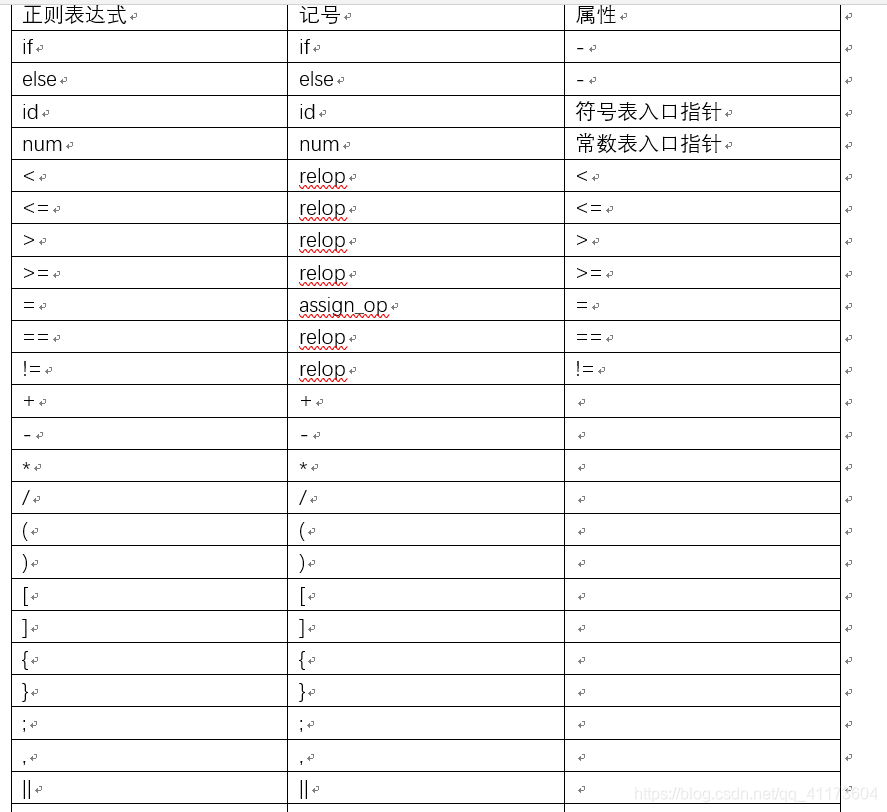
(4)翻译表(直接贴图了)
(5)设计全局变量和过程变量,编码实现
本程序严格遵循上面(3)的状态转换图
使用state作为当前状态,然后根据上述状态转换图写出程序,辅助一些函数
int state=0;
map<string,int> word_num; //记录单词出现的数量
char strBuffer[1026]; //字符串缓冲区
string token; //当前字符串缓冲区
int line_num=0; //需要统计的程序的行数,表示当前行号,用于定位错误位置
int char_num=0; //统计实际非空格非注释的字符的个数
char getChar(char* &str) //从字符串中获取指针当前所指位置的字符
bool isDigit(char c) //判断读入的字符是否是数字
bool isLetter(char c) //判断读入的字符是否是字母
bool isPunctuation(char c) //判断是否是标点符号,或者单个特别符号
bool isKey(string str) //判断当前id是否是关键字
void error() //错误输出,输出错误的行号
以下是源代码
主要实现过程在函数 process_string()
程序实现的功能
1、统计了代码的行号,我是从文件逐行读取的,可以判断错误出现的位置,即输出错误信息的时候输出行号
2、每个单词以记号的形式输出 <记号,属性>
3、输出扫描的字符数
4、统计每个单词出现的次数,输出方式为
#include <iostream>
#include <cstdio>
#include <vector>
#include <map>
using namespace std;
const int KEY_NUM = 18; //定义关键字的数量
const string KEY_SET[]={ //关键字集合
"for",
"while",
"do",
"switch",
"case",
"break",
"continue",
"if",
"else",
"char",
"int",
"float",
"return",
"main",
"const",
"string",
"map",
"vector",
};
map<string,int> word_num; //单词的数量
const char* FILE_NAME="./infile.txt";
char strBuffer[1026]; //字符串缓冲区
string token;
int line_num=0; //需要统计的程序的行数,表示当前行号,用于定位错误位置
int char_num=0; //统计实际非空格非注释的字符的个数
int state=0; //当前程序的状态
char getChar(char* &str) //从字符串中获取指针当前所指位置的字符
{
return *str++;
}
bool isDigit(char c)
{
return (c>='0' && c<='9');
}
bool isLetter(char c)
{
return (c>='a'&&c<='z') || (c>='A'&& c<='Z');
}
bool isPunctuation(char c) //判断是否是标点符号
{
return c=='+' || c=='-' || c=='*' || c=='(' || c==')' || c=='{'
|| c=='}' || c=='[' || c==']'|| c==';' || c==':' || c=='#' || c=='"' || c==',';
}
bool isKey(string str)
{
for(int i=0;i<KEY_NUM;i++)
if( str==KEY_SET[i] )
return true;
return false;
}
void error()
{
printf("the %dth line error\n",line_num);
}
void process_string(char* buf) //一行字符串的内容
{
if(state != 7) //state是8,表示是注释块
state = 0;
char C=' ';
int pos=0;
C = getChar(buf); //从but中读取一个字符
while( C!='\n' && C!='\0' ) //不是换行符,不是结束符
{
char_num++; //统计字符数量
switch(state){ //对当前状态进行分析
case 0: //处于代读取字符串状态,还没有进入任何自动机
if( isLetter(C) || C=='_' )
{
state = 1; //进入状态1
token = C;
C = getChar(buf);
}
else if( isDigit(C) )
{
state = 2;
token = C;
C = getChar(buf);
}
else if( isPunctuation(C) )
{
state = 0;
printf("< %c, - >\n",C);
C = getChar(buf);
}
else if( C==' ' ) //空格
{
state = 0;
C = getChar(buf);
}
else if( C=='<' )
{
state = 3;
token = C;
C = getChar(buf);
}
else if( C=='>' )
{
state = 4;
token = C;
C = getChar(buf);
}
else if( C=='=' )
{
state = 5;
token = C;
C = getChar(buf);
}
else if( C=='/' )
{
state = 6;
token = C;
C = getChar(buf);
}
else if( C=='!' )
{
state = 10;
token = C;
C = getChar(buf);
}
else if( C=='&' )
{
state = 11;
token = C;
C = getChar(buf);
}
else if( C=='|' )
{
state = 12;
token = C;
C = getChar(buf);
}
else{
error();
//跳过这个字符
C = getChar(buf);
}
break;
case 1:
if( isLetter(C) || C=='_' || isdigit(C) )
{
state=1;
token += C;
C = getChar(buf);
}
else{ //到了分隔符
word_num[token]++; //统计每个字符总数
if( isKey(token) )
{
cout<<"< key, "<<token<<" >"<<endl;
}
else
{
cout<<"< id, "<<token<<" >"<<endl;
}
state = 0;
}
break;
case 2: //无符号整数
if( isDigit(C) )
{
state = 2;
token += C;
C = getChar(buf);
}
else
{
int num=stoi(token); //字符串转换为int
cout<<"< num, "<<num<<" >"<<endl;
state = 0;
}
break;
case 3:
if(C=='=')
{
state = 0;
cout<<"< relop, <= >"<<endl;
C = getChar(buf);
}
else
{
state = 0;
cout<<"< relop, < > "<<endl;
}
break;
case 4:
if(C=='=')
{
state = 0;
cout<<"< relop, >= >"<<endl;
C = getChar(buf);
}
else
{
state = 0;
cout<<"< relop, > >"<<endl;
}
break;
case 5:
if(C=='=')
{
state = 0;
cout<<"< relop, == >"<<endl;
C = getChar(buf);
}
else
{
state = 0;
cout<<"< assign_op, = >"<<endl;
}
break;
case 6:
if(C=='*')
{
state = 7;
token += C;
C = getChar(buf);
}
else if(C=='/')
{
state = 9;
token += C;
//注释本行代码,后面的直接忽略
cout<<"< //, - >"<<endl;
return;
}
else{ //可以判断是除号
state = 0;
cout<<"< /, - >"<<endl;
}
break;
case 7:
if(C=='*')
{
state = 8;
C = getChar(buf);
}
else
{
state = 7;
C = getChar(buf);
}
break;
case 8:
if(C=='*')
{
state = 8;
C = getChar(buf);
}
else if(C=='/')
{
state = 0;
C = getChar(buf);
}
else{
state = 7;
C = getChar(buf);
}
break;
case 9:
state = 9;
C = getChar(buf);
break;
case 10:
if(C=='=')
{
cout<<"< relop, != >"<<endl;
state = 0;
C=getChar(buf);
}
else
{
cout<<"< !, - > "<<endl;
state = 0;
}
break;
case 11:
if(C=='&')
{
cout<<"< &&, - >"<<endl;
state = 0;
C=getChar(buf);
}
else{
cout<<"< &, - >"<<endl;
state=0;
}
break;
case 12:
if(C=='|')
{
cout<<"< ||, - >"<<endl;
state=0;
C = getChar(buf);
}
else{
error();
state=0;
C = getChar(buf);
}
}
}
}
int main() {
FILE* file = fopen(FILE_NAME,"r"); //只读的方式打开要扫描的文件
freopen("./outfile.txt","w",stdout); //输出重定向,输出数据将保存在D盘根目录下的out.txt文件中
if( file==NULL )
{
printf("Error! opening file");
exit(1);
}
//实现从文件中逐行读取
while( !feof(file) )
{
line_num++;
fgets(strBuffer,1024,file);
process_string(strBuffer); //处理字符串
}
fclose(file);
cout<<"the number of lines in this programme is: "<<line_num<<endl; //打印文件内容的行数
cout<<"the number of characters is: "<<char_num<<endl;
map<string,int>::iterator iter;
iter = word_num.begin();
while(iter!=word_num.end())
{
cout<<iter->first<<' '<<iter->second<<endl;
iter++;
}
return 0;
/* 这里是块注释,本程序可以忽略这里的注释
行注释很多,这里我专门写了一点块注释,程序可以实现该功能
*/
}
测试数据使用文件输入,输出,代码中使用的是相对路径,因此有必要,把代码和文件放在同一个目录下,可以自行测试。
在输入文件地址的时候,使用 ./ 表示当前文件目录,../是上一个目录,以此类推,注意绝对路径时 \\ 同样是斜杠,但是方向不一样。
考虑可移植性,我们使用相对路径比较合适。

可以根据输出信息,看出该词法分析器哪些标准字符无法识别,如果想要完善,请自己再深入学习?。
我使用的测试数据就是,以上代码,可以自己输出到目标文件看一看,词法分析是如何实现的。
欢迎交流学习,在下面留言啊
