算法论文:http://hexiaoqiao-wordpress.stor.sinaapp.com/uploads/2015/10/raft.pdf
Raft是工程上使用较为广泛的 最终一致性、去中心化、高可用 的分布式协议。
Raft是一个 共识算法。
Raft增强了可理解性,但是在性能、可靠性、可用性方面不输于Paxos算法。
Raft算法为了保证高可用,并不是强一致性,而是最终一致性。
Raft会选举出一个leader,leader负责接收所有客户端的更新请求,并负责日志复制的管理工作。leader通过定期向所有follower发送心跳信息维持其统治,如果leader发生故障,所有follower会重新选举出一个新的leader。
涉及两个问题:leader选举、日志复制
leader选举
在Raft协议中,一个节点在任意时刻只会是下面三种状态之一:
follower(追随者)candidate(候选者)leader(领导者)
节点的状态转移图如下:
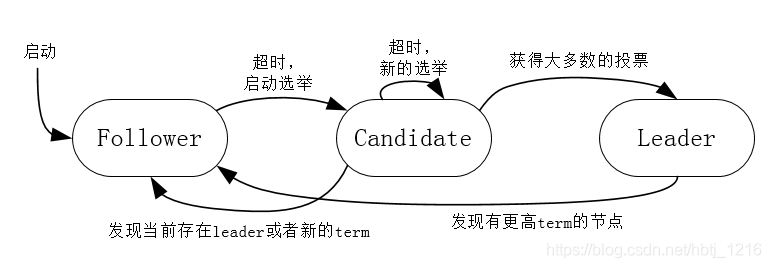
term在Raft中代表任期,代表选举出新的leader之后的稳定工作时期。
所有的节点在启动的时候都是
Follower,当经过一段之间之后没有收到Leader的心跳则切换到Candidate状态,并发起选举。如果Candidate获得大多数的投票(包括自己一票),则变为Leader状态。如果Leader状态的节点发现有一个节点拥有更高的term值,则主动降为Follower状态。
选举过程详解:
(1)如果
follower在一段超时时间内没有收到来自leader的心跳(也许此时还没有选出leader,大家都在等;也许leader挂了;也许只是leader与该follower之间网络故障),则会主动发起选举。(2)首先增加节点本地的
term值,切换到Candidate状态。(3)投自己一票。
(4)请求其他节点投自己一票,等待回复。有三种情况:
- 收到大多数投票(包括自己一票),则赢得选举,成为
leader。- 被告知别的节点已经当选为
leader,则自行切换为follower。- 一段超时时间之后没有收到大多数的投票响应,则发起新的一轮选举。
(5)当节点成为
leader之后,会立即给其他节点发送信息,避免其他节点发起新的投票。(6)
Raft通过为每个follower设置一个 随机的超时时间,来避免同时成为candidiate并发起投票,主要是避免平票的出现导致再一次选举,延长系统不可用的时间。
日志复制
客户端的一切请求都将发送到leader,leader负责调度这些并发请求的顺序,并且保证leader与followers状态的一致性。
Raft协议基于基于复制状态机来实现状态一致性的。leader将客户端请求(command)封装到一个个的log entry中,将这些log entries复制(replicate)到所有的follower节点,然后大家按相同顺序应用(apply)log entry中的command,那么最终所有节点的状态肯定是一致的。
一个客户端请求的完整流程:
(1)
leader收到一个客户端请求,封装成一个log entry。(2)
leader向所有的follower发送心跳消息。(3)
leader等待大多数的follower的响应。(4)
leader更新状态机中保存的状态。(6)
leader响应客户端。(7)
leader通知所有的follower应用日志。
在上面的流程中,leader只需要日志被复制到大多数follower节点即可向客户端返回。
日志复制相关约束:
- 一个
log被复制到大多数节点,就是committed,保证不会回滚; leader一定包含最新的committed log,因此leader只会追加日志,不会删除覆盖日志;- 不同节点,某个位置上日志相同,那么这个位置之前的所有日志一定是相同的;
Raft从来不会提交来自之前的term中的日志。
