Hive体系结构
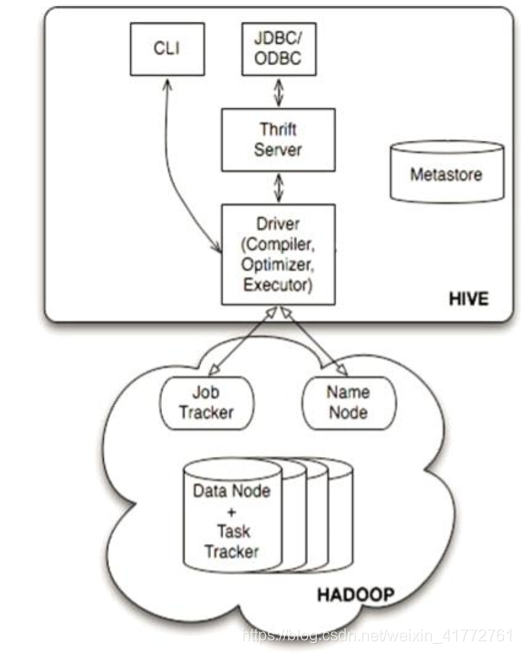
用户结构主要有三个:CLI / JDBC / WUI
- CLI,最常用的模式。实际上在>hive 命令行下操作时,就是利用CLI用户接口。
- JDBC,通过java代码操作,需要启动hiveserver,然后连接操作。
MetaStore
Hive将元数据存储在数据库中,如mysql、derby。Hive中的元数据包括表的名字, 表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
解释器(complier)、优化器(optimizer)、执行器(executor)组件
这三个组件用于:HQL语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在 HDFS中,并在随后有MapReduce调用执行。
Hadoop
Hive的数据存储在HDFS中,大部分的查询、计算由MapReduce完成
Hive工作流程
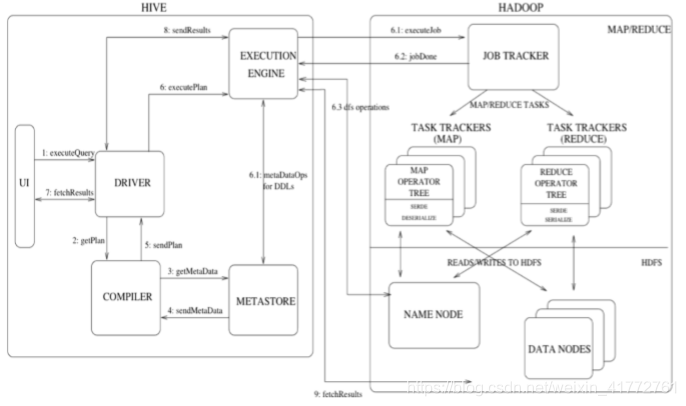
- 通过客户端提交一条Hql语句
- 通过complier(编译组件)对Hql进行词法分析、语法分析。在这一步,编译器要知道此hql语句到底要操作哪张表
- 去元数据库找表信息
- 得到信息
- complier编译器提交Hql语句分析方案。
- (1) executor 执行器收到方案后,执行方案(DDL过程)。在这里注意,执行器在执行方案
时,会判断:
如果当前方案不涉及到MR组件,比如为表添加分区信息、比如字符串操作等,比如简单的查询
操作等,此时就会直接和元数据库交互,然后去HDFS上去找具体数据。
如果方案需要转换成MR job,则会将job 提交给Hadoop的JobTracker。
(2) MR job完成,并且将运行结果写入到HDFS上。
(3)执行器和HDFS交互,获取结果文件信息。 - 如果客户端提交Hql语句是带有查询结果性的,则会发生:7-8-9步,完成结果的查询。
