1. 简介
主要介绍Hive的parse enginer(包括HQL->TaskTree)
Hive版本:1.2.1
HiBench 版本: v6
Hadoop 版本: 2.7.1
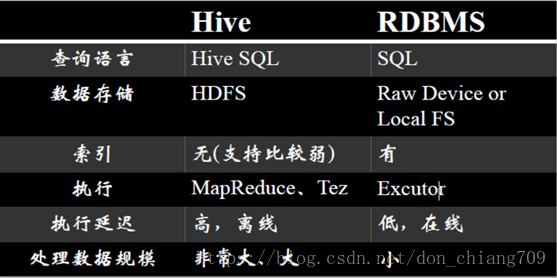
2. Hive 与 传统RDBMS的区别
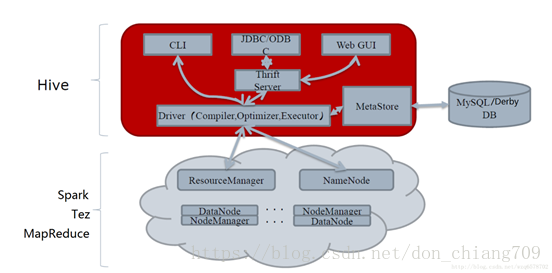
3. Hive架构
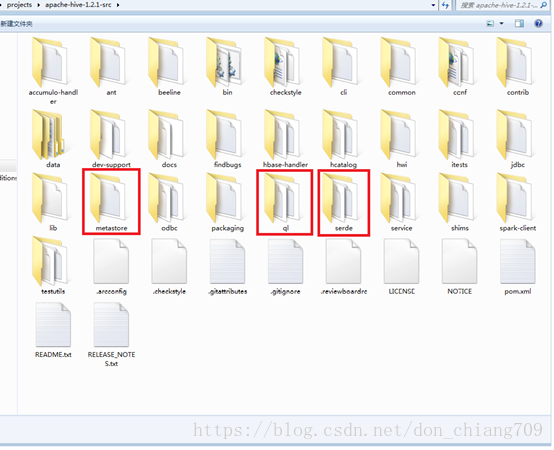
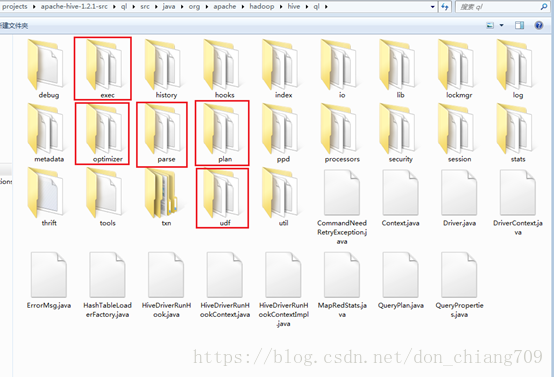
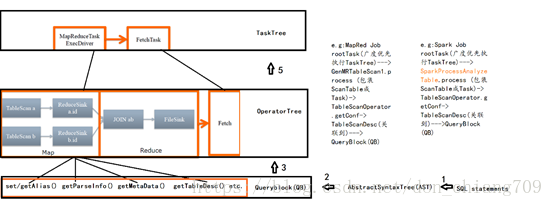
4. Hive 源码中3个关键的部分 (version Hive-1.2.1):
Hive核心三大组件
Query Processor:查询处理工具,源码ql包
SerDe:序列化与反序列化器,源码serde包
MetaStore:元数据存储及服务,源码metastore包
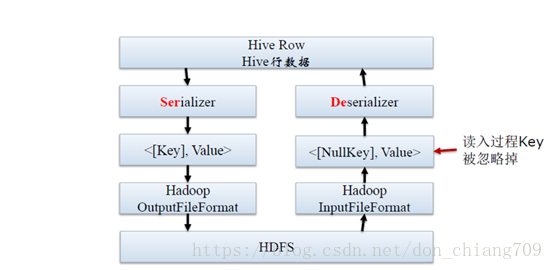
SerDe所处的位置
源码ql包下的子目录:
parse目录包含了解析HQL语句到 TaskTree的主线代码
optimizer目录提供了optimzer相关的接口
exec目录提供了task层的接口封装.例如,sparktask
plan 目录提供了work层的接口封装.例如,reducework
udf目录提供了查询用的自定义函数,例如简单的计算
5. HQL转化为MapReduce的6个过程
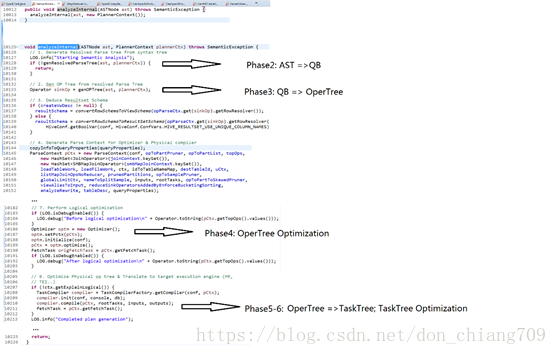
5.1 Hive是如何将HQL转化为MapReduce任务的,整个编译过程分为六个阶段:
1. Antlr定义SQL的语法规则,完成SQL词法,语法解析,将SQL转化为抽象语法树AST Tree
2. 遍历AST Tree,抽象出查询的基本组成单元QueryBlock
3. 遍历QueryBlock,翻译为执行操作树OperatorTree
4. 逻辑层优化器进行OperatorTree变换,合并不必要的ReduceSinkOperator,减少shuffle数据量
5. 遍历OperatorTree,翻译为MapReduce任务
6. 物理层优化器进行MapReduce任务的变换,生成最终的执行计划

5.2 源代码简要分析六个阶段:
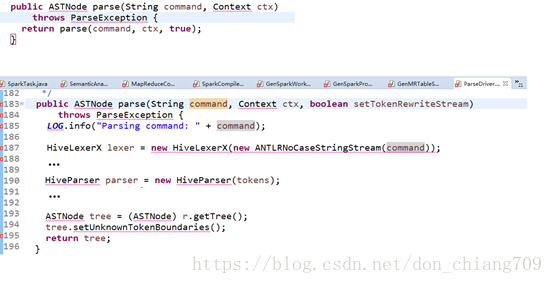
5.2.1 ParseDriver(包含Phase1)
这个类是解析sql的入口. HiveLexerX,HiveParser分别是Antlr对语法文件HiveLexer.g编译后自动生成的词法解析和语法解析类,在这两个类中进行复杂的解析。
5.2.2一颗抽象语法树变成一个QB(query block) SemanticAnalyzer.java (语义分析器)(包含Phase2-6)
6. 详细解释HQL转化为MapReduce的过程
6.1. Phase1 SQL词法,语法解析
Hive使用Antlr实现SQL的词法和语法解析。Antlr是一种语言识别的工具,可以用来构造领域语言。
6.2. Phase2 SQL基本组成单元QueryBlock
AST Tree仍然非常复杂,不够结构化,不方便直接翻译为MapReduce程序,AST Tree转化为QueryBlock就是将SQL进一部抽象和结构化. QueryBlock是一条SQL最基本的组成单元,包括三个部分:输入源,计算过程,输出。简单来讲一个QueryBlock就是一个子查询。
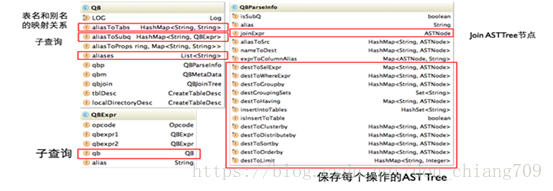
下图为Hive中QueryBlock相关对象的类图,解释图中几个重要的属性
AST Tree生成QueryBlock
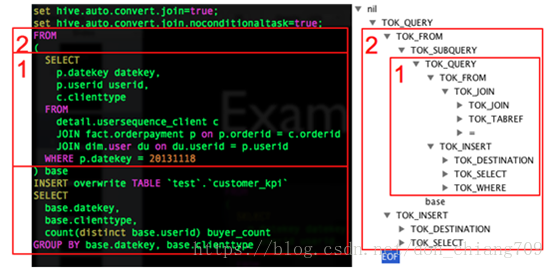
AST Tree生成QueryBlock的过程是一个递归的过程,先序遍历AST Tree,遇到不同的Token节点,保存到相应的属性中,主要包含以下几个过程
• TOK_QUERY => 创建QB对象,循环递归子节点
• TOK_FROM => 将表名语法部分保存到QB对象的aliasToTabs等属性中
• TOK_INSERT => 循环递归子节点
• TOK_DESTINATION => 将输出目标的语法部分保存在QBParseInfo对象的nameToDest属性中
• TOK_SELECT => 分别将查询表达式的语法部分保存在destToSelExpr、destToAggregationExprs、destToDistinctFuncExprs三个属性中
• TOK_WHERE => 将Where部分的语法保存在QBParseInfo对象的destToWhereExpr属性中
最终样例SQL生成两个QB对象,QB对象的关系如下,QB1是外层查询,QB2是子查询
QB1
\
QB2
6.3. Phase3 逻辑操作符Operator
Hive最终生成的MapReduce任务,Map阶段和Reduce阶段均由OperatorTree组成。逻辑操作符,就是在Map阶段或者Reduce阶段完成单一特定的操作。基本的操作符包括TableScanOperator,SelectOperator,FilterOperator,JoinOperator,GroupByOperator,ReduceSinkOperator. ReduceSinkOperator将Map端的字段组合序列化为Reduce Key/value, Partition Key,只可能出现在Map阶段,同时也标志着Hive生成的MapReduce程序中Map阶段的结束。
由于Hive的MapReduce程序是一个动态的程序,即不确定一个MapReduce Job会进行什么运算,可能是Join,也可能是GroupBy,所以Operator将所有运行时需要的参数保存在OperatorDesc中,OperatorDesc在提交任务前序列化到HDFS上,在MapReduce任务执行前从HDFS读取并反序列化。Map阶段OperatorTree在HDFS上的位置在Job.getConf(“hive.exec.plan”) + “/map.xml”
QueryBlock生成Operator Tree
QueryBlock生成Operator Tree就是遍历上一个过程中生成的QB和QBParseInfo对象的保存语法的属性,包含如下几个步骤:
• QB#aliasToSubq => 有子查询,递归调用
• QB#aliasToTabs => TableScanOperator
• QBParseInfo#joinExpr => QBJoinTree => ReduceSinkOperator + JoinOperator
• QBParseInfo#destToWhereExpr => FilterOperator
• QBParseInfo#destToGroupby => ReduceSinkOperator + GroupByOperator
• QBParseInfo#destToOrderby => ReduceSinkOperator + ExtractOperator
由于Join/GroupBy/OrderBy均需要在Reduce阶段完成,所以在生成相应操作的Operator之前都会先生成一个ReduceSinkOperator,将字段组合并序列化为Reduce Key/value, Partition Key.
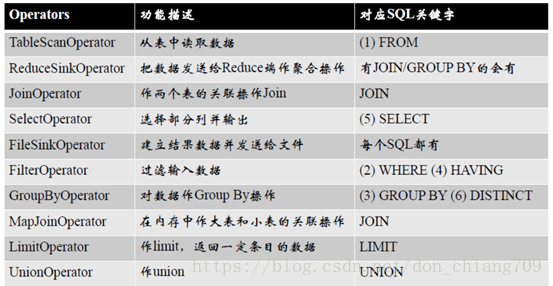
Operators对应SQL
Operator过程
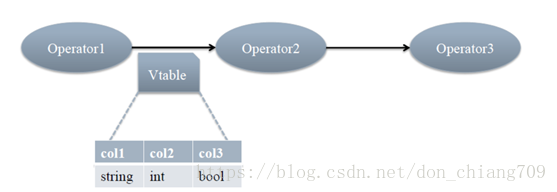
每个步骤对应一个逻辑运算符(Operator)
每个Operator输出一个虚表(VirtualTable)
6.4. Phase4 逻辑层优化器
大部分逻辑层优化器通过变换OperatorTree,合并操作符,达到减少MapReduce Job,减少shuffle数据量的目的。
名称 作用
② SimpleFetchOptimizer 优化没有GroupBy表达式的聚合查询
② MapJoinProcessor MapJoin,需要SQL中提供hint,0.11版本已不用
② BucketMapJoinOptimizer BucketMapJoin
② GroupByOptimizer Map端聚合
① ReduceSinkDeDuplication 合并线性的OperatorTree中partition/sort key相同的reduce
① PredicatePushDown 谓词前置
① CorrelationOptimizer 利用查询中的相关性,合并有相关性的Job,HIVE-2206
ColumnPruner 字段剪枝
表格中①的优化器均是一个Job干尽可能多的事情/合并。②的都是减少shuffle数据量,甚至不做Reduce。
PredicatePushDown优化器
断言判断提前优化器将OperatorTree中的FilterOperator提前到TableScanOperator之后
NonBlockingOpDeDupProc优化器
NonBlockingOpDeDupProc优化器合并SEL-SEL 或者 FIL-FIL 为一个Operator
6.5. Phase5 OperatorTree生成TaskTree(MapReduce Job)的过程
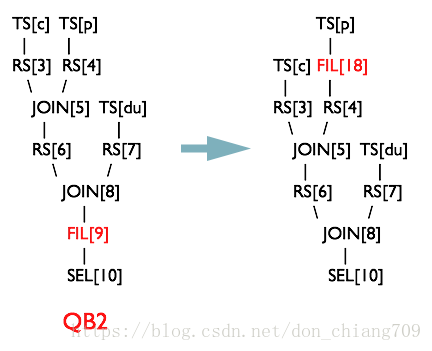
OperatorTree转化为MapReduce Job的过程分为下面几个阶段
a) 对输出表生成MoveTask
b) 从OperatorTree的其中一个根节点向下深度优先遍历
c) ReduceSinkOperator标示Map/Reduce的界限,也就意味着是多个Job间的界限
d) 遍历其他根节点,遇过碰到JoinOperator合并MapReduceTask
e) 生成StatTask更新元数据
f) 剪断Map与Reduce间的Operator的关系
6.5.1 MoveTask
由上一步OperatorTree只生成了一个FileSinkOperator,直接生成一个MoveTask,完成将最终生成的HDFS临时文件移动到目标表目录下
MoveTask[Stage-0]
Move Operator
6.5.2 遍历OperatorTree
将OperatorTree中的所有根节点保存在一个toWalk的数组中,循环取出数组中的元素
6.5.3 物理执行计划和逻辑执行计划的区别
逻辑执行计划是一个Operator图
物理执行计划是一个Task图
物理执行计划是把逻辑执行计划切分成子图
物理执行计划图的每个Task结点内是一个Operator结点的子图
举个例子
SELECT * FROM a JOIN b ON a.id=b.id;
6.5.4 物理执行计划的Task类型
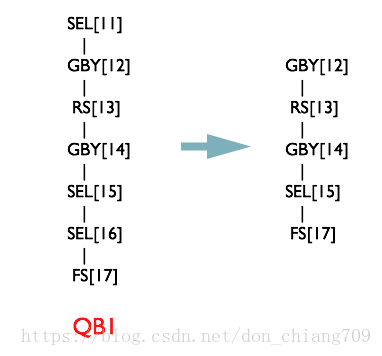
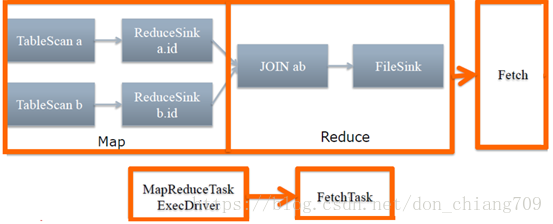
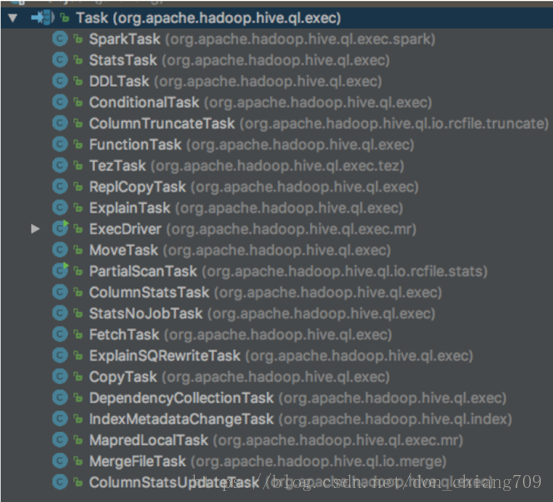
Hive的一些Task类型描述:
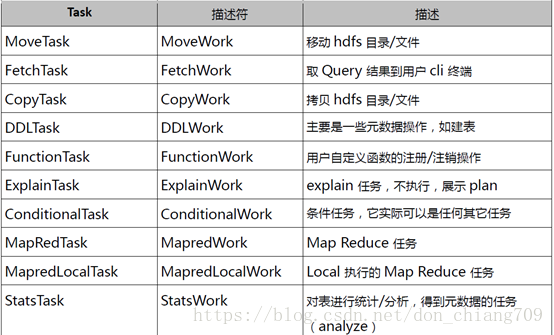
6.6. Phase6 物理层优化器
不同的引擎有不同的物理优化
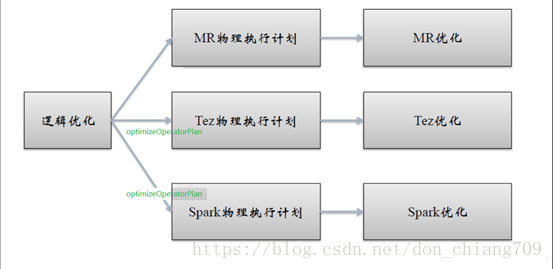
名称 作用
Vectorizer HIVE-4160,将在0.13中发布
SortMergeJoinResolver 与bucket配合,类似于归并排序
SamplingOptimizer 并行order by优化器,在0.12中发布
CommonJoinResolver + MapJoinResolver MapJoin优化器
MapJoin优化器原理
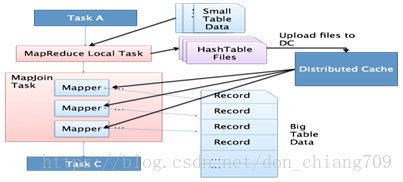
MapJoin简单说就是在Map阶段将小表读入内存,顺序扫描大表完成Join。
7. 物理执行计划
函数execute() (Driver.java)
public int execute() throws CommandNeedRetryException {
…
int jobs = Utilities.getMRTasks(plan.getRootTasks()).size()
+ Utilities.getTezTasks(plan.getRootTasks()).size()
+ Utilities.getSparkTasks(plan.getRootTasks()).size();
if (jobs > 0) {
console.printInfo("Query ID = " + plan.getQueryId());
console.printInfo("Total jobs = " + jobs);
}
…
// Add root Tasks to runnable
for (Task<? extends Serializable> tsk : plan.getRootTasks()) {
// This should never happen, if it does, it's a bug with the potential to produce
// incorrect results.
assert tsk.getParentTasks() == null || tsk.getParentTasks().isEmpty();
driverCxt.addToRunnable(tsk);
}
…
// Launch upto maxthreads tasks
Task<? extends Serializable> task;
while ((task = driverCxt.getRunnable(maxthreads)) != null) { //目前只有mapreduce task 可以被并发执行,本地 TaskTask Task都是被顺序执行的。
perfLogger.PerfLogBegin(CLASS_NAME, PerfLogger.TASK + task.getName() + "." + task.getId());
TaskRunner runner = launchTask(task, queryId, noName, jobname, jobs, driverCxt);
if (!runner.isRunning()) {
break;
}
}
…
}
7.1 Hive On MR物理执行计划
通过MapReduceCompiler将Operator Tree转换为Task Tree后,其中需要提交给MR执行的任务即为MapRedTask(继承ExecDriver,其描述参考MapredWork)。 该Task Tree 中包含一系列的操作符(operator),操作符是Hive的最小操作单元,每个操作符代表了一种HDFS操作或者MapReduce作业。ExecDriver里通过关联MapWork和ReduceWork,并设置MapperClass为 ExecMapper 和 ReducerClass为ExecReducer 来执行 MapReduce 程序。
ExecDriver.java中的代码如下:
job.setMapperClass(ExecMapper.class);
job.setReducerClass(ExecReducer.class);
例如,HQL 语句SELECT * FROM a JOIN b ON a.id=b.id; 最后生成的TaskTree如下:
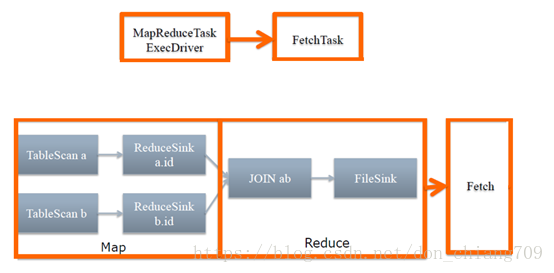
Note:Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
7.2 Hive On Spark物理执行计划
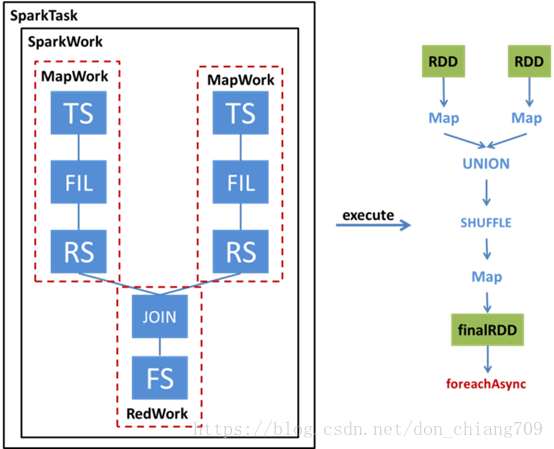
通过SparkCompiler将Operator Tree转换为Task Tree后,其中需要提交给Spark执行的任务即为SparkTask。不同于MapReduce中Map+Reduce的两阶段执行模式,Spark采用DAG执行模式,因此一个SparkTask包含了一个表示RDD转换的DAG,这个DAG就是由SparkWork包装成的。
SparkWork把所有被执行的work对象封装在一个Spark Job中,它是一个以MapWork为根节点的work 树,还包含其它节点的ReduceWork。执行SparkTask时,就根据SparkWork所表示的DAG计算出最终的RDD。首先根据MapWork来生成最底层的HadoopRDD,然后将各个MapWork和ReduceWork包装成Function应用到RDD上。在有依赖的Work之间,需要显式地调用Shuffle转换,具体选用哪种Shuffle则要根据查询的类型来确定。最后通过RDD的foreachAsync来触发运算。使用foreachAsync是因为我们使用了Hive原语,因此不需要RDD返回结果;此外foreachAsync异步提交任务便于我们对任务进行监控。
下图是:两表join查询到Spark任务的转换
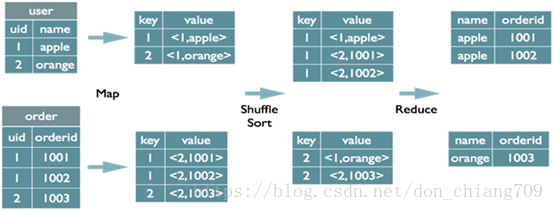
8. 举例: Join的实现原理
select u.name, o.orderid from order o join user u on o.uid = u.uid;
在map的输出value中为不同表的数据打上tag标记,在reduce阶段根据tag判断数据来源。MapReduce的过程如下(这里只是说明最基本的Join的实现,还有其他的实现方式)
9. 使用explain
以HiBench的SQL Aggregation 测试用例来举例说明
运行HiBench/bin/workloads/sql/aggregation/hadoop/run.sh时会自动生成SQL文件
HiBench/report/aggregation/hadoop/uservisits_aggre.hive.该文件的内容如下:
$ cat HiBench/report/aggregation/hadoop/uservisits_aggre.hive
USE DEFAULT;
set hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
set mapreduce.job.maps=138;
set mapreduce.job.reduces=69;
set hive.stats.autogather=false;
DROP TABLE IF EXISTS uservisits;
CREATE EXTERNAL TABLE uservisits (sourceIP STRING,destURL STRING,visitDate STRING,adRevenue DOUBLE,userAgent STRING,countryCode STRING,languageCode STRING,searchWord STRING,duration INT ) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde' STORED AS SEQUENCEFILE LOCATION 'hdfs://cluster1.serversolution.sh.hxt:9000/HiBench/Aggregation/Input/uservisits';
DROP TABLE IF EXISTS uservisits_aggre;
CREATE EXTERNAL TABLE uservisits_aggre ( sourceIP STRING, sumAdRevenue DOUBLE) STORED AS SEQUENCEFILE LOCATION 'hdfs://cluster1.serversolution.sh.hxt:9000/HiBench/Aggregation/Output/uservisits_aggre';
INSERT OVERWRITE TABLE uservisits_aggre SELECT sourceIP, SUM(adRevenue) FROM uservisits GROUP BY sourceIP;
9.1浅析uservisits_aggre.hive文件内容:
USE DEFAULT; //使用Derby的DEFAULT数据库
DROP TABLE IF EXISTS uservisits; //如果DEFAULT数据库已经存在uservisits表,删除它。
CREATE EXTERNAL TABLE uservisits (sourceIP STRING,destURL STRING,visitDate STRING,adRevenue DOUBLE,userAgent STRING,countryCode STRING,languageCode STRING,searchWord STRING,duration INT ) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde' STORED AS SEQUENCEFILE LOCATION 'hdfs://cluster1.serversolution.sh.hxt:9000/HiBench/Aggregation/Input/uservisits'; //以格式为Sequence 的 HiBench/Aggregation/Input/uservisits文件为数据源创建一个外部表 uservisits,它的序列化反序列化插件为org.apache.hadoop.hive.serde2.OpenCSVSerde。 外部表 uservisits包含如下字段sourceIP STRING,destURL STRING,visitDate STRING,adRevenue DOUBLE,userAgent STRING,countryCode STRING,languageCode STRING,searchWord STRING,duration INT )。
DROP TABLE IF EXISTS uservisits_aggre; //如果DEFAULT数据库已经存在uservisits_aggre表,删除它。
CREATE EXTERNAL TABLE uservisits_aggre ( sourceIP STRING, sumAdRevenue DOUBLE) STORED AS SEQUENCEFILE LOCATION 'hdfs://cluster1.serversolution.sh.hxt:9000/HiBench/Aggregation/Output/uservisits_aggre'; //创建一个Sequence 格式的外部表uservisits_aggre,该表包含字段( sourceIP STRING, sumAdRevenue DOUBLE)。该表的数据存储在HDFS的HiBench/Aggregation/Output/uservisits_aggre位置。
INSERT OVERWRITE TABLE uservisits_aggre SELECT sourceIP, SUM(adRevenue) FROM uservisits GROUP BY sourceIP; //从uservisits表选取sourceIP并计算该IP的总adRevenue按sourceIP排序插入数据到uservisits_aggre表.
9.2 设置Hive的环境变量并运行Hive
export HIVE_HOME=~/.local/bin/HiBench-compiling-for-spark2.1/hadoopbench/sql/target/apache-hive-0.14.0-bin/
export PATH=${HIVE_HOME}/bin:$PATH
运行Hadoop:
$HADOOP_HOME/sbin/start-dfs.sh
$HADOOP_HOME/sbin/start-yarn.sh
$HADOOP_HOME/sbin/mr-jobhistory-daemon.sh start historyserver
运行Hive:
$ hive
Logging initialized using configuration in jar:file:/home/yeshang/.local/bin/HiBench-compiling-for-spark2.1/hadoopbench/sql/target/apache-hive-0.14.0-bin/lib/hive-common-0.14.0.jar!/hive-log4j.properties
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/home/yeshang/.local/bin/hadoop-2.7.1-linux4.14.15/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/home/yeshang/.local/bin/HiBench-compiling-for-spark2.1/hadoopbench/sql/target/apache-hive-0.14.0-bin/lib/hive-jdbc-0.14.0-standalone.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
hive>
9.3使用Hive 的explain命令来执行和解析uservisits_aggre.hive文件内容 (MapReduce)
hive> CREATE EXTERNAL TABLE uservisits (sourceIP STRING,destURL STRING,visitDate STRING,adRevenue DOUBLE,userAgent STRING,countryCode STRING,languageCode STRING,searchWord STRING,duration INT ) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde' STORED AS SEQUENCEFILE LOCATION 'hdfs://cluster1.serversolution.sh.hxt:9000/HiBench/Aggregation/Input/uservisits';
OK
Time taken: 0.787 seconds
hive> CREATE EXTERNAL TABLE uservisits_aggre ( sourceIP STRING, sumAdRevenue DOUBLE) STORED AS SEQUENCEFILE LOCATION 'hdfs://cluster1.serversolution.sh.hxt:9000/HiBench/Aggregation/Output/uservisits_aggre';
OK
Time taken: 0.134 seconds
hive> explain INSERT OVERWRITE TABLE uservisits_aggre SELECT sourceIP, SUM(adRevenue) FROM uservisits GROUP BY sourceIP;
OK
STAGE DEPENDENCIES:
Stage-1 is a root stage
Stage-0 depends on stages: Stage-1
Stage-2 depends on stages: Stage-0
STAGE PLANS:
Stage: Stage-1
Map Reduce
Map Operator Tree:
TableScan
alias: uservisits
Statistics: Num rows: 933825 Data size: 186765136 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: sourceip (type: string), adrevenue (type: string)
outputColumnNames: sourceip, adrevenue
Statistics: Num rows: 933825 Data size: 186765136 Basic stats: COMPLETE Column stats: NONE
Group By Operator
aggregations: sum(adrevenue)
keys: sourceip (type: string)
mode: hash
outputColumnNames: _col0, _col1
Statistics: Num rows: 933825 Data size: 186765136 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator
key expressions: _col0 (type: string)
sort order: +
Map-reduce partition columns: _col0 (type: string)
Statistics: Num rows: 933825 Data size: 186765136 Basic stats: COMPLETE Column stats: NONE
value expressions: _col1 (type: double)
Reduce Operator Tree:
Group By Operator
aggregations: sum(VALUE._col0)
keys: KEY._col0 (type: string)
mode: mergepartial
outputColumnNames: _col0, _col1
Statistics: Num rows: 466912 Data size: 93382467 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: _col0 (type: string), _col1 (type: double)
outputColumnNames: _col0, _col1
Statistics: Num rows: 466912 Data size: 93382467 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: false
Statistics: Num rows: 466912 Data size: 93382467 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
name: default.uservisits_aggre
Stage: Stage-0
Move Operator
tables:
replace: true
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
name: default.uservisits_aggre
Stage: Stage-2
Stats-Aggr Operator
Time taken: 0.749 seconds, Fetched: 61 row(s)
hive> explain CREATE EXTERNAL TABLE uservisits (sourceIP STRING,destURL STRING,visitDate STRING,adRevenue DOUBLE,userAgent STRING,countryCode STRING,languageCode STRING,searchWord STRING,duration INT ) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde' STORED AS SEQUENCEFILE LOCATION 'hdfs://cluster1.serversolution.sh.hxt:9000/HiBench/Aggregation/Input/uservisits';
OK
STAGE DEPENDENCIES:
Stage-0 is a root stage
STAGE PLANS:
Stage: Stage-0
Create Table Operator:
Create Table
columns: sourceip string, desturl string, visitdate string, adrevenue double, useragent string, countrycode string, languagecode string, searchword string, duration int
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
location: hdfs://cluster1.serversolution.sh.hxt:9000/HiBench/Aggregation/Input/uservisits
output format: org.apache.hadoop.mapred.SequenceFileOutputFormat
serde name: org.apache.hadoop.hive.serde2.OpenCSVSerde
name: default.uservisits
isExternal: true
Time taken: 0.069 seconds, Fetched: 15 row(s)
hive> explain CREATE EXTERNAL TABLE uservisits_aggre ( sourceIP STRING, sumAdRevenue DOUBLE) STORED AS SEQUENCEFILE LOCATION 'hdfs://cluster1.serversolution.sh.hxt:9000/HiBench/Aggregation/Output/uservisits_aggre';
OK
STAGE DEPENDENCIES:
Stage-0 is a root stage
STAGE PLANS:
Stage: Stage-0
Create Table Operator:
Create Table
columns: sourceip string, sumadrevenue double
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
location: hdfs://cluster1.serversolution.sh.hxt:9000/HiBench/Aggregation/Output/uservisits_aggre
output format: org.apache.hadoop.mapred.SequenceFileOutputFormat
serde name: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
name: default.uservisits_aggre
isExternal: true
Time taken: 0.018 seconds, Fetched: 15 row(s)
hive> show databases;
OK
default
Time taken: 0.061 seconds, Fetched: 1 row(s)
hive> show tables;
OK
uservisits
uservisits_aggre
Time taken: 0.035 seconds, Fetched: 2 row(s)
hive> desc uservisits;
OK
sourceip string from deserializer
desturl string from deserializer
visitdate string from deserializer
adrevenue string from deserializer
useragent string from deserializer
countrycode string from deserializer
languagecode string from deserializer
searchword string from deserializer
duration string from deserializer
Time taken: 0.094 seconds, Fetched: 9 row(s)
hive> desc uservisits_aggre;
OK
sourceip string
sumadrevenue double
Time taken: 0.081 seconds, Fetched: 2 row(s)
9.4 使用Hive 的explain命令来执行和解析uservisits_aggre.hive文件内容 (Spark)
hive>set hive.execution.engine=spark;
hive> explain INSERT OVERWRITE TABLE uservisits_aggre SELECT sourceIP, SUM(adRevenue) FROM uservisits GROUP BY sourceIP;
OK
STAGE DEPENDENCIES:
Stage-1 is a root stage
Stage-0 depends on stages: Stage-1
Stage-2 depends on stages: Stage-0
STAGE PLANS:
Stage: Stage-1
Spark
Edges:
Reducer 2 <- Map 1 (GROUP, 1)
DagName: yeshang_20180910101642_7584d13c-740b-4816-8e7e-2d1738c02b85:1
Vertices:
Map 1
Map Operator Tree:
TableScan
alias: uservisits
Statistics: Num rows: 93187 Data size: 18637592 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: sourceip (type: string), adrevenue (type: string)
outputColumnNames: sourceip, adrevenue
Statistics: Num rows: 93187 Data size: 18637592 Basic stats: COMPLETE Column stats: NONE
Group By Operator
aggregations: sum(adrevenue)
keys: sourceip (type: string)
mode: hash
outputColumnNames: _col0, _col1
Statistics: Num rows: 93187 Data size: 18637592 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator
key expressions: _col0 (type: string)
sort order: +
Map-reduce partition columns: _col0 (type: string)
Statistics: Num rows: 93187 Data size: 18637592 Basic stats: COMPLETE Column stats: NONE
value expressions: _col1 (type: double)
Reducer 2
Reduce Operator Tree:
Group By Operator
aggregations: sum(VALUE._col0)
keys: KEY._col0 (type: string)
mode: mergepartial
outputColumnNames: _col0, _col1
Statistics: Num rows: 46593 Data size: 9318695 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: false
Statistics: Num rows: 46593 Data size: 9318695 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
name: default.uservisits_aggre
Stage: Stage-0
Move Operator
tables:
replace: true
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
name: default.uservisits_aggre
Stage: Stage-2
Stats-Aggr Operator
Time taken: 94.757 seconds, Fetched: 63 row(s)
hive>
10. 总结
10.1各个阶段的逻辑图
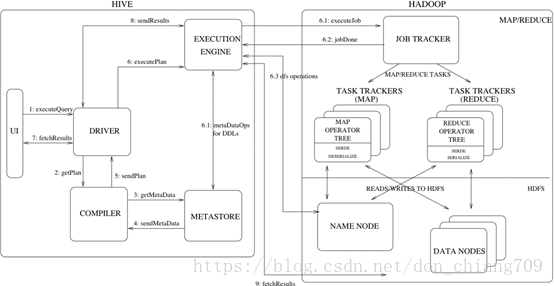
10.2 Hive System Architecture
10.3 Hive参数默认值及其变量名,参考HiveConf.java
10.4 Where is log of hive under HiBench? Is there any valuable?
拷贝hive-log4j.properties.template文件到~/HiBench/hadoopbench/sql/target/apache-hive-1.2.1-bin/conf/hive-log4j.properties,做如下修改:
hive.root.logger=DEBUG,DRFA
hive.log.dir=/tmp/${user.name}
log文件为/tmp/yeshang/hive.log
10.5 MapWork\ReduceWork及MapRedTask关系
ExecDriver
\
MapRedTask (description: MapredWork)
\
\
MapWork + ReduceWork
/
/
/
/
/
/**
* MapWork represents all the information used to run a map task on the cluster.
* It is first used when the query planner breaks the logical plan into tasks and
* used throughout physical optimization to track map-side operator plans, input
* paths, aliases, etc.
*
* ExecDriver will serialize the contents of this class and make sure it is
* distributed on the cluster. The ExecMapper will ultimately deserialize this
* class on the data nodes and setup it's operator pipeline accordingly.
*
* This class is also used in the explain command any property with the
* appropriate annotation will be displayed in the explain output.
*/
MapWork + ReduceWork
/
/
/
/
/
/**
* ReduceWork represents all the information used to run a reduce task on the cluster.
* It is first used when the query planner breaks the logical plan into tasks and
* used throughout physical optimization to track reduce-side operator plans, schema
* info about key/value pairs, etc
*
* ExecDriver will serialize the contents of this class and make sure it is
* distributed on the cluster. The ExecReducer will ultimately deserialize this
* class on the data nodes and setup it's operator pipeline accordingly.
*
* This class is also used in the explain command any property with the
* appropriate annotation will be displayed in the explain output.
*/
11. 参考
Antlr: http://www.antlr.org/
Wiki Antlr介绍: http://en.wikipedia.org/wiki/ANTLR
Hive Wiki: https://cwiki.apache.org/confluence/display/Hive/Home
HiveSQL编译过程: http://www.slideshare.net/recruitcojp/internal-hive
Join Optimization in Hive: Join Strategies in Hive from the 2011 Hadoop Summit (Liyin Tang, Namit Jain)
Hive Design Docs: https://cwiki.apache.org/confluence/display/Hive/DesignDocs
Hive SQL执行计划深度解析: http://tech.meituan.com/hive-sql-to-mapreduce.html
hive原理与源码分析(系列贴 ) https://blog.csdn.net/wzq6578702/article/category/6019045