快速笔记
语句及处理
建表:
CREATE TABLE t {
id VARCHAR(31),
name VARCHAR(50),
age int,
key id_idx (id)
};
select : 全表扫描+过滤,不考虑索引
SELECT name FROM t WHERE age > 10;
先放一下 Insert 的处理流程总结:
- server/conn.go 监听端口,得到语句后进行处理,传给 session 包。
- session/session.go 的 execute 函数包含了语句解析执行的三个核心流程。
- 调用 parse 包中的内容,将语句解析成抽象语法树,即 ast.InsertStmt 类型。
- 调用 execute/complie.go,转发给 planner 包处理,传回一个 Plan 接口类型,实际是 plannercore.Insert 类型。
- 调用 executor 包,在 executor/builder.go 中 Plan 被转换为了 executor.InsertExec 类型,即执行器。
- 使用 Next 函数来执行语句,INSERT 语句在返回前就会被执行,通过 table 包执行结果并写入到事务缓存中。
- 将 resultSet 返回给 server/conn.go(SELECT语句会在此时调用 Next 执行)。
SELECT 处理流程与 INSERT 的不同:
- 需要经过 Optimize, 即将逻辑 plan 转换成物理 plan.
- 需要与存储引擎的计算模块交互,计算逻辑下推到存储节点
- 需要对客户端返回结果集数据
Parse
select 最终会被解析成 ast.SelectStmt 结构:
parser/ast/dml.go
770: // SelectStmt represents the select query node.
// See https://dev.mysql.com/doc/refman/5.7/en/select.html
type SelectStmt struct {
dmlNode
resultSetNode
// SelectStmtOpts wraps around select hints and switches.
*SelectStmtOpts
// Distinct represents whether the select has distinct option.
Distinct bool
// From is the from clause of the query.
From *TableRefsClause
// Where is the where clause in select statement.
Where ExprNode
// Fields is the select expression list.
Fields *FieldList
// GroupBy is the group by expression list.
GroupBy *GroupByClause
// Having is the having condition.
Having *HavingClause
// WindowSpecs is the window specification list.
WindowSpecs []WindowSpec
// OrderBy is the ordering expression list.
OrderBy *OrderByClause
// Limit is the limit clause.
Limit *Limit
// LockTp is the lock type
LockTp SelectLockType
// TableHints represents the table level Optimizer Hint for join type
TableHints []*TableOptimizerHint
// IsAfterUnionDistinct indicates whether it's a stmt after "union distinct".
IsAfterUnionDistinct bool
// IsInBraces indicates whether it's a stmt in brace.
IsInBraces bool
// QueryBlockOffset indicates the order of this SelectStmt if counted from left to right in the sql text.
QueryBlockOffset int
}
对于本文提到的语句SELECT name FROM t WHERE age > 10;
name会被解析为 Fields 字段WHERE age>10会被解析为 Where 字段FROM t被解析为 From 字段
Plan
planner/core/logical_plan_builder.go
2267: func (b *PlanBuilder) buildSelect(ctx context.Context, sel *ast.SelectStmt) (p LogicalPlan, err error) {
2336: if sel.Where != nil {
p, err = b.buildSelection(ctx, p, sel.Where, nil)
if err != nil {
return nil, err
}
}
701: func (b *PlanBuilder) buildSelection(ctx context.Context, p LogicalPlan, where ast.ExprNode, AggMapper map[*ast.AggregateFuncExpr]int) (LogicalPlan, error) {
709: selection := LogicalSelection{}.Init(b.ctx, b.getSelectOffset())
740: return selection, nil
在 buildSelect 方法中,ast.SelectStmt 被逐步转成一个 LogicalPlan,也就是 Plan 树,每一个语法元素都被转换成一个逻辑查询计划单元。
例如 WHERE 会被处理为一个 core.LogicalSelection 结构。
planner/core/logical_plans.go
330: // LogicalSelection 表示一个 where 或 having 谓词
type LogicalSelection struct {
baseLogicalPlan
// 最初,WHERE或ON条件被解析为单个表达式
// 但是在我们转换为CNF(合取范式)后
// 可以将其拆分为AND条件的列表。
Conditions []expression.Expression
}
Conditions 代表了 Where 语句需要计算的表达式(若干个条件的 AND,即合取范式),当表达式值为 True 时,表明这一行符合条件。
因为 LogicalPlan 的很多字段都实现了 LogicalPlan 接口,所以我们认为把 AST 转换成了一个 Plan 树,下一步会在这个结构上进行优化。
Optimizing
planner/optimize.go
func optimize(ctx context.Context, sctx sessionctx.Context, node ast.Node, is infoschema.InfoSchema) (plannercore.Plan, types.NameSlice, float64, error) {
133: p, err := builder.Build(ctx, node) // plan
163: if !isLogicalPlan {
164: return p, names, 0, nil
172: finalPlan, cost, err := plannercore.DoOptimize(ctx, builder.GetOptFlag(), logic)
173: return finalPlan, names, cost, err
注意,回到 optimize 函数后,select 语句生成的 LogicalPlan 不会被163行捕获,会在172行进入 doOptimize 函数。
(补:在168行会有一个 Cascades 优化器的捕获判断,如果 session 中设置了使用 Cascades 优化,就会直接被捕获)
planner/core/optimizer.go
func DoOptimize(ctx context.Context, flag uint64, logic LogicalPlan) (PhysicalPlan, float64, error) {
119: logic, err := logicalOptimize(ctx, flag, logic)
126: physical, cost, err := physicalOptimize(logic)
131: return finalPlan, cost, nil
其中 logicalOptimize 和 physicalOptimize 分别代表逻辑优化和物理优化。
(下两节会做简要分析,下两篇会做具体分析。)
逻辑优化
逻辑优化由一系列规则组成,对于这些规则会按顺序不断应用到传入的 LogicalPlan Tree 中。
planner/core/optimizer.go
140: func logicalOptimize(ctx context.Context, flag uint64, logic LogicalPlan) (LogicalPlan, error) {
var err error
for i, rule := range optRuleList {
// 标志顺序与列表中 optRule 的顺序相同
// 我们使用位掩码来记录应使用的选择规则
// 如果第i位为1,意味着我们应该应用第 i 个规则
if flag&(1<<uint(i)) == 0 || isLogicalRuleDisabled(rule) {
continue
}
logic, err = rule.optimize(ctx, logic)
if err != nil {
return nil, err
}
}
return logic, err
}
const (
flagPrunColumns uint64 = 1 << iota
flagBuildKeyInfo
flagDecorrelate
flagEliminateAgg
flagEliminateProjection
flagMaxMinEliminate
flagPredicatePushDown
flagEliminateOuterJoin
flagPartitionProcessor
flagPushDownAgg
flagPushDownTopN
flagJoinReOrder
)
var optRuleList = []logicalOptRule{
&columnPruner{},
&buildKeySolver{},
&decorrelateSolver{},
&aggregationEliminator{},
&projectionEliminator{},
&maxMinEliminator{},
&ppdSolver{},
&outerJoinEliminator{},
&partitionProcessor{},
&aggregationPushDownSolver{},
&pushDownTopNOptimizer{},
&joinReOrderSolver{},
}
目前 TiDB 支持的优化规则见上,一个规则对应一个标志位。(1<<iota的写法是真的好看)
逻辑优化并不考虑数据分布,而是直接操作 Plan 树。大多数规则应用之后,一定会得到更好的 Plan.
举例来说,columnPruner (列裁剪)规则会将不需要的列裁剪掉。比如对于 select c from t; 语句,只需要返回 c 这一列的数据,就通过整个规则来实现。整个 Plan 树从树根到叶子节点递归调用整个规则,每层节点只保留上面节点所需要的列即可。
(看不懂gdlv中这里变量的表示形式,先跟着文章走)
经过逻辑优化,会得到一个查询计划:
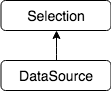
其中 FROM t 变成了 DataSource 算子, WHERE age > 10 变成了 Selection 算子。(列被裁剪掉了?)
物理优化
在物理优化阶段,会考虑数据的分布,决定如何选择物理算子。比如对于 FROM t WHERE age > 10 语句,假设在 age 字段上有索引,需要考虑是 全表扫描+过滤 的方式快还是 索引扫描 的方式快。这个选择取决于统计信息,也就是 age>10 这个条件究竟能过滤掉多少数据。
planner/core/optimizer.go
func physicalOptimize(logic LogicalPlan) (PhysicalPlan, float64, error) {
163: if _, err := logic.recursiveDeriveStats(); err != nil {
174: t, err := logic.findBestTask(prop)
planner/core/stats.go
func (p *baseLogicalPlan) recursiveDeriveStats() (*property.StatsInfo, error) {
96: for i, child := range p.children {
97: childProfile, err := child.recursiveDeriveStats()
104: return p.self.DeriveStats(childStats, p.self.Schema(), childSchema)
func (p *baseLogicalPlan) DeriveStats(childStats []*property.StatsInfo, selfSchema *expression.Schema, childSchema []*expression.Schema) (*property.StatsInfo, error) {
这里的 convert2PhysicalPlan 会递归调用下层节点的 convert2PhysicalPlan 方法,生成物理算子并且估算其代价,然后从中选择代价最小的方案,这两个函数比较重要:
recursiveDeriveStats 方法在整个 plan 树中递归调用,返回时调用 DeriveStats 方法。
(此处存疑:在干什么?plan树是一条链吗?)
planner/core/find_best_task.go
func (p *baseLogicalPlan) findBestTask(prop *property.PhysicalProperty) (bestTask task, err error) {
这里返回的结果是一个叫做 task 的结构,在 TiDB 中,Task 的定义是能在单个节点上不依赖于与其他节点进行数据交换即可进行的一系列操作。
planner/core/task.go
type task interface {
count() float64
addCost(cost float64)
cost() float64
copy() task
plan() PhysicalPlan
invalid() bool
}
由注释:
- task 存储与 task 的 cost 相关的信息
- task 可以是 CopTask, RootTask, MPPTask, ParallelTask
- copTask 是运行在分布式 kv 存储中的 task,未来可能会拆成 indexTask 与 tableTask
- rootTask 是 plan 图的汇聚节点,它在 tidb 上应该是一个单独的 goroutine.
文章:RootTask 是保留在 TiDB 中进行计算的那部分物理计划 - 项目中没有找到与 MPPTask 和 ParallelTask 有关的信息(存疑)
TiDB 的 Explain 结果中,每个 Operator 都会标明属于哪种 Task.
(先看完后面两篇再回来)
