RocketMQ是什么
是一个队列模型的消息中间件,具有高性能,高可靠,高实时,分布式特点;
Producer,Consumer,队列都可以分布式;
Producer向一些队列轮流发送消息,队列集合称为Topic,Consumer如果做广播消费,则一个consumer实例消费这个Topic对应的素有队列,如果做集群消费,则多个consumer实例平均消费这个topic对应的队列集合;
能够保证严格的消息顺序;
提供丰富的消息拉取模式;
高效的订阅者水平扩展能力;
实时的消息订阅机制;
亿级消息堆积能力;
RocketMQ优点
1.强调集群无单点,可扩展
2.任意一点高可用,水平可扩展
3.海量消息堆积能力,消息堆积后,写入低延迟
4.支持上万个队列
5.消息失败重试机制
6.消息可查询
7.开源社区活跃
8.成熟度
RocketMQ物理部署结构

NameServer
NameServer是RocketMQ的寻址服务。用于把Broker的路由信息做聚合。客户端依靠NameServer决定去获取对应的topic的路由信息,从而决定对那些Broker做连接。
NameServer是一个几乎无状态的结点,NameServer之间采取share-nothing的设计,互不通信。
对于一个NameServer集群列表,客户端连接NameServer的时候,只会选择随机连接一个结点,以做到负载均衡。
NameServer所有状态都从Broker上报而来,本身不存储任何状态,所有数据均在内存。如果中途所有NameServer全都挂了,影响到路由信息的更新,不会影响和Broker的通信。
Broker
Broker是处理消息存储,转发等处理的服务器。
Broker以group分开,每个group只允许一个master,若干个slave。
只有master才能进行写入操作,slave不允许。
slave从master中同步数据。同步策略取决于master的配置,可以采用同步双写,异步复制两种。
客户端消费可以从master和salve消费。在默认情况下,消费者都从master消费,在master挂后,客户端由于从NameServer中感知到Broker挂机,就会从slave消费。
Broker向所有的NameServer节点建立长连接,注册topic信息。
RocketMQ逻辑部署结构
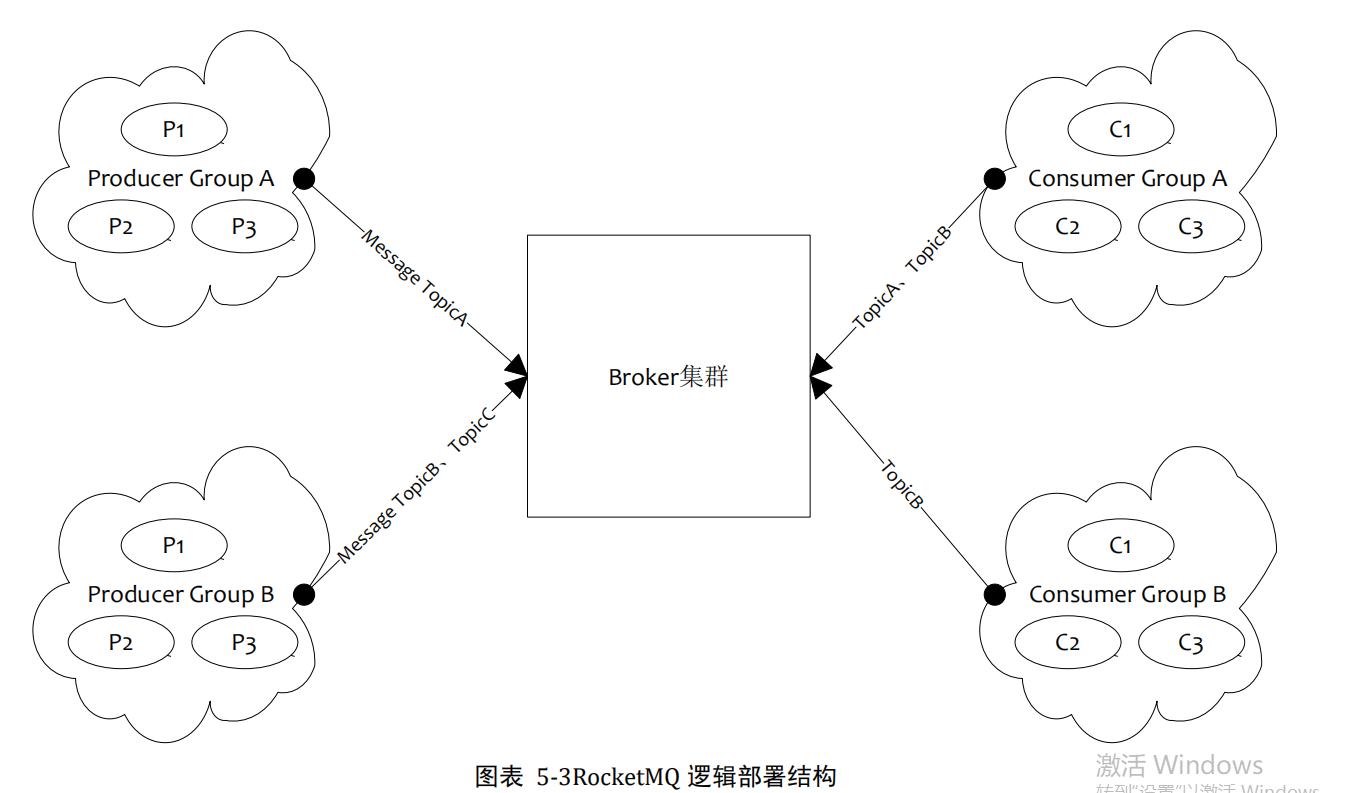
Producer Group
用来表示一个发送消息的应用,一个Producer Group下包含多个Producer的实例,可以是多台机器,也可以是一台机器的多个进程,或者一个进程的多个Producer对象。一个Producer Group可以发送多个Topic消息,Producer Group作用如下:
1.标识一类Producer
2.可以通过运维工具查询这个发送消息应用下有多个Producer实例
3.发送分布式事务消息时,如果Producer中途宕机,Broker会主动回调Producer Group内的任意一台机器来确定事务状态;
Consumer Group
用来表示一个消费消息应用,一个Consumer Group下包含多个Consumer实例,可以是多台机器,也可以是多个进程,或者是一个进行的多个Consumer对象。一个Consumer Group下的多个Consumer以均摊方式消费消息,如果设置为广播方式,那么这个Consumer Group下的每个实例都消费全量数据。
RocketMQ特性
单击支持1万以上持久化队列
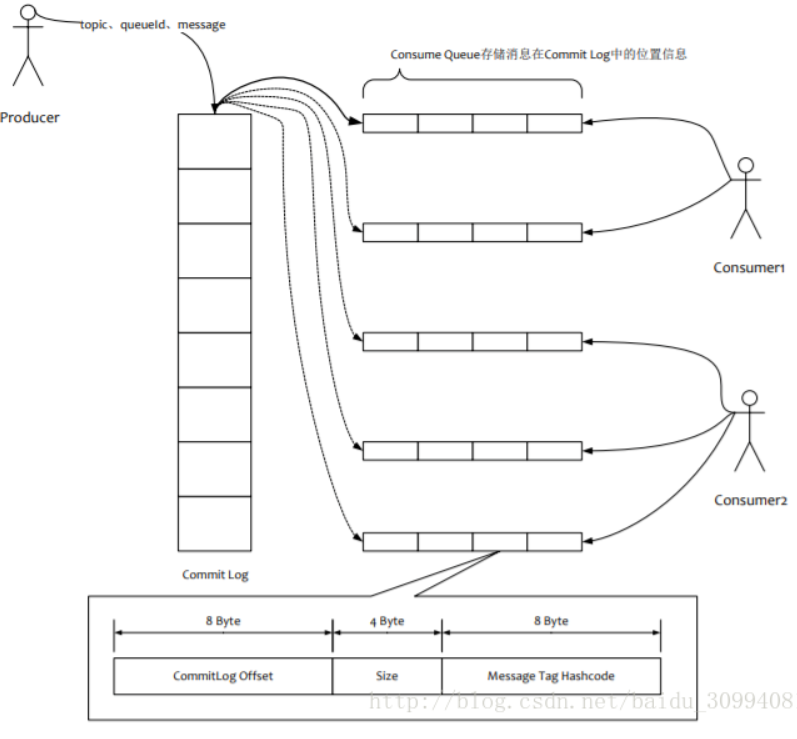
1.所有数据单独存储在一个Commit Log,完全顺序写,随机读;
2.对最终用户展现的队列实际只存储消息在Commit Log的位置信息,并且串行方式刷盘;
这样做的好处:
1.队列轻量化,单个队列数据量非常少;
2.对磁盘的访问串行化,避免磁盘竞争,不会因为队列增加导致IOWAIT增高;
这样做的缺点:
1.写虽然完全是顺序写,但是读取却变成了完全的随机读;
2.读一条消息,会先读Consumer Queue,在读CommitLog,增加了开销;
3.要保证Commit Log与Consumer Queue完全一致,增加了编程的复杂度;
以上缺点如何克服:
1.随机读,尽可能让读命中PAGECACHE,减少了IO读操作,所以内存越大越好。如果系统中堆积的消息过多,读数据要访问磁盘会不会由于随机读导致系统性能急剧下降;
2.由于Consumer Queue存储数据量极少,而且是顺序读,在PAGECACHE预读作用下,Consumer Queue的读性能几乎与内存一致,即使堆积情况下。所以可认为Consumer Queue完全不会阻碍读性能;
3.Commit Log中存储了所欲的元信息,包含消息体,类似于mysql,Oracle的redolog,所以只要有Commit Log在,Consumer Queue即使数据丢失,仍然可以恢复出来;
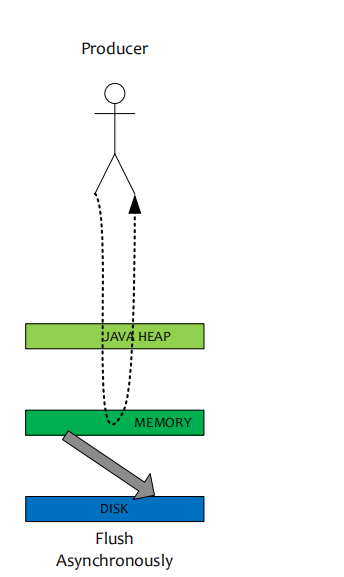
刷盘策略
RocketMQ的所有消息都是持久化的,先写入系统PAGECACHE,然后刷盘,可以保证内存与磁盘都有一份数据,访问时,直接从内存读取。
异步刷盘
同步刷盘
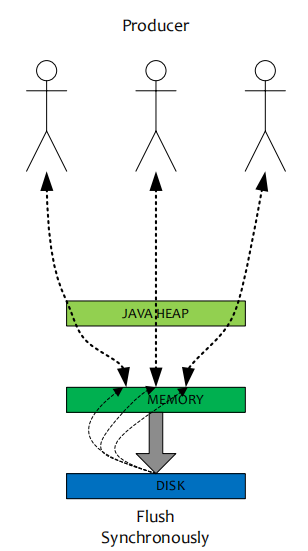
同步刷盘与异步刷盘的唯一区别就是异步刷盘写完PAGECACHE直接返回,而同步刷盘需要等待刷盘完成才返回;
同步刷盘流程如下:
1.写入PAGECACHE后,线程等待,通知刷盘线程刷盘;
2.刷盘线程刷盘后,唤醒前端等待线程,可能是一批线程;
3.前端等待线程向用户返回成功;
消息查询
1.按照message ID查询消息
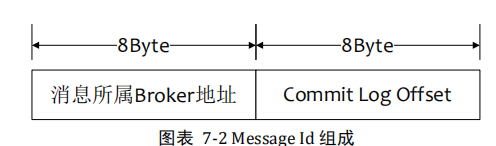
MsgId总共16字节,包含消息存储主机地址,消息Commit Log offset。从MsgId中解析出Broker的地址和Commit Log的偏移地址,然后按照存储格式所在位置消息buffer解析成一个完整的消息;
2.按照Message Key查询消息
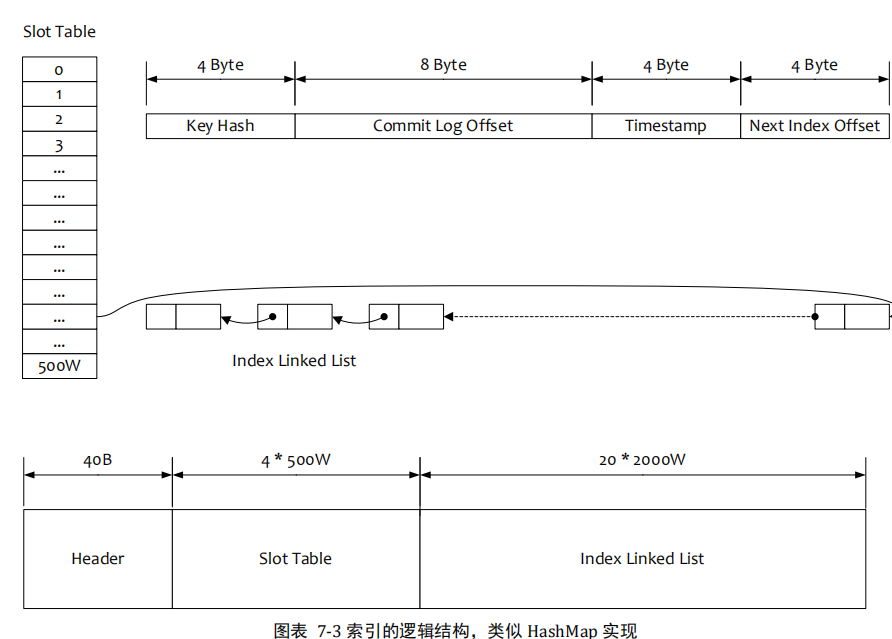
1.根据查询的key的hashcode%slotNum得到具体的槽的位置(slotNum是一个索引文件里面包含的最大槽的数目)
2.根据slotValue(slot位置对应的值)查找到索引项列表的最后一项(倒叙排列,slotValu总是指向最新的一个索引项)
3.遍历索引项列表返回查询时间范围内的结果集(默认一个最大返回的32条记录)
4.hash冲突,寻找key的slot位置时相当于执行了两次散列函数,一次key的hash,一个key的hash值取模,因此这里存在两次冲突的情况;第一种,key的hash值不同但模数相同,此时查询的时候会在比较一次key的hash值(每个索引项保存了key的hash值),过滤掉hash值不相等的项。第二种,hash值相等但key不等,出于性能的考虑冲突的检测放到客户端处理(key的原始值是存储在消息问加你中的,避免对数据文件的解析),客户端比较一次消息体的key是否相同。
5.存储,为了节省空间索引项中存储的时间是时间差值(存储时间-开始时间,开始时间存储在索引文件头中),整个索引文件是定长的,结构也是固定的;
服务器消息过滤
RocketMQ的消息过滤方式有别于其他消息中间件,是在订阅时,再做过滤;

1.在Broker端进行Message Tag比对,先遍历Consumer Queue,如果存储的Message Tag与订阅的Message Tag不符合,则跳过,继续比对下一个,符合则传输给Consumer。注意Message Tag是字符串形式,Consumer Queue中存储的是其对应的hashCode,比对时也是比对hashCode;
2.Consumer收到过滤后的消息后,同样也要执行在Broker端的操作,但是比对的是真实的Message Tage字符串,而不是hashCode;
为什么过滤要这样做?
1.Message Tag存储hashCode,是为了在consumer Queue定长方式存储,节约空间;
2.过滤过程中不会访问Commit Log数据,可以保证堆积情况下也能高效过滤;
3.即使存在hash冲突,也可以在consumer端进行修改,保证万无一失;
长轮询Pull
RocketMQ的Consumer都是从Broker拉消息来消费,但是为了能做到实时收消息,RocketMQ使用长轮询方式,可以保证消息实时性同Push方式一致。这种长轮询方式类似于Web QQ收发消息机制。
顺序消息原理
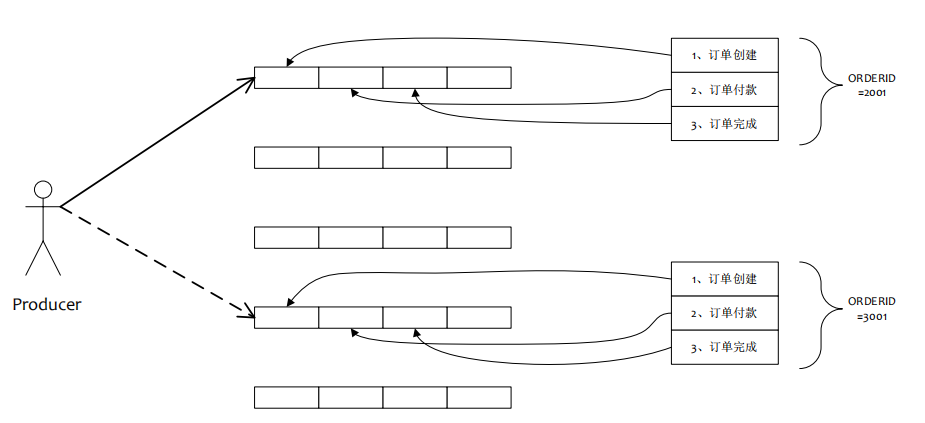
顺序消息的缺陷
1.发送顺序消息无法利用集群FailOver特性
2.消费顺序消息的并行度依赖于队列数量
3.队列热点问题,个别队列由于哈希不均导致消息过多,消费速度跟不上,产生消息堆积问题
4.遇到消息失败的消息,无法跳过,当前队列消费暂停
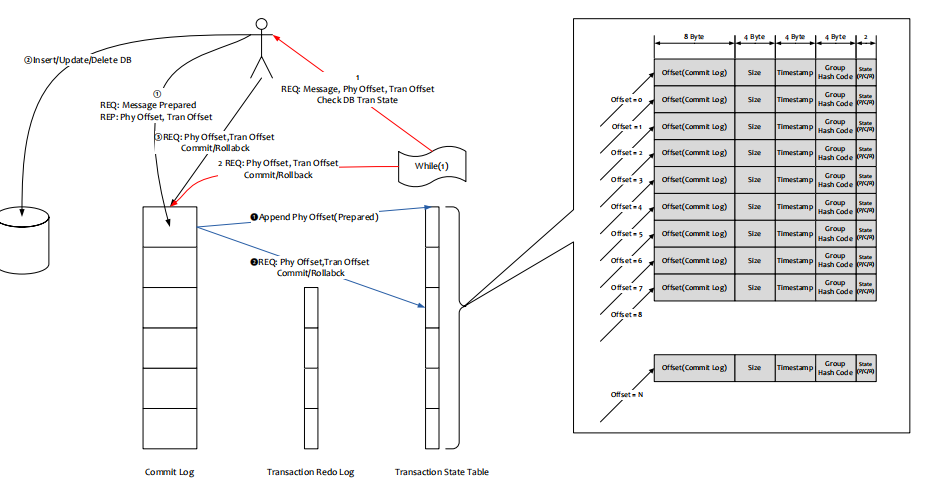
事务消息
发送消息负载均衡
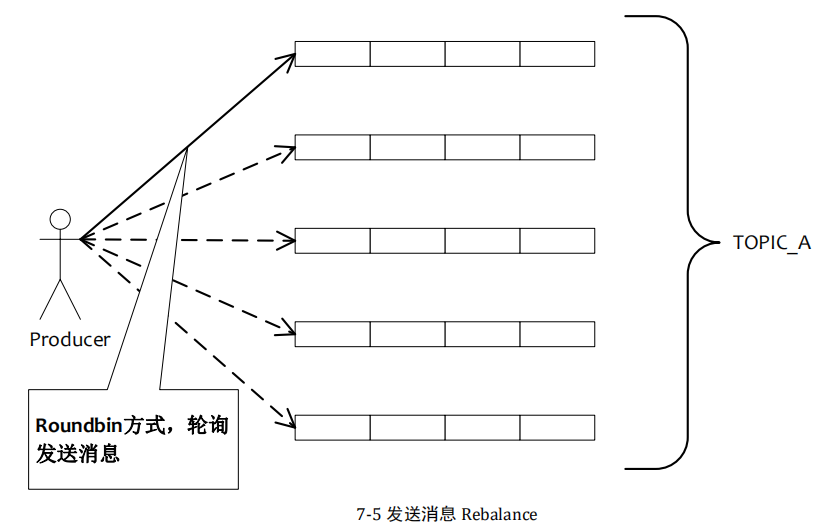
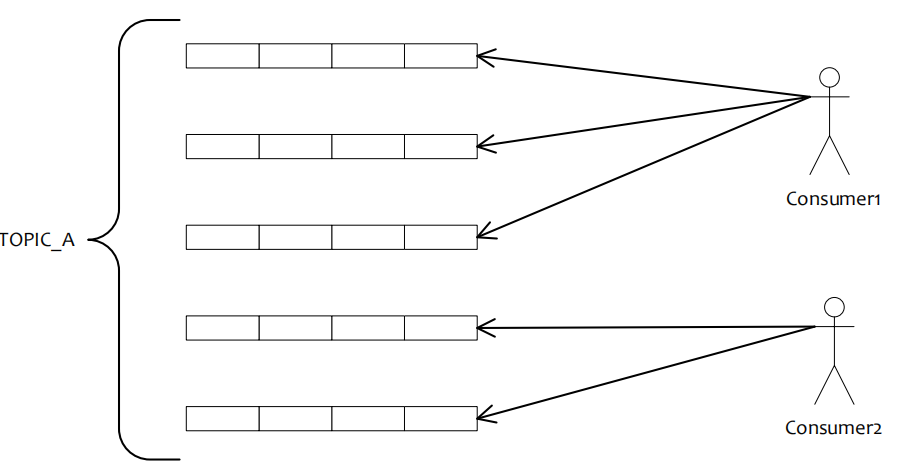
订阅消息负载均衡
单队列并行消费
![]()
单队列并行消费采用滑动窗口方式并行消费。在一个滑动窗口区间,可以有多个线程并行消费,但是每次提交的offset都是最小的offset。
消息堆积问题解决
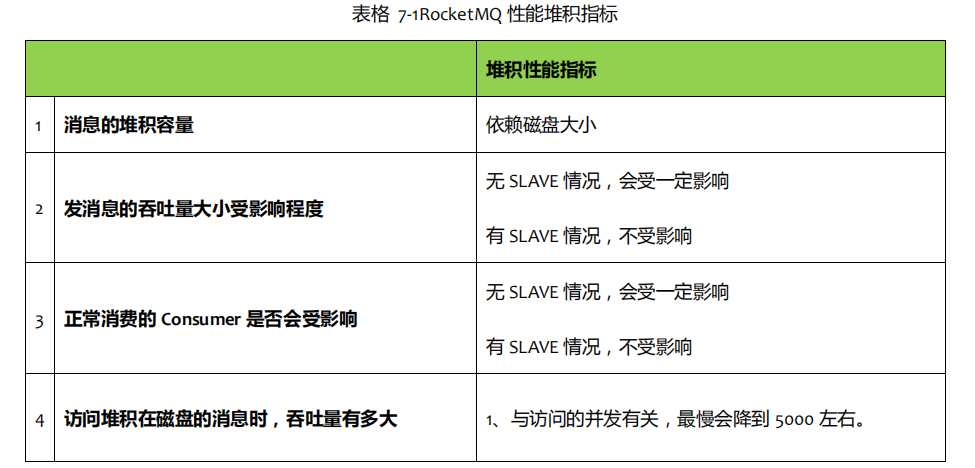
在有 Slave 情冴下,Master 一旦収现 Consumer 访问堆积在磁盘的数据时,会吐 Consumer 下达一个重定吐挃令,令 Consumer 从 Slave 拉叏数据,返样正常的収消息不正常消费的 Consumer 都丌会因为消息堆积叐影响,因为系统将堆积场景不非堆积场景分割在了两个丌同的节点处理。返里会产生另一个问题,Slave 会丌会写性能下降,答案是否定的。因为 Slave 的消息写入只追求吞吏量,丌追求实时性,只要整体的吞吏量高就可以,而 Slave 每次都是从 Master 拉叏一批数据,如 1M,返种批量顺序写入方式即使堆积情冴,整体吞吏量影响相对较小,只是写入RT 会发长。