RocketMq下载安装
- 下载网址:http://rocketmq.apache.org/dowloading/releases/
- 系统要求64bit Linux、Unix或Mac,JDK版本>=1.8

什么是消息队列
消息队列 MQ 既可为分布式应用系统提供异步解耦和削峰填谷的能力,同时也具备互联网应用所需的海量消息堆积、高吞吐、可靠重试等特性。
应用场景
- 削峰填谷
诸如秒杀、抢红包、企业开门红等大型活动时皆会带来较高的流量脉冲,或因没做相应的保护而导致系统超负荷甚至崩溃,或因限制太过导致请求大量失败而影响用户体验,消息队列 MQ 可提供削峰填谷的服务来解决该问题,比如生成订单系统每秒只能处理10000次下单,而双十一明显不是这个级别,这时候就可以把大量需要生成订单的单子分散到一段时间来生成,这时候用户要十几秒才能收到下单成功的消息,但是总比不能下单要好
- 异步解耦
交易系统作为淘宝/天猫主站最核心的系统,每笔交易订单数据的产生会引起几百个下游业务系统的关注,包括物流、购物车、积分、流计算分析等等,整体业务系统庞大而且复杂,消息队列 MQ 可实现异步通信和应用解耦,确保主站业务的连续性。
- 顺序收发
细数日常中需要保证顺序的应用场景非常多,例如证券交易过程时间优先原则,交易系统中的订单创建、支付、退款等流程,航班中的旅客登机消息处理等等。与先进先出(First In First Out,缩写 FIFO)原理类似,消息队列 MQ 提供的顺序消息即保证消息 FIFO。
- 分布式事务一致性
交易系统、支付红包等场景需要确保数据的最终一致性,大量引入消息队列 MQ 的分布式事务,既可以实现系统之间的解耦,又可以保证最终的数据一致性。
- 大数据分析
数据在“流动”中产生价值,传统数据分析大多是基于批量计算模型,而无法做到实时的数据分析,利用阿里云消息队列 MQ 与流式计算引擎相结合,可以很方便的实现将业务数据进行实时分析。
- 分布式缓存同步
天猫双 11 大促,各个分会场琳琅满目的商品需要实时感知价格变化,大量并发访问数据库导致会场页面响应时间长,集中式缓存因为带宽瓶颈限制商品变更的访问流量,通过消息队列 MQ 构建分布式缓存,实时通知商品数据的变化。
更多信息请参见适用场景。
核心概念
- Topic:消息主题,一级消息类型,通过 Topic 对消息进行分类。详情请参见 Topic 与 Tag 最佳实践。
- Message ID:消息的全局唯一标识,由消息队列 MQ 系统自动生成,唯一标识某条消息。
- Message Key:消息的业务标识,由消息生产者(Producer)设置,唯一标识某个业务逻辑。
- Tag:消息标签,二级消息类型,用来进一步区分某个 Topic 下的消息分类。详情请参见 Topic 与 Tag 最佳实践。
- Producer:消息生产者,也称为消息发布者,负责生产并发送消息。
- Producer 实例:Producer 的一个对象实例,不同的 Producer 实例可以运行在不同进程内或者不同机器上。Producer 实例线程安全,可在同一进程内多线程之间共享。
- Consumer:消息消费者,也称为消息订阅者,负责接收并消费消息。
- Consumer 实例:Consumer 的一个对象实例,不同的 Consumer 实例可以运行在不同进程内或者不同机器上。一个 Consumer 实例内配置线程池消费消息。
- 队列:每个 Topic 下会由一到多个队列来存储消息。每个 Topic 对应队列数与消息类型以及实例所处地域(Region)相关,具体的队列数可提交工单咨询。
- Exactly-Once 投递语义:Exactly-Once 投递语义是指发送到消息系统的消息只能被 Consumer 处理且仅处理一次,即使 Consumer 重试消息发送导致某消息重复投递,该消息在 Consumer 也只被消费一次。详情请参见 Exactly-Once 投递语义。
- Group ID:Group 的标识。
- Group:一类 Producer 或 Consumer,这类 Producer 或 Consumer 通常生产或消费同一类消息,且消息发布或订阅的逻辑一致。
- 集群消费:一个 Group ID 所标识的所有 Consumer 平均分摊消费消息。例如某个 Topic 有 9 条消息,一个 Group ID 有 3 个 Consumer 实例,那么在集群消费模式下每个实例平均分摊,只消费其中的 3 条消息。详情请参见集群消费和广播消费。
- 广播消费:一个 Group ID 所标识的所有 Consumer 都会各自消费某条消息一次。例如某个 Topic 有 9 条消息,一个 Group ID 有 3 个 Consumer 实例,那么在广播消费模式下每个实例都会各自消费 9 条消息。详情请参见集群消费和广播消费。
- 定时消息:Producer 将消息发送到消息队列 MQ 服务端,但并不期望这条消息立马投递,而是推迟到在当前时间点之后的某一个时间投递到 Consumer 进行消费,该消息即定时消息。详情请参见定时和延时消息。
- 延时消息:Producer 将消息发送到消息队列 MQ 服务端,但并不期望这条消息立马投递,而是延迟一定时间后才投递到 Consumer 进行消费,该消息即延时消息。详情请参见定时和延时消息。
- 事务消息:消息队列 MQ 提供类似 X/Open XA 的分布事务功能,通过消息队列 MQ 的事务消息能达到分布式事务的最终一致。详情请参见事务消息。
- 顺序消息:消息队列 MQ 提供的一种按照顺序进行发布和消费的消息类型,分为全局顺序消息和分区顺序消息。详情请参见顺序消息。
- 全局顺序消息:对于指定的一个 Topic,所有消息按照严格的先入先出(FIFO)的顺序进行发布和消费。详情请参见顺序消息。
- 分区顺序消息:对于指定的一个 Topic,所有消息根据 Sharding Key 进行区块分区。同一个分区内的消息按照严格的 FIFO 顺序进行发布和消费。Sharding Key 是顺序消息中用来区分不同分区的关键字段,和普通消息的 Message Key 是完全不同的概念。详情请参见顺序消息。
- 消息堆积:Producer 已经将消息发送到消息队列 MQ 的服务端,但由于 Consumer 消费能力有限,未能在短时间内将所有消息正确消费掉,此时在消息队列 MQ 的服务端保存着未被消费的消息,该状态即消息堆积。
- 消息过滤:Consumer 可以根据消息标签(Tag)对消息进行过滤,确保 Consumer 最终只接收被过滤后的消息类型。消息过滤在消息队列 MQ 的服务端完成。详情请参见消息过滤。
- 消息轨迹:在一条消息从 Producer 发出到 Consumer 消费处理过程中,由各个相关节点的时间、地点等数据汇聚而成的完整链路信息。通过消息轨迹,您能清晰定位消息从 Producer 发出,经由消息队列 MQ 服务端,投递给 Consumer 的完整链路,方便定位排查问题。详情请参见查询消息轨迹。
- 重置消费位点:以时间轴为坐标,在消息持久化存储的时间范围内(默认 3 天),重新设置 Consumer 对已订阅的 Topic 的消费进度,设置完成后 Consumer 将接收设定时间点之后由 Producer 发送到消息队列 MQ 服务端的消息。详情请参见重置消费位点。
- 死信队列:死信队列用于处理无法被正常消费的消息。当一条消息初次消费失败,消息队列 MQ 会自动进行消息重试;达到最大重试次数后,若消费依然失败,则表明 Consumer 在正常情况下无法正确地消费该消息。此时,消息队列 MQ 不会立刻将消息丢弃,而是将这条消息发送到该 Consumer 对应的特殊队列中。
- 消息路由:消息路由常用于不同地域之间的消息同步,保证地域之间的数据一致性。消息队列 MQ 的全球消息路由功能依托阿里云优质基础设施实现的高速通道专线,可以高效地实现国内外不同地域之间的消息同步复制。详情请参见全球消息路由。
- 生产者:也称为消息发布者,负责生产并发送消息至 Topic。
- 消费者:也称为消息订阅者,负责从 Topic 接收并消费消息。
- 消息:生产者向 Topic 发送并最终传送给消费者的数据和(可选)属性的组合。
- 消息属性:生产者可以为消息定义的属性,包含 Message Key 和 Tag。
- Group:一类生产者或消费者,这类生产者或消费者通常生产或消费同一类消息,且消息发布或订阅的逻辑一致。
消息队列 MQ 涉及的概念的详细解释,请参见名词解释。
消息收发模型
消息队列 MQ 支持发布/订阅模型,消息生产者应用创建 Topic 并将消息发送到 Topic。消费者应用创建对 Topic 的订阅以便从其接收消息。通信可以是一对多(扇出)、多对一(扇入)和多对多。
- 生产者集群:用来表示发送消息应用,一个生产者集群下包含多个生产者实例,可以是多台机器,也可以是一台机器的多个进程,或者一个进程的多个生产者对象。
一个生产者集群可以发送多个 Topic 消息。发送分布式事务消息时,如果生产者中途意外宕机,Broker 会主动回调生产者集群的任意一台机器来确认事务状态。
- 消费者集群:用来表示消费消息应用,一个消费者集群下包含多个消费者实例,可以是多台机器,也可以是多个进程,或者是一个进程的多个消费者对象。
一个消费者集群下的多个消费者以均摊方式消费消息。如果设置的是广播方式,那么这个消费者集群下的每个实例都消费全量数据。
一个消费者集群对应一个 Group ID,一个 Group ID 可以订阅多个 Topic,如图中的 Group 2 所示。Group 和 Topic 的订阅关系可以通过直接在程序中设置即可。
mq的启动和收发消息
启动单机服务队列比较简单,不需要写配置文件只需要依次启动本机器的NameServer(邮局)和Broker(暂存)即可。
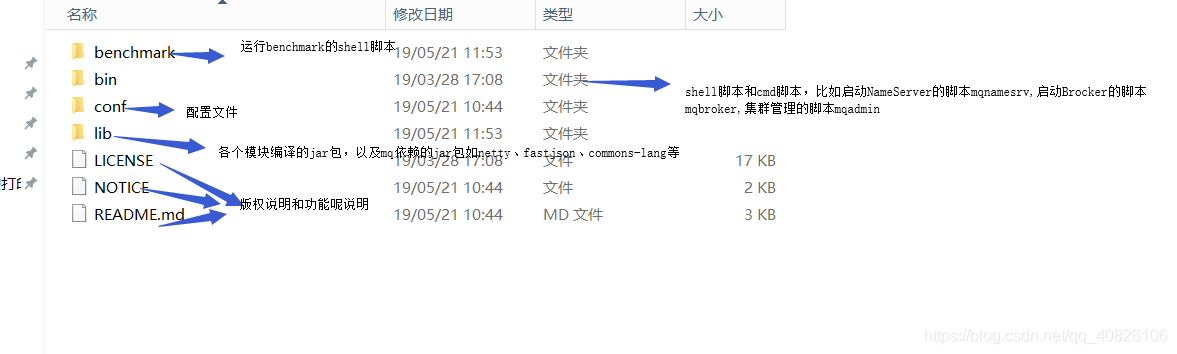
启动Nameserver(进入到mq的安装目录)
> nohup sh bin/mqnamesrv &
> logs humingming$ tail -f ~/logs/rocketmqlogs/namesrv.log启动Broker(进入到mq的安装目录)
> nohup sh bin/mqbroker -n localhost:9876&
> tail -f ~/logs/rocketmqlogs/broker.log用命令发送和接收消息
> export NAMESRV_ADDR=localhost:9876
> sh bin/tools.sh org.apache.rocketmq.example.quickstart.Producer消息发送截图

消息接收
> sh bin/tools.sh org.apache.rocketmq.example.quickstart.Consumer消息接收截图
关闭消息队列:
因为我们的服务一直是开着的,如果不关闭则会在后台一直运行,占用系统资源,我们有专门的的命令来关闭Nameserver 和 Broker
> sh bin/mqshutdown broker --必须在rocketmq的安装目录下执行 mqshutdown是斌目录下的命令> sh bin/mqshutdown namesrv备注:
- 在应用Unix/Linux时,我们一般想让某个程序在后台运行,于是我们将常会用 & 在程序结尾来让程序自动运行。比如我们要运行mysql在后台: /usr/local/mysql/bin/mysqld_safe –user=mysql &。可是有很多程序并不想mysqld一样,这样我们就需要nohup命令。语法:nohup Command [ Arg … ] [ & ]
- 通常rocketmq安装完成后会在用户目录下生成logs/文件夹,里面记录着mq的各种日志
- 在shell中执行程序时,shell会提供一组环境变量。 export可新增,修改或删除环境变量,供后续执行的程序使用。export的效力仅及于该此登陆操作。语法:export [-fnp][变量名称]=[变量设置值]
RocketMq各个角色介绍和使用
RocketMq由四部分组成,先来直观的了解下这些角色及其功能。分布式消息队列是可以用来高效的传输消息,它的功能和现实生活中邮局的收发信件很类似。现实生活中邮政系统的正常运行离不开四个角色,一是发发信者、二是收信者、三是负责暂存、四是传输的邮局,对应到MQ四个角色就是Producer、Consumer、Broker、NameServer,启动MQ的顺序先启动NameServer在启动Broker,这时候消息队列就已经可以提供服务了,发送消息就是用Producer,接收消息就使用Consumer来接收,很多程序既要接收又要收发则需要启动多个Producer和Consumer来发送和接受各种消息。
为消除单点故障,增加可靠性和吞吐量,可以在多态机器上部署多个NameServer和Broker,每个Broker部署一个或多个Slave

同大多数mq一样,一个分布式消息中间件部署好以后,可以供很多业务提供服务,同一个业务也有不同类型的消息要进行投递,这些不同类型的消息以不同的Topic名称来区分,所以在发送消息和接受消息之前要先创建Topic,针对某个Topic进行发送和接受消息。有了Topic之后还需解决性能问题,如果一个Topic要发送和接受的消息数据量非常大的话,需要支持能增加并行处理的机器来提高速度,这时候Topic可以设置一个或多个Message Quene类似分区,Topic有了Message Queue后,消息可以并行的向各个Message Queue发送,消费者也可以并行的从多个Message Queue读取消息并消费
