目录:
01_数据库的基本使用
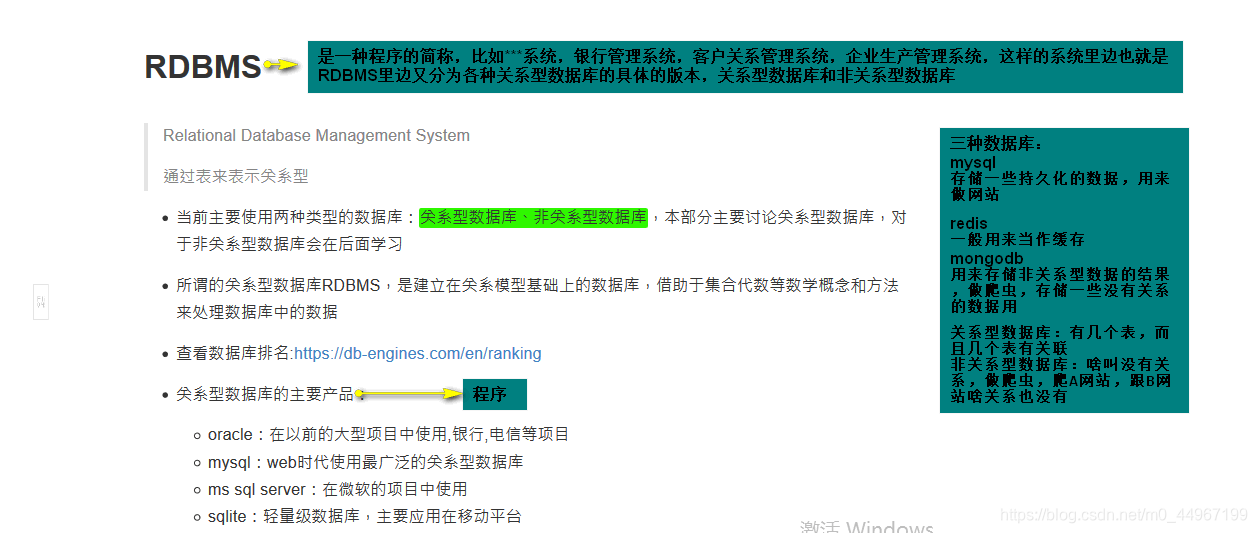
01_数据库的简介


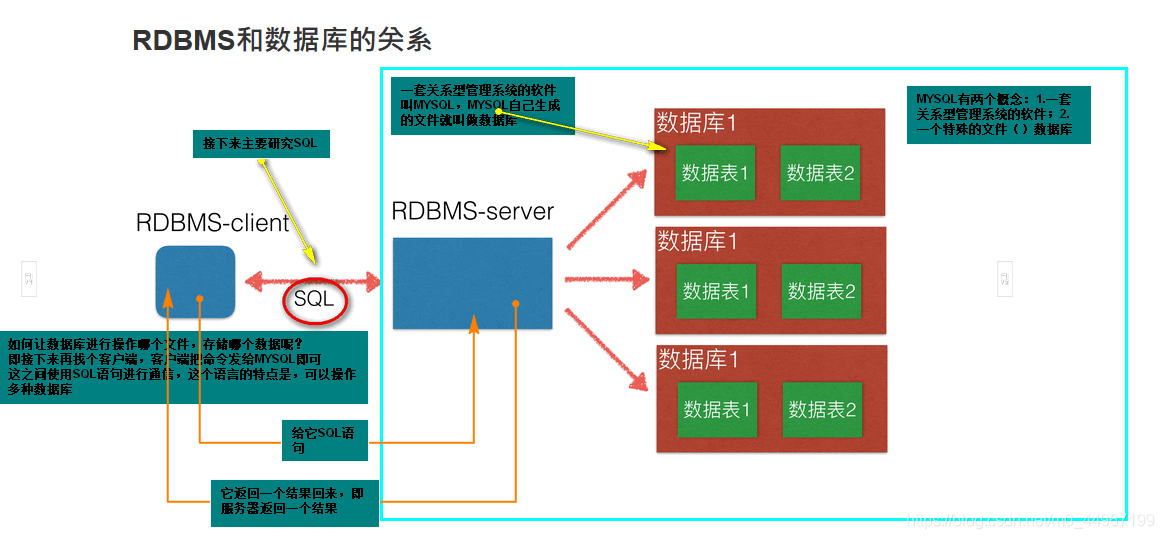
02_RDBMS与数据库的关系

03_数据库的准备与查询
-- 数据的准备
-- 创建一个数据库
create database python_test charset=utf8; -- 默认的类型是lating..不符合中文输入,故要用utf8
-- 使用一个数据库
use python_test;
-- 显示使用的当前数据是哪个?(要得到一个信息,一般用select)
select database();
-- 创建一个数据表
-- students表
create table students(
id int unsigned primary key auto_increment not null,
name varchar(20) default '',
age tinyint unsigned default 0,
height decimal(5,2),
gender enum('男','女','中性','保密') default '保密', -- enum:枚举
cls_id int unsigned default 0,
is_delete bit default 0 -- (只写bit意味着为bit(1),不是1就是0;再大的值的话就换成别的类型,tinyint..bit(2):由(00,11,01,10,)对应着0,1,2,3)
);
-- classes表
create table classes (
id int unsigned auto_increment primary key not null,
name varchar(30) not null
);
-- 查询
-- 查询所有字段
-- select * from 表名;
select * from students;
select * from classes;
select id, name from classes;
-- 查询指定字段
-- select 列1,列2,... from 表名;
select name, age from students;
-- 使用 as 给字段起别名
-- select 字段 as 名字.... from 表名;
select name as 姓名, age as 年龄 from students;
-- select 表名.字段 .... from 表名;
select students.name, students.age from students; -- 这个方法可以区分不同表之间的取值
-- 可以通过 as 给表起别名
-- select 别名.字段 .... from 表名 as 别名;
select students.name, students.age from students;
select s.name, s.age from students as s; -- 给表起个别名,起了就要用
-- 失败的select students.name, students.age from students as s;
-- 消除重复行
-- distinct 字段 -- 去重
select distinct gender from students;
-- 条件查询(很简单,加上where,后边写条件即可)
-- 比较运算符
-- select .... from 表名 where .....
-- >
-- 查询大于18岁的信息
select * from students where age>18;
select id,name,gender from students where age>18; -- (一定非要前边有什么后边就要有什么,只要表中含有该字段即可)
-- 前边的字段之间使用","间隔
-- <
-- 查询小于18岁的信息
select * from students where age<18;
-- >=
-- <=
-- 查询小于或者等于18岁的信息
-- =
-- 查询年龄为18岁的所有学生的名字
select * from students where age=18; -- (判断相等的时候是一个等号)
-- != 或者 <>
-- 逻辑运算符
-- and
-- 18到28之间的所有学生信息
select * from students where age>18 and age<28; -- (要求在逻辑运算符的两侧都要包含完整的字段)
-- 失败select * from students where age>18 and <28;
-- 18岁以上的女性
select * from students where age>18 and gender="女";
select * from students where age>18 and gender=2;
-- or
-- 18以上或者身高超过180(包含)以上
select * from students where age>18 or height>=180;
-- not
-- 不在 18岁以上的女性 这个范围内的信息
-- select * from students where not age>18 and gender=2;
select * from students where not (age>18 and gender=2);
-- 优先级的问题(对于优先级,不要去背,一切靠括号解决,谁优先就给谁套上一个)
-- 年龄不是小于或者等于18 并且是女性
select * from students where (not age<=18) and gender=2;
-- 模糊查询(记不住的时候使用模糊查询,效率有点低)
-- 模糊查询的两种方式:like/rlike (想要用模糊查询,通常用like即可,话说回来效率较低,因为要匹配所有字段)
-- like:
-- % 替换1个或者多个
-- _ 替换1个
-- 查询姓名中 以 "小" 开始的名字
select name from students where name="小"; -- 要求名字必须等于"小"
select name from students where name like "小%"; -- 以"小"开头的名字
-- 查询姓名中 有 "小" 所有的名字
select name from students where name like "%小%";
-- 查询有2个字的名字
select name from students where name like "__";
-- 查询有3个字的名字
select name from students where name like "__";
-- 查询至少有2个字的名字
select name from students where name like "__%";
-- rlike 正则
-- 查询以 周开始的姓名
select name from students where name rlike "^周.*"; -- "^"表示:以xxx开始 eg:^周:以周开始."*"表示有任意个
-- 查询以 周开始、伦结尾的姓名
select name from students where name rlike "^周.*伦$"; -- "$"表示:以xxx结尾 eg:%伦:以伦结尾."*"表示有任意个
-- 范围查询
-- in (1, 3, 8)表示在一个非连续的范围
-- 查询 年龄为18、34的姓名
select name,age from students where age=18 or age=34;
select name,age from students where age=18 or age=34 or age=12;
select name,age from students where age in (12, 18, 34);
-- not in 不非连续的范围之内
-- 年龄不是 18、34岁之间的信息
select name,age from students where age not in (12, 18, 34);
-- between ... and ...表示在一个连续的范围内
-- 查询 年龄在18到34之间的的信息
select name, age from students where age between 18 and 34;
-- not between ... and ...表示不在一个连续的范围内
-- 查询 年龄不在在18到34之间的的信息
select * from students where age not between 18 and 34;
-- select * from students where not age between 18 and 34;(可以,但不要用,别乱了)
-- 失败的用法select * from students where age not (between 18 and 34);
-- 空判断
-- 判空is null
-- 查询身高为空的信息
select * from students where height is null;
select * from students where height is NULL;
select * from students where height is Null;
-- 判非空is not null
select * from students where height is not null;
-- 排序
-- order by 字段
-- asc从小到大排列,即升序
-- desc从大到小排序,即降序
-- 查询年龄在18到34岁之间的男性,按照年龄从小到到排序
select * from students where (age between 18 and 34) and gender=1;
select * from students where (age between 18 and 34) and gender=1 order by age; -- age 后边啥也不写默认为asc:从小到大排序
select * from students where (age between 18 and 34) and gender=1 order by age asc;
-- 查询年龄在18到34岁之间的女性,身高从高到矮排序
select * from students where (age between 18 and 34) and gender=2 order by height desc; -- desc从大到小排序
-- 上边语句的括号加不加都行,加上的可读性强
-- order by 多个字段
-- 查询年龄在18到34岁之间的女性,先按照身高从高到矮排序, 如果身高相同的情况下按照年龄从小到大排序(如果不写后边的会默认按照主键排序)
select * from students where (age between 18 and 34) and gender=2 order by height desc,id desc;
-- 查询年龄在18到34岁之间的女性,身高从高到矮排序, 如果身高相同的情况下按照年龄从小到大排序,
-- 如果年龄也相同那么按照id从大到小排序
select * from students where (age between 18 and 34) and gender=2 order by height desc,age asc,id desc;
-- 按照年龄从小到大、身高从高到矮的排序
select * from students order by age asc, height desc;
-- 聚合函数(是一个函数,可以用来计算某个值)
-- 总数
-- count
-- 查询男性有多少人,女性有多少人
select * from students where gender=1;
select count(*) from students where gender=1;
select count(*) as 男性人数 from students where gender=1;
select count(*) as 女性人数 from students where gender=2;
-- 最大值
-- max
-- 查询最大的年龄
select age from students;
select max(age) from students;
-- 查询女性的最高 身高
select max(height) from students where gender=2;
-- 最小值
-- min
-- 求和
-- sum
-- 计算所有人的年龄总和
select sum(age) from students;
-- 平均值
-- avg
-- 计算平均年龄
select avg(age) from students;
-- 计算平均年龄 sum(age)/count(*)
select sum(age)/count(*) from students;
-- 四舍五入 round(123.23 , 1) 保留1位小数 -- 技巧:为了保证数据的准确性,存储数据的时候将小数*相应的位数变为整数,处理完成后导出时再除以相应的位数,即要保存准确的值尽量不要用小数,都是约等于
-- 计算所有人的平均年龄,保留2位小数
select round(sum(age)/count(*), 2) from students;
select round(sum(age)/count(*), 3) from students;
-- 计算男性的平均身高 保留2位小数
select round(avg(height), 2) from students where gender=1;
-- select name, round(avg(height), 2) from students where gender=1;
-- 分组(意义:与聚合混合在一起使用)
-- group by
-- 按照性别分组,查询所有的性别
select name from students group by gender;
select * from students group by gender;
select gender from students group by gender; -- select ? from "?"一般要填可以作为区分各个组的唯一标识的字段(按什么分的组填什么?)
-- 失败select * from students group by gender;
-- 失败select name from students group by gender;
-- 计算每种性别中的人数
select gender,count(*) from students group by gender;
-- 此时的count(*)是对分组的结果计算个数(即分别计算各个组里边的人数)(体现出了聚合的作用)
-- 计算男性的人数
select gender,count(*) from students where gender=1 group by gender;
-- group_concat(...) (想输出什么就把什么写在括号里边)
-- 与where的不同:having 是对查出来的结果进行判断,where是对原表数据进行判断
-- 查询同种性别中的姓名
select gender,group_concat(name) from students where gender=1 group by gender;
select gender,group_concat(name, age, id) from students where gender=1 group by gender;
select gender,group_concat(name, "_", age, " ", id) from students where gender=1 group by gender;
-- having(对分组进行条件判断(即达到某些要求),分完组之后不显示所有分组)
-- 查询平均年龄超过30岁的性别,以及姓名 having avg(age) > 30
select gender, group_concat(name),avg(age) from students group by gender having avg(age)>30;
-- 查询每种性别中的人数多于2个的信息
select gender, group_concat(name) from students group by gender having count(*)>2;
-- 分页 ---> limit (第N页-1)*每页的个数, 每页的个数;(必须算出来,只能是6,2这种形式)
-- limit start, count
-- limit使用方式:一.limit后边加上要显示(查询出来的个数)的个数
-- 限制查询出来的数据个数
select * from students where gender=1 limit 2;
-- limit使用方式:二.limit 从哪个开始搜,往下搜几条数据 (限制从哪到哪的个数,从而实现分页)
-- 查询前5个数据
select * from students limit 0, 5;
-- 查询id6-10(包含)的书序
select * from students limit 5, 5;
-- 每页显示2个,第1个页面
select * from students limit 0,2;
-- 每页显示2个,第2个页面
select * from students limit 2,2;
-- 每页显示2个,第3个页面
select * from students limit 4,2;
-- 每页显示2个,第4个页面
select * from students limit 6,2; -- -----> limit (第N页-1)*每页的个数, 每页的个数;
-- 每页显示2个,显示第6页的信息, 按照年龄从小到大排序
-- 失败select * from students limit 2*(6-1),2;
-- 失败select * from students limit 10,2 order by age asc; (limit放在最后)
select * from students order by age asc limit 10,2;
select * from students where gender=2 order by height desc limit 0,2;
-- 连接查询(链接多个表,取多个表的共用数据)(多表时有应用,单表时不会用)
-- inner join ... on(内联接)
-- select ... from 表A inner join 表B;
select * from students inner join classes;
-- 查询 有能够对应班级的学生以及班级信息
select * from students inner join classes on students.cls_id=classes.id;
-- 内连接就是取交集,看on后边的条件,如果可以匹配上就取交集
-- 按照要求显示姓名、班级
select students.*, classes.name from students inner join classes on students.cls_id=classes.id;
select students.name, classes.name from students inner join classes on students.cls_id=classes.id;
-- 给数据表起名字
select s.name, c.name from students as s inner join classes as c on s.cls_id=c.id;
-- 查询 有能够对应班级的学生以及班级信息,显示学生的所有信息,只显示班级名称
select s.*, c.name from students as s inner join classes as c on s.cls_id=c.id;
-- 在以上的查询中,将班级姓名显示在第1列
select c.name, s.* from students as s inner join classes as c on s.cls_id=c.id;
-- 查询 有能够对应班级的学生以及班级信息, 按照班级进行排序
-- select c.xxx s.xxx from student as s inner join clssses as c on .... order by ....;
select c.name, s.* from students as s inner join classes as c on s.cls_id=c.id order by c.name;
-- 当时同一个班级的时候,按照学生的id进行从小到大排序
select c.name, s.* from students as s inner join classes as c on s.cls_id=c.id order by c.name,s.id;
-- left join(左联接)
-- 查询每位学生对应的班级信息
select * from students as s left join classes as c on s.cls_id=c.id;
-- 谁写在left join的左边就以谁为集准,找到对应的就显示,找不到就不显示,显示NULL就行了
-- 查询没有对应班级信息的学生
-- select ... from xxx as s left join xxx as c on..... where .....(原表之中)
-- select ... from xxx as s left join xxx as c on..... having .....(查找之后的结果.对分组进行条件判断(即达到某些要求),分完组之后不显示所有分组)
select * from students as s left join classes as c on s.cls_id=c.id having c.id is null;
select * from students as s left join classes as c on s.cls_id=c.id where c.id is null;
-- right join on
-- 将数据表名字互换位置,用left join完成
-- 自关联(自己这个表里边两(多)个字段相互关联)(多用于省市县,上下级)
-- 省级联动 url:http://demo.lanrenzhijia.com/2014/city0605/
-- 查询所有省份
select * from areas where pid is null;
-- 查询出山东省有哪些市(使用下边的子查询也行)
-- 两步法:先找出山东的id,再看看哪些市的p_id是山东的id即可;(将一张表理解为两张表,使用时,表越多越不好)
-- 一步法:将一个做两次命名,当作两个表使用,使条件为:city.pid=province.aid
select * from areas as province inner join areas as city on city.pid=province.aid having province.atitle="山东省";
select province.atitle, city.atitle from areas as province inner join areas as city on city.pid=province.aid having province.atitle="山东省";
-- 查询出青岛市有哪些县城
select province.atitle, city.atitle from areas as province inner join areas as city on city.pid=province.aid having province.atitle="青岛市";
select * from areas where pid=(select aid from areas where atitle="青岛市");
-- 子查询(一个select里边还嵌套着另一个select)
-- 标量子查询
-- 查询出高于平均身高的信息
-- 查询最高的男生信息
select * from students where height = 188;
select * from students where height = (select max(height) from students);
-- 先执行select子语句:(select max(height) from students),执行结束后得到一个结论,
-- 接下来将这个结论当做另外一个语句的条件进行查询
-- 列级子查询
-- 查询学生的班级号能够对应的学生信息
-- select * from students where cls_id in (select id from classes);
04_数据库的操作之增删改查
-- 数据的准备
-- 创建一个数据库
create database python_test charset=utf8; -- 默认的类型是lating..不符合中文输入,故要用utf8
-- 使用一个数据库
use python_test;
-- 显示使用的当前数据是哪个?(要得到一个信息,一般用select)
select database();
-- 创建一个数据表
-- students表
create table students(
id int unsigned primary key auto_increment not null,
name varchar(20) default '',
age tinyint unsigned default 0,
height decimal(5,2),
gender enum('男','女','中性','保密') default '保密', -- enum:枚举
cls_id int unsigned default 0,
is_delete bit default 0 -- (只写bit意味着为bit(1),不是1就是0;再大的值的话就换成别的类型,tinyint..bit(2):由(00,11,01,10,)对应着0,1,2,3)
);
-- classes表
create table classes (
id int unsigned auto_increment primary key not null,
name varchar(30) not null
);
-- 查询
-- 查询所有字段
-- select * from 表名;
select * from students;
select * from classes;
select id, name from classes;
-- 查询指定字段
-- select 列1,列2,... from 表名;
select name, age from students;
-- 使用 as 给字段起别名
-- select 字段 as 名字.... from 表名;
select name as 姓名, age as 年龄 from students;
-- select 表名.字段 .... from 表名;
select students.name, students.age from students; -- 这个方法可以区分不同表之间的取值
-- 可以通过 as 给表起别名
-- select 别名.字段 .... from 表名 as 别名;
select students.name, students.age from students;
select s.name, s.age from students as s; -- 给表起个别名,起了就要用
-- 失败的select students.name, students.age from students as s;
-- 消除重复行
-- distinct 字段 -- 去重
select distinct gender from students;
-- 条件查询(很简单,加上where,后边写条件即可)
-- 比较运算符
-- select .... from 表名 where .....
-- >
-- 查询大于18岁的信息
select * from students where age>18;
select id,name,gender from students where age>18; -- (一定非要前边有什么后边就要有什么,只要表中含有该字段即可)
-- 前边的字段之间使用","间隔
-- <
-- 查询小于18岁的信息
select * from students where age<18;
-- >=
-- <=
-- 查询小于或者等于18岁的信息
-- =
-- 查询年龄为18岁的所有学生的名字
select * from students where age=18; -- (判断相等的时候是一个等号)
-- != 或者 <>
-- 逻辑运算符
-- and
-- 18到28之间的所有学生信息
select * from students where age>18 and age<28; -- (要求在逻辑运算符的两侧都要包含完整的字段)
-- 失败select * from students where age>18 and <28;
-- 18岁以上的女性
select * from students where age>18 and gender="女";
select * from students where age>18 and gender=2;
-- or
-- 18以上或者身高超过180(包含)以上
select * from students where age>18 or height>=180;
-- not
-- 不在 18岁以上的女性 这个范围内的信息
-- select * from students where not age>18 and gender=2;
select * from students where not (age>18 and gender=2);
-- 优先级的问题(对于优先级,不要去背,一切靠括号解决,谁优先就给谁套上一个)
-- 年龄不是小于或者等于18 并且是女性
select * from students where (not age<=18) and gender=2;
-- 模糊查询(记不住的时候使用模糊查询,效率有点低)
-- 模糊查询的两种方式:like/rlike (想要用模糊查询,通常用like即可,话说回来效率较低,因为要匹配所有字段)
-- like:
-- % 替换1个或者多个
-- _ 替换1个
-- 查询姓名中 以 "小" 开始的名字
select name from students where name="小"; -- 要求名字必须等于"小"
select name from students where name like "小%"; -- 以"小"开头的名字
-- 查询姓名中 有 "小" 所有的名字
select name from students where name like "%小%";
-- 查询有2个字的名字
select name from students where name like "__";
-- 查询有3个字的名字
select name from students where name like "__";
-- 查询至少有2个字的名字
select name from students where name like "__%";
-- rlike 正则
-- 查询以 周开始的姓名
select name from students where name rlike "^周.*"; -- "^"表示:以xxx开始 eg:^周:以周开始."*"表示有任意个
-- 查询以 周开始、伦结尾的姓名
select name from students where name rlike "^周.*伦$"; -- "$"表示:以xxx结尾 eg:%伦:以伦结尾."*"表示有任意个
-- 范围查询
-- in (1, 3, 8)表示在一个非连续的范围
-- 查询 年龄为18、34的姓名
select name,age from students where age=18 or age=34;
select name,age from students where age=18 or age=34 or age=12;
select name,age from students where age in (12, 18, 34);
-- not in 不非连续的范围之内
-- 年龄不是 18、34岁之间的信息
select name,age from students where age not in (12, 18, 34);
-- between ... and ...表示在一个连续的范围内
-- 查询 年龄在18到34之间的的信息
select name, age from students where age between 18 and 34;
-- not between ... and ...表示不在一个连续的范围内
-- 查询 年龄不在在18到34之间的的信息
select * from students where age not between 18 and 34;
-- select * from students where not age between 18 and 34;(可以,但不要用,别乱了)
-- 失败的用法select * from students where age not (between 18 and 34);
-- 空判断
-- 判空is null
-- 查询身高为空的信息
select * from students where height is null;
select * from students where height is NULL;
select * from students where height is Null;
-- 判非空is not null
select * from students where height is not null;
-- 排序
-- order by 字段
-- asc从小到大排列,即升序
-- desc从大到小排序,即降序
-- 查询年龄在18到34岁之间的男性,按照年龄从小到到排序
select * from students where (age between 18 and 34) and gender=1;
select * from students where (age between 18 and 34) and gender=1 order by age; -- age 后边啥也不写默认为asc:从小到大排序
select * from students where (age between 18 and 34) and gender=1 order by age asc;
-- 查询年龄在18到34岁之间的女性,身高从高到矮排序
select * from students where (age between 18 and 34) and gender=2 order by height desc; -- desc从大到小排序
-- 上边语句的括号加不加都行,加上的可读性强
-- order by 多个字段
-- 查询年龄在18到34岁之间的女性,先按照身高从高到矮排序, 如果身高相同的情况下按照年龄从小到大排序(如果不写后边的会默认按照主键排序)
select * from students where (age between 18 and 34) and gender=2 order by height desc,id desc;
-- 查询年龄在18到34岁之间的女性,身高从高到矮排序, 如果身高相同的情况下按照年龄从小到大排序,
-- 如果年龄也相同那么按照id从大到小排序
select * from students where (age between 18 and 34) and gender=2 order by height desc,age asc,id desc;
-- 按照年龄从小到大、身高从高到矮的排序
select * from students order by age asc, height desc;
-- 聚合函数(是一个函数,可以用来计算某个值)
-- 总数
-- count
-- 查询男性有多少人,女性有多少人
select * from students where gender=1;
select count(*) from students where gender=1;
select count(*) as 男性人数 from students where gender=1;
select count(*) as 女性人数 from students where gender=2;
-- 最大值
-- max
-- 查询最大的年龄
select age from students;
select max(age) from students;
-- 查询女性的最高 身高
select max(height) from students where gender=2;
-- 最小值
-- min
-- 求和
-- sum
-- 计算所有人的年龄总和
select sum(age) from students;
-- 平均值
-- avg
-- 计算平均年龄
select avg(age) from students;
-- 计算平均年龄 sum(age)/count(*)
select sum(age)/count(*) from students;
-- 四舍五入 round(123.23 , 1) 保留1位小数 -- 技巧:为了保证数据的准确性,存储数据的时候将小数*相应的位数变为整数,处理完成后导出时再除以相应的位数,即要保存准确的值尽量不要用小数,都是约等于
-- 计算所有人的平均年龄,保留2位小数
select round(sum(age)/count(*), 2) from students;
select round(sum(age)/count(*), 3) from students;
-- 计算男性的平均身高 保留2位小数
select round(avg(height), 2) from students where gender=1;
-- select name, round(avg(height), 2) from students where gender=1;
-- 分组(意义:与聚合混合在一起使用)
-- group by
-- 按照性别分组,查询所有的性别
select name from students group by gender;
select * from students group by gender;
select gender from students group by gender; -- select ? from "?"一般要填可以作为区分各个组的唯一标识的字段(按什么分的组填什么?)
-- 失败select * from students group by gender;
-- 失败select name from students group by gender;
-- 计算每种性别中的人数
select gender,count(*) from students group by gender;
-- 此时的count(*)是对分组的结果计算个数(即分别计算各个组里边的人数)(体现出了聚合的作用)
-- 计算男性的人数
select gender,count(*) from students where gender=1 group by gender;
-- group_concat(...) (想输出什么就把什么写在括号里边)
-- 与where的不同:having 是对查出来的结果进行判断,where是对原表数据进行判断
-- 查询同种性别中的姓名
select gender,group_concat(name) from students where gender=1 group by gender;
select gender,group_concat(name, age, id) from students where gender=1 group by gender;
select gender,group_concat(name, "_", age, " ", id) from students where gender=1 group by gender;
-- having(对分组进行条件判断(即达到某些要求),分完组之后不显示所有分组)
-- 查询平均年龄超过30岁的性别,以及姓名 having avg(age) > 30
select gender, group_concat(name),avg(age) from students group by gender having avg(age)>30;
-- 查询每种性别中的人数多于2个的信息
select gender, group_concat(name) from students group by gender having count(*)>2;
-- 分页 ---> limit (第N页-1)*每页的个数, 每页的个数;(必须算出来,只能是6,2这种形式)
-- limit start, count
-- limit使用方式:一.limit后边加上要显示(查询出来的个数)的个数
-- 限制查询出来的数据个数
select * from students where gender=1 limit 2;
-- limit使用方式:二.limit 从哪个开始搜,往下搜几条数据 (限制从哪到哪的个数,从而实现分页)
-- 查询前5个数据
select * from students limit 0, 5;
-- 查询id6-10(包含)的书序
select * from students limit 5, 5;
-- 每页显示2个,第1个页面
select * from students limit 0,2;
-- 每页显示2个,第2个页面
select * from students limit 2,2;
-- 每页显示2个,第3个页面
select * from students limit 4,2;
-- 每页显示2个,第4个页面
select * from students limit 6,2; -- -----> limit (第N页-1)*每页的个数, 每页的个数;
-- 每页显示2个,显示第6页的信息, 按照年龄从小到大排序
-- 失败select * from students limit 2*(6-1),2;
-- 失败select * from students limit 10,2 order by age asc; (limit放在最后)
select * from students order by age asc limit 10,2;
select * from students where gender=2 order by height desc limit 0,2;
-- 连接查询(链接多个表,取多个表的共用数据)(多表时有应用,单表时不会用)
-- inner join ... on(内联接)
-- select ... from 表A inner join 表B;
select * from students inner join classes;
-- 查询 有能够对应班级的学生以及班级信息
select * from students inner join classes on students.cls_id=classes.id;
-- 内连接就是取交集,看on后边的条件,如果可以匹配上就取交集
-- 按照要求显示姓名、班级
select students.*, classes.name from students inner join classes on students.cls_id=classes.id;
select students.name, classes.name from students inner join classes on students.cls_id=classes.id;
-- 给数据表起名字
select s.name, c.name from students as s inner join classes as c on s.cls_id=c.id;
-- 查询 有能够对应班级的学生以及班级信息,显示学生的所有信息,只显示班级名称
select s.*, c.name from students as s inner join classes as c on s.cls_id=c.id;
-- 在以上的查询中,将班级姓名显示在第1列
select c.name, s.* from students as s inner join classes as c on s.cls_id=c.id;
-- 查询 有能够对应班级的学生以及班级信息, 按照班级进行排序
-- select c.xxx s.xxx from student as s inner join clssses as c on .... order by ....;
select c.name, s.* from students as s inner join classes as c on s.cls_id=c.id order by c.name;
-- 当时同一个班级的时候,按照学生的id进行从小到大排序
select c.name, s.* from students as s inner join classes as c on s.cls_id=c.id order by c.name,s.id;
-- left join(左联接)
-- 查询每位学生对应的班级信息
select * from students as s left join classes as c on s.cls_id=c.id;
-- 谁写在left join的左边就以谁为集准,找到对应的就显示,找不到就不显示,显示NULL就行了
-- 查询没有对应班级信息的学生
-- select ... from xxx as s left join xxx as c on..... where .....(原表之中)
-- select ... from xxx as s left join xxx as c on..... having .....(查找之后的结果.对分组进行条件判断(即达到某些要求),分完组之后不显示所有分组)
select * from students as s left join classes as c on s.cls_id=c.id having c.id is null;
select * from students as s left join classes as c on s.cls_id=c.id where c.id is null;
-- right join on
-- 将数据表名字互换位置,用left join完成
-- 自关联(自己这个表里边两(多)个字段相互关联)(多用于省市县,上下级)
-- 省级联动 url:http://demo.lanrenzhijia.com/2014/city0605/
-- 查询所有省份
select * from areas where pid is null;
-- 查询出山东省有哪些市(使用下边的子查询也行)
-- 两步法:先找出山东的id,再看看哪些市的p_id是山东的id即可;(将一张表理解为两张表,使用时,表越多越不好)
-- 一步法:将一个做两次命名,当作两个表使用,使条件为:city.pid=province.aid
select * from areas as province inner join areas as city on city.pid=province.aid having province.atitle="山东省";
select province.atitle, city.atitle from areas as province inner join areas as city on city.pid=province.aid having province.atitle="山东省";
-- 查询出青岛市有哪些县城
select province.atitle, city.atitle from areas as province inner join areas as city on city.pid=province.aid having province.atitle="青岛市";
select * from areas where pid=(select aid from areas where atitle="青岛市");
-- 子查询(一个select里边还嵌套着另一个select)
-- 标量子查询
-- 查询出高于平均身高的信息
-- 查询最高的男生信息
select * from students where height = 188;
select * from students where height = (select max(height) from students);
-- 先执行select子语句:(select max(height) from students),执行结束后得到一个结论,
-- 接下来将这个结论当做另外一个语句的条件进行查询
-- 列级子查询
-- 查询学生的班级号能够对应的学生信息
-- select * from students where cls_id in (select id from classes);
02_MYSQL与Python交互
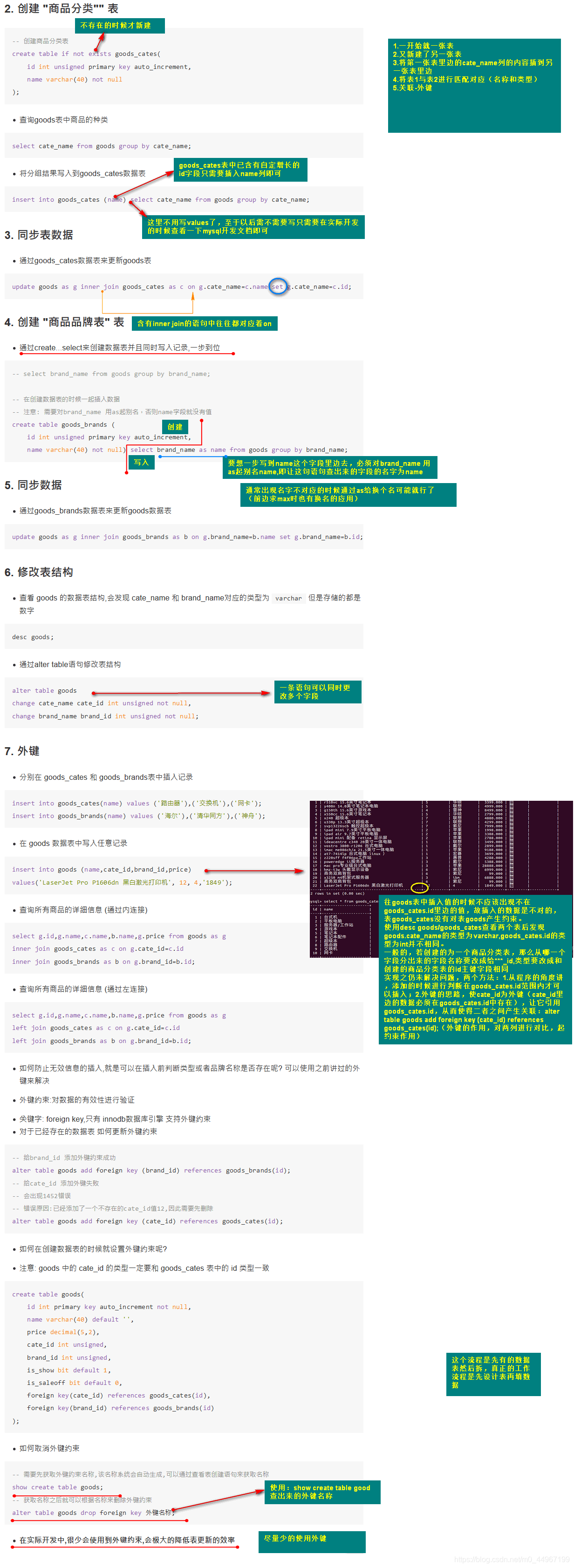
01_数据操作演练-拆为多个表
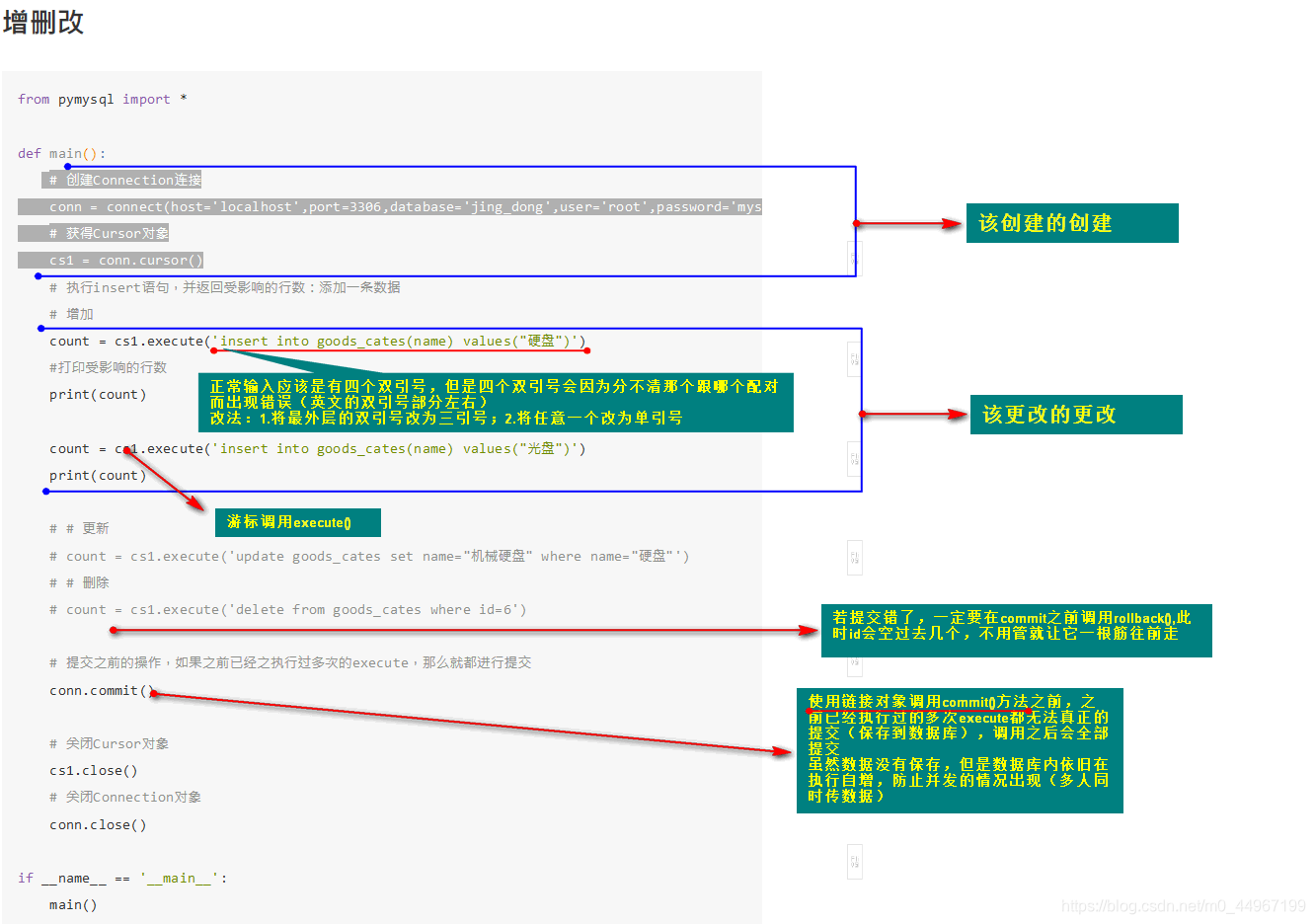
02_京东数据查询-面向过程自己写
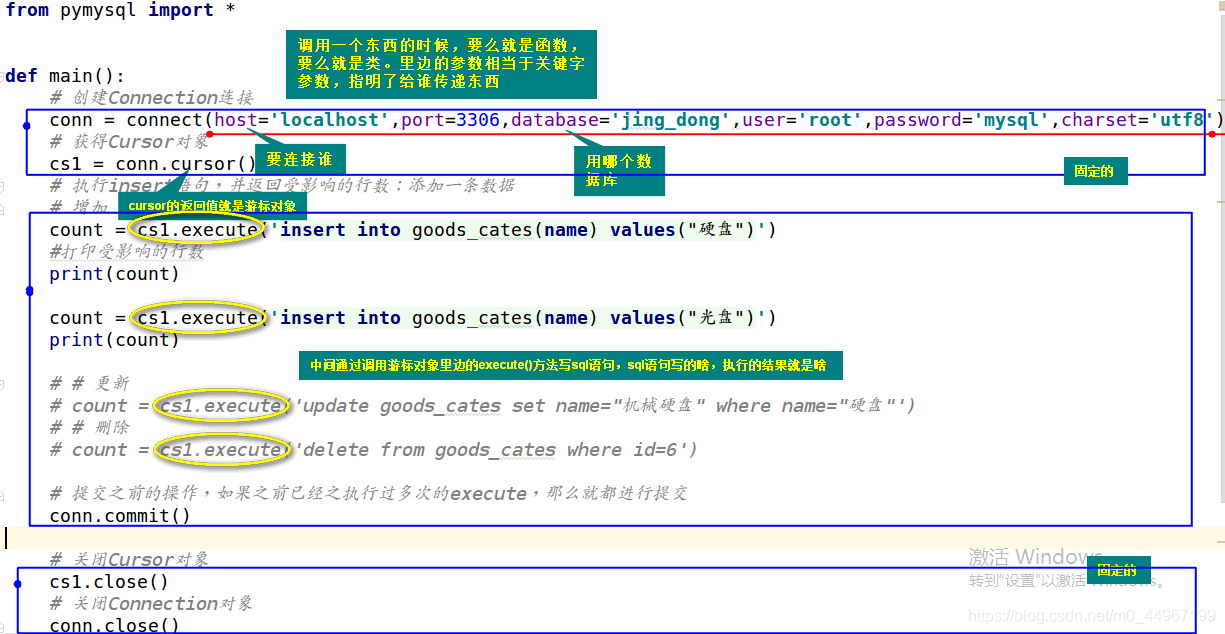
from pymysql import *
def main():
while True:
# 创建Connection连接
conn = connect(host='localhost',port=3306,database='jing_dong',user='root',password='mysql',charset='utf8')
# 获得Cursor对象
cursor = conn.cursor()
user_need = int(input("请选择您所需要的功能:1.查询所有的信息;2.查所有的分类;3.查所有的品牌分类:"))
if user_need == 1:
cursor.execute("select * from goods;")
print(cursor.fetchall())
elif user_need == 2:
cursor.execute("select name from goods_cates;")
print(cursor.fetchall())
elif user_need == 3:
cursor.execute("select name from goods_brands;")
print(cursor.fetchall())
# 关闭Cursor对象
cursor.close()
# 关闭Connection对象
conn.close()
if __name__ == '__main__':
main()
03_京东数据查询-过度
from pymysql import connect
class JD(object):
"""类名使用大驼峰隔开,函数/变量名使用下划线隔开"""
def __init__(self):
pass
def show_all_goods(self):
"""展示所有商品"""
"""
按照下边这种写法存在一些问题,这三个方法一点关系也没有,只要每执行一次这三个方法
就要连接,执行,然后断开.使用的是短连接(为了获取个东西(数据)三次握手过去(连接),
请求,回来,四次挥手回来(断开),再用再连再断).在这里能不能变成长连接(能用同一个
连接,连接上就不松开了,直到所有的请求结束).其实这就是一个体现,能用一个连接当然是
用一个连接,就不用断开了,断开了还需要再连,连接是浪费时间的.
不断开要考虑的:连接之后下一次再执行放法的时候就不用在连接,那么信息就应该找一个地方
存起来,不是随着方法的结束就结束的,而是只要这个对象不死,它的数据就会保存着.
那么数据应该存在哪里呢?
四个地方:
1.类对象(基类)
2.实例对象
由于只创建了一个对象jd,所以直接放在里边即可,对象不死,就一直处在连接中,具体思路见03
3.全局变量
在类的外边定义一个变量存储conn对象.没有任何问题,但是不太好.既然用类了,难道还要去
考虑全局变量吗,不用全局变量尽量不用
4.局部变量
存在函数里边是局部变量,局部变量是每次执行方法/函数的时候重新赋值,上一次的值就不会有了,
所以局部变量不行
"""
# 创建connection连接
conn = connect(host='localhost', port=3306, database='jing_dong', user='root', password='mysql',charset='utf8')
# 获得Cursor对象
cs1 = self.conn.cursor()
sql = "select * from goods;"
self.cs1.execute(sql)
information = self.cs1.fetchall()
for temp in information:
print(temp)
# 关闭cursor对象
cs1.close()
conn.close()
def show_goods_cates(self):
"""展示所有商品种类"""
# 创建connection连接
conn = connect(host='localhost', port=3306, database='jing_dong', user='root', password='mysql', charset='utf8')
# 获得Cursor对象
cs1 = self.conn.cursor()
sql = "select name from goods_cates;"
self.cs1.execute(sql)
information = self.cs1.fetchall()
for temp in information:
print(temp)
# 关闭cursor对象
cs1.close()
conn.close()
def show_goods_brands(self):
"""展示所有商品品牌"""
# 创建connection连接
conn = connect(host='localhost', port=3306, database='jing_dong', user='root', password='mysql', charset='utf8')
# 获得Cursor对象
cs1 = self.conn.cursor()
sql = "select name from goods_brands"
self.cs1.execute(sql)
information = self.cs1.fetchall()
for temp in information:
print(temp)
# 关闭cursor对象
cs1.close()
conn.close()
def run(self):
"""实例方法,一定含有self"""
while True:
print("-----京东商城-----")
print("1.所有的商品")
print("2.所有的商品种类")
print("3.所有的商品品牌")
usc = input("请输入所需的产品功能:")
if usc == "1":
"""
写"1"是因为input()输入的都是字符串,之所以不使用int对input进行强制类
型转换,是因为转换之后用户输成字母程序会出错
"""
"""
在这里是调用一个方法好呢,还是调用一个函数好呢?要是调用函数的话,直接在类的
外部定义一个函数,使用函数名调用,但是,既然说main函数是用来启动整个函数的
话,那么使用的时候能封装到一个类里边尽量封装到一个类里边,不要再节外生枝再
定义一个函数了.封装到一个类里边的时候要注意,每个需要使用类对象或者实例对象
的方法里边一定含有一个参数self(只有一个方法中需要用到类对象或者实例对象时
才需要写self,静态方法就不用),其他的需要传参的再另写不管是类里边的属性还是
方法,在类里边调用的时候都要使用self.属性名/方法名的方式(self就相当于实例
对象自己,即相当于实例对象调用方法)
"""
# 查询所有商品
self.show_all_goods()
elif usc == "2":
# 查询商品种类
self.show_goods_cates()
elif usc == "3":
# 查询品牌分类
self.show_goods_brands()
else:
print("您的输入有误,请重新输入:")
def main():
"""用来完成主体的控制,所以mian函数越简单越好,想尽一切办法让main函数尽可能的简单,这就是封装"""
# 1.创建一个京东对象
jd = JD()
# 调用这个对象的run方法,让其执行
jd.run()
if __name__ == '__main__':
main()
04_京东数据查询-面向对象
from pymysql import connect
class JD(object):
"""类名使用大驼峰隔开,函数/变量名使用下划线隔开"""
"""
好好体会这样(面向对象)写的优点:能封装的全都封装了,将来调用者调用的时候很简单,
实现的过程很复杂
将来去嵌套调用方法这个优点也很好:如果将这些基本的方法放到一个基本的基类里边去,
接下来通过类的三大特性之一-继承,接下来可以重新写一些新的方法,重写就得以实现
(怎么理解:一位方法分的很细,重写的时候不会影响其他方法的实现)
"""
def __init__(self):
"""下边的代码目的是:一创建对象就连接"""
"""为了在其他方法中可以够到(使用)conn/cs1,使用self.使其变为实例属性"""
self.conn = connect(host='localhost',port=3306,database='jing_dong',user='root',password='mysql',charset='utf8')
# 获得Cursor对象
self.cs1 = self.conn.cursor()
def __del__(self):
"""关闭cursor对象"""
"""创建一个对象,使用类名可以创建一个对象,收回一个对象一定会销毁,要么使用
__del__(仅销毁对象可不写,若有其他的需要随着对象关闭而关闭的就可以使用这个
方法)这个方法删除,要么python解释器一定会自己把对象删除掉,所以方法__del__
在最后不用调用一定会执行
"""
self.cs1.close()
self.conn.close()
def execute_sql(self,sql):
self.cs1.execute(sql)
information = self.cs1.fetchall()
for temp in information:
print(temp)
def show_all_goods(self):
"""展示所有商品"""
sql = "select * from goods;"
self.execute_sql(sql)
# 要执行sql语句就要用execute(),返回行数,要输出需要调用fetch
def show_goods_cates(self):
"""展示所有商品种类"""
sql = "select name from goods_cates;"
self.execute_sql(sql)
def show_goods_brands(self):
"""展示所有商品品牌"""
sql = "select name from goods_brands"
self.execute_sql(sql)
# 使用实例对象可以调用任何方法,类对象只能调用类方法(self就相当于实例对象自己在调用方法)
@staticmethod
def print_menu():
"""显示菜单是一个整体,放在run方法中显得run方法太长了,拿出来单独定义一个方法"""
"""由于只有一个方法中需要用到类对象或者实例对象时才需要写self,这个方法不需要
实例对象也不需要类对象,只需打印即可,为静态方法,标注:@staticmethod"""
"""这个方法要有返回值"""
print("-----京东商城-----")
print("1.所有的商品")
print("2.所有的商品种类")
print("3.所有的商品品牌")
return input("请输入所需的产品功能:")
def run(self):
"""实例方法,一定含有self"""
while True:
usc = self.print_menu()
if usc == "1":
"""
写"1"是因为input()输入的都是字符串,之所以不使用int对input进行强制类
型转换,是因为转换之后用户输成字母程序会出错
"""
"""
在这里是调用一个方法好呢,还是调用一个函数好呢?要是调用函数的话,直接在类的
外部定义一个函数,使用函数名调用,但是,既然说main函数是用来启动整个函数的
话,那么使用的时候能封装到一个类里边尽量封装到一个类里边,不要再节外生枝再
定义一个函数了.封装到一个类里边的时候要注意,每个需要使用类对象或者实例对象
的方法里边一定含有一个参数self(只有一个方法中需要用到类对象或者实例对象时
才需要写self,静态方法就不用),其他的需要传参的再另写不管是类里边的属性还是
方法,在类里边调用的时候都要使用self.属性名/方法名的方式(self就相当于实例
对象自己,即相当于实例对象调用方法)
"""
# 查询所有商品
self.show_all_goods()
elif usc == "2":
# 查询商品种类
self.show_goods_cates()
elif usc == "3":
# 查询品牌分类
self.show_goods_brands()
else:
print("您的输入有误,请重新输入:")
def main():
"""用来完成主体的控制,所以mian函数越简单越好,想尽一切办法让main函数尽可能的简单,这就是封装"""
# 1.创建一个京东对象
jd = JD()
# 调用这个对象的run方法,让其执行
jd.run()
if __name__ == '__main__':
main()
05_添加一个商品分类
from pymysql import connect
class JD(object):
"""类名使用大驼峰隔开,函数/变量名使用下划线隔开"""
"""
好好体会这样(面向对象)写的优点:能封装的全都封装了,将来调用者调用的时候很简单,
实现的过程很复杂
将来去嵌套调用方法这个优点也很好:如果将这些基本的方法放到一个基本的基类里边去,
接下来通过类的三大特性之一-继承,接下来可以重新写一些新的方法,重写就得以实现
(怎么理解:一位方法分的很细,重写的时候不会影响其他方法的实现)
"""
def __init__(self):
"""下边的代码目的是:一创建对象就连接"""
"""为了在其他方法中可以够到(使用)conn/cs1,使用self.使其变为实例属性"""
self.conn = connect(host='localhost',port=3306,database='jing_dong',user='root',password='mysql',charset='utf8')
# 获得Cursor对象
self.cs1 = self.conn.cursor()
def __del__(self):
"""关闭cursor对象"""
"""创建一个对象,使用类名可以创建一个对象,收回一个对象一定会销毁,要么使用
__del__(仅销毁对象可不写,若有其他的需要随着对象关闭而关闭的就可以使用这个
方法)这个方法删除,要么python解释器一定会自己把对象删除掉,所以方法__del__
在最后不用调用一定会执行
"""
self.cs1.close()
self.conn.close()
def execute_sql(self,sql):
self.cs1.execute(sql)
information = self.cs1.fetchall()
for temp in information:
print(temp)
def show_all_goods(self):
"""展示所有商品"""
sql = "select * from goods;"
self.execute_sql(sql)
# 要执行sql语句就要用execute(),返回行数,要输出需要调用fetch
def show_goods_cates(self):
"""展示所有商品种类"""
sql = "select name from goods_cates;"
self.execute_sql(sql)
def show_goods_brands(self):
"""展示所有商品品牌"""
sql = "select name from goods_brands"
self.execute_sql(sql)
# 使用实例对象可以调用任何方法,类对象只能调用类方法(self就相当于实例对象自己在调用方法)
def add_goods_cates(self):
"""添加一个商品分类"""
item_name = input("输入新商品分类的名称:")
sql = """insert into goods_cates(name) values("%s")""" % item_name
self.cs1.execute(sql)
self.conn.commit()
@staticmethod
def print_menu():
"""显示菜单是一个整体,放在run方法中显得run方法太长了,拿出来单独定义一个方法"""
"""由于只有一个方法中需要用到类对象或者实例对象时才需要写self,这个方法不需要
实例对象也不需要类对象,只需打印即可,为静态方法,标注:@staticmethod"""
"""这个方法要有返回值"""
print("-----京东商城-----")
print("1.所有的商品")
print("2.所有的商品种类")
print("3.所有的商品品牌")
print("4.添加一个商品分类")
return input("请输入所需的产品功能:")
def run(self):
"""实例方法,一定含有self"""
while True:
usc = self.print_menu()
if usc == "1":
"""
写"1"是因为input()输入的都是字符串,之所以不使用int对input进行强制类
型转换,是因为转换之后用户输成字母程序会出错
"""
"""
在这里是调用一个方法好呢,还是调用一个函数好呢?要是调用函数的话,直接在类的
外部定义一个函数,使用函数名调用,但是,既然说main函数是用来启动整个函数的
话,那么使用的时候能封装到一个类里边尽量封装到一个类里边,不要再节外生枝再
定义一个函数了.封装到一个类里边的时候要注意,每个需要使用类对象或者实例对象
的方法里边一定含有一个参数self(只有一个方法中需要用到类对象或者实例对象时
才需要写self,静态方法就不用),其他的需要传参的再另写不管是类里边的属性还是
方法,在类里边调用的时候都要使用self.属性名/方法名的方式(self就相当于实例
对象自己,即相当于实例对象调用方法)
"""
# 查询所有商品
self.show_all_goods()
elif usc == "2":
# 查询商品种类
self.show_goods_cates()
elif usc == "3":
# 查询品牌分类
self.show_goods_brands()
elif usc == "4":
# 添加加商品分类
self.add_goods_cates()
else:
print("您的输入有误,请重新输入:")
def main():
"""用来完成主体的控制,所以mian函数越简单越好,想尽一切办法让main函数尽可能的简单,这就是封装"""
# 1.创建一个京东对象
jd = JD()
# 调用这个对象的run方法,让其执行
jd.run()
if __name__ == '__main__':
main()
06_SQL注入
from pymysql import connect
class JD(object):
"""类名使用大驼峰隔开,函数/变量名使用下划线隔开"""
"""
好好体会这样(面向对象)写的优点:能封装的全都封装了,将来调用者调用的时候很简单,
实现的过程很复杂
将来去嵌套调用方法这个优点也很好:如果将这些基本的方法放到一个基本的基类里边去,
接下来通过类的三大特性之一-继承,接下来可以重新写一些新的方法,重写就得以实现
(怎么理解:一位方法分的很细,重写的时候不会影响其他方法的实现)
"""
def __init__(self):
"""下边的代码目的是:一创建对象就连接"""
"""为了在其他方法中可以够到(使用)conn/cs1,使用self.使其变为实例属性"""
self.conn = connect(host='localhost',port=3306,database='jing_dong',user='root',password='mysql',charset='utf8')
# 获得Cursor对象
self.cs1 = self.conn.cursor()
def __del__(self):
"""关闭cursor对象"""
"""创建一个对象,使用类名可以创建一个对象,收回一个对象一定会销毁,要么使用
__del__(仅销毁对象可不写,若有其他的需要随着对象关闭而关闭的就可以使用这个
方法)这个方法删除,要么python解释器一定会自己把对象删除掉,所以方法__del__
在最后不用调用一定会执行
"""
self.cs1.close()
self.conn.close()
def execute_sql(self,sql):
self.cs1.execute(sql)
information = self.cs1.fetchall()
for temp in information:
print(temp)
def show_all_goods(self):
"""展示所有商品"""
sql = "select * from goods;"
self.execute_sql(sql)
# 要执行sql语句就要用execute(),返回行数,要输出需要调用fetch
def show_goods_cates(self):
"""展示所有商品种类"""
sql = "select name from goods_cates;"
self.execute_sql(sql)
def show_goods_brands(self):
"""展示所有商品品牌"""
sql = "select name from goods_brands"
self.execute_sql(sql)
# 使用实例对象可以调用任何方法,类对象只能调用类方法(self就相当于实例对象自己在调用方法)
def add_goods_cates(self):
"""添加一个商品分类"""
item_name = input("输入新商品分类的名称:")
sql = """insert into goods_cates(name) values("%s")""" % item_name
self.cs1.execute(sql)
self.conn.commit()
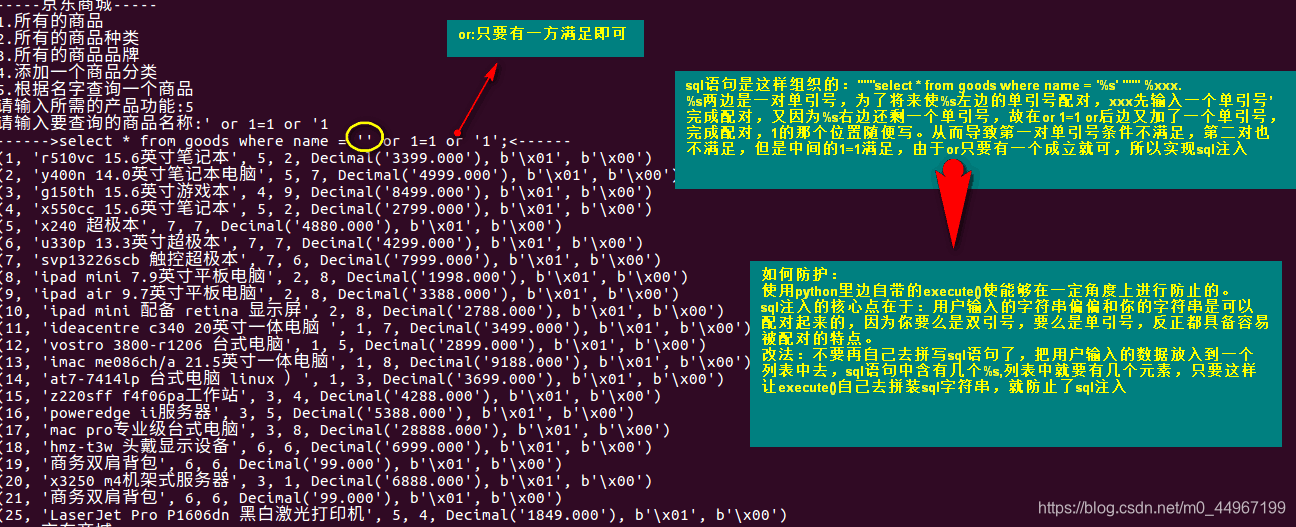
def find_goods_by_name(self):
"""根据名字查询一个商品"""
goods_name = input("请输入要查询的商品名称:")
sql = "select * from goods where name = '%s';" % goods_name
# 调试一下
print("------>%s<------" % sql)
# %s 将来会拿着sql里边的数据进行替换,两边箭头之间的一定是sql
# 不要只打%s万一有空格就看不出来了
self.execute_sql(sql)
@staticmethod
def print_menu():
"""显示菜单是一个整体,放在run方法中显得run方法太长了,拿出来单独定义一个方法"""
"""由于只有一个方法中需要用到类对象或者实例对象时才需要写self,这个方法不需要
实例对象也不需要类对象,只需打印即可,为静态方法,标注:@staticmethod"""
"""这个方法要有返回值"""
print("-----京东商城-----")
print("1.所有的商品")
print("2.所有的商品种类")
print("3.所有的商品品牌")
print("4.添加一个商品分类")
print("5.根据名字查询一个商品")
return input("请输入所需的产品功能:")
def run(self):
"""实例方法,一定含有self"""
while True:
usc = self.print_menu()
if usc == "1":
"""
写"1"是因为input()输入的都是字符串,之所以不使用int对input进行强制类
型转换,是因为转换之后用户输成字母程序会出错
"""
"""
在这里是调用一个方法好呢,还是调用一个函数好呢?要是调用函数的话,直接在类的
外部定义一个函数,使用函数名调用,但是,既然说main函数是用来启动整个函数的
话,那么使用的时候能封装到一个类里边尽量封装到一个类里边,不要再节外生枝再
定义一个函数了.封装到一个类里边的时候要注意,每个需要使用类对象或者实例对象
的方法里边一定含有一个参数self(只有一个方法中需要用到类对象或者实例对象时
才需要写self,静态方法就不用),其他的需要传参的再另写不管是类里边的属性还是
方法,在类里边调用的时候都要使用self.属性名/方法名的方式(self就相当于实例
对象自己,即相当于实例对象调用方法)
"""
# 查询所有商品
self.show_all_goods()
elif usc == "2":
# 查询商品种类
self.show_goods_cates()
elif usc == "3":
# 查询品牌分类
self.show_goods_brands()
elif usc == "4":
# 添加加商品分类
self.add_goods_cates()
elif usc == "5":
"""根据名字查询商品"""
self.find_goods_by_name() # 起名时,宁愿长也要追求可读性
else:
print("您的输入有误,请重新输入:")
def main():
"""用来完成主体的控制,所以mian函数越简单越好,想尽一切办法让main函数尽可能的简单,这就是封装"""
# 1.创建一个京东对象
jd = JD()
# 调用这个对象的run方法,让其执行
jd.run()
if __name__ == '__main__':
main()
07_SQL注入自己写
from pymysql import connect
class JD(object):
"""类名使用大驼峰隔开,函数/变量名使用下划线隔开"""
"""
好好体会这样(面向对象)写的优点:能封装的全都封装了,将来调用者调用的时候很简单,
实现的过程很复杂
将来去嵌套调用方法这个优点也很好:如果将这些基本的方法放到一个基本的基类里边去,
接下来通过类的三大特性之一-继承,接下来可以重新写一些新的方法,重写就得以实现
(怎么理解:一位方法分的很细,重写的时候不会影响其他方法的实现)
"""
def __init__(self):
"""下边的代码目的是:一创建对象就连接"""
"""为了在其他方法中可以够到(使用)conn/cs1,使用self.使其变为实例属性"""
self.conn = connect(host='localhost',port=3306,database='jing_dong',user='root',password='mysql',charset='utf8')
# 获得Cursor对象
self.cs1 = self.conn.cursor()
def __del__(self):
"""关闭cursor对象"""
"""创建一个对象,使用类名可以创建一个对象,收回一个对象一定会销毁,要么使用
__del__(仅销毁对象可不写,若有其他的需要随着对象关闭而关闭的就可以使用这个
方法)这个方法删除,要么python解释器一定会自己把对象删除掉,所以方法__del__
在最后不用调用一定会执行
"""
self.cs1.close()
self.conn.close()
def execute_sql(self,sql):
self.cs1.execute(sql)
information = self.cs1.fetchall()
for temp in information:
print(temp)
def show_all_goods(self):
"""展示所有商品"""
sql = "select * from goods;"
self.execute_sql(sql)
# 要执行sql语句就要用execute(),返回行数,要输出需要调用fetch
def show_goods_cates(self):
"""展示所有商品种类"""
sql = "select name from goods_cates;"
self.execute_sql(sql)
def show_goods_brands(self):
"""展示所有商品品牌"""
sql = "select name from goods_brands"
self.execute_sql(sql)
# 使用实例对象可以调用任何方法,类对象只能调用类方法(self就相当于实例对象自己在调用方法)
def add_goods_cates(self):
"""添加一个商品分类"""
item_name = input("输入新商品分类的名称:")
sql = """insert into goods_cates(name) values("%s")""" % item_name
self.cs1.execute(sql)
self.conn.commit()
def find_goods_by_name(self):
"""根据名字查询一个商品"""
"""个人认为这个方法可以很好的防止sql注入"""
goods_name = input("请输入要查询的商品名称:")
self.cs1.execute("select * from goods;")
information = self.cs1.fetchall()
for temp in information:
if goods_name == temp[1]:
print(temp)
@staticmethod
def print_menu():
"""显示菜单是一个整体,放在run方法中显得run方法太长了,拿出来单独定义一个方法"""
"""由于只有一个方法中需要用到类对象或者实例对象时才需要写self,这个方法不需要
实例对象也不需要类对象,只需打印即可,为静态方法,标注:@staticmethod"""
"""这个方法要有返回值"""
print("-----京东商城-----")
print("1.所有的商品")
print("2.所有的商品种类")
print("3.所有的商品品牌")
print("4.添加一个商品分类")
print("5.根据名字查询一个商品")
return input("请输入所需的产品功能:")
def run(self):
"""实例方法,一定含有self"""
while True:
usc = self.print_menu()
if usc == "1":
"""
写"1"是因为input()输入的都是字符串,之所以不使用int对input进行强制类
型转换,是因为转换之后用户输成字母程序会出错
"""
"""
在这里是调用一个方法好呢,还是调用一个函数好呢?要是调用函数的话,直接在类的
外部定义一个函数,使用函数名调用,但是,既然说main函数是用来启动整个函数的
话,那么使用的时候能封装到一个类里边尽量封装到一个类里边,不要再节外生枝再
定义一个函数了.封装到一个类里边的时候要注意,每个需要使用类对象或者实例对象
的方法里边一定含有一个参数self(只有一个方法中需要用到类对象或者实例对象时
才需要写self,静态方法就不用),其他的需要传参的再另写不管是类里边的属性还是
方法,在类里边调用的时候都要使用self.属性名/方法名的方式(self就相当于实例
对象自己,即相当于实例对象调用方法)
"""
# 查询所有商品
self.show_all_goods()
elif usc == "2":
# 查询商品种类
self.show_goods_cates()
elif usc == "3":
# 查询品牌分类
self.show_goods_brands()
elif usc == "4":
# 添加加商品分类
self.add_goods_cates()
elif usc == "5":
"""根据名字查询商品"""
self.find_goods_by_name() # 起名时,宁愿长也要追求可读性
else:
print("您的输入有误,请重新输入:")
def main():
"""用来完成主体的控制,所以mian函数越简单越好,想尽一切办法让main函数尽可能的简单,这就是封装"""
# 1.创建一个京东对象
jd = JD()
# 调用这个对象的run方法,让其执行
jd.run()
if __name__ == '__main__':
main()
08_SQL注入解决
from pymysql import connect
class JD(object):
"""类名使用大驼峰隔开,函数/变量名使用下划线隔开"""
"""
好好体会这样(面向对象)写的优点:能封装的全都封装了,将来调用者调用的时候很简单,
实现的过程很复杂
将来去嵌套调用方法这个优点也很好:如果将这些基本的方法放到一个基本的基类里边去,
接下来通过类的三大特性之一-继承,接下来可以重新写一些新的方法,重写就得以实现
(怎么理解:一位方法分的很细,重写的时候不会影响其他方法的实现)
"""
def __init__(self):
"""下边的代码目的是:一创建对象就连接"""
"""为了在其他方法中可以够到(使用)conn/cs1,使用self.使其变为实例属性"""
self.conn = connect(host='localhost',port=3306,database='jing_dong',user='root',password='mysql',charset='utf8')
# 获得Cursor对象
self.cs1 = self.conn.cursor()
def __del__(self):
"""关闭cursor对象"""
"""创建一个对象,使用类名可以创建一个对象,收回一个对象一定会销毁,要么使用
__del__(仅销毁对象可不写,若有其他的需要随着对象关闭而关闭的就可以使用这个
方法)这个方法删除,要么python解释器一定会自己把对象删除掉,所以方法__del__
在最后不用调用一定会执行
"""
self.cs1.close()
self.conn.close()
def execute_sql(self,sql):
self.cs1.execute(sql)
information = self.cs1.fetchall()
for temp in information:
print(temp)
def show_all_goods(self):
"""展示所有商品"""
sql = "select * from goods;"
self.execute_sql(sql)
# 要执行sql语句就要用execute(),返回行数,要输出需要调用fetch
def show_goods_cates(self):
"""展示所有商品种类"""
sql = "select name from goods_cates;"
self.execute_sql(sql)
def show_goods_brands(self):
"""展示所有商品品牌"""
sql = "select name from goods_brands"
self.execute_sql(sql)
# 使用实例对象可以调用任何方法,类对象只能调用类方法(self就相当于实例对象自己在调用方法)
def add_goods_cates(self):
"""添加一个商品分类"""
item_name = input("输入新商品分类的名称:")
sql = """insert into goods_cates(name) values("%s")""" % item_name
self.cs1.execute(sql)
self.conn.commit()
def find_goods_by_name(self):
"""根据名字查询一个商品"""
goods_name = input("请输入要查询的商品名称:")
# sql = "select * from goods where name = '%s';" % goods_name
# 调试一下
# print("------>%s<------" % sql)
# %s 将来会拿着sql里边的数据进行替换,两边箭头之间的一定是sql
# 不要只打%s万一有空格就看不出来了
#self.execute_sql(sql)
sql = "select * from goods where name = %s;"
self.cs1.execute(sql,[goods_name])
# execute()自动将列表内第一个元素填到%s里边
print(self.cs1.fetchall())
@staticmethod
def print_menu():
"""显示菜单是一个整体,放在run方法中显得run方法太长了,拿出来单独定义一个方法"""
"""由于只有一个方法中需要用到类对象或者实例对象时才需要写self,这个方法不需要
实例对象也不需要类对象,只需打印即可,为静态方法,标注:@staticmethod"""
"""这个方法要有返回值"""
print("-----京东商城-----")
print("1.所有的商品")
print("2.所有的商品种类")
print("3.所有的商品品牌")
print("4.添加一个商品分类")
print("5.根据名字查询一个商品")
return input("请输入所需的产品功能:")
def run(self):
"""实例方法,一定含有self"""
while True:
usc = self.print_menu()
if usc == "1":
"""
写"1"是因为input()输入的都是字符串,之所以不使用int对input进行强制类
型转换,是因为转换之后用户输成字母程序会出错
"""
"""
在这里是调用一个方法好呢,还是调用一个函数好呢?要是调用函数的话,直接在类的
外部定义一个函数,使用函数名调用,但是,既然说main函数是用来启动整个函数的
话,那么使用的时候能封装到一个类里边尽量封装到一个类里边,不要再节外生枝再
定义一个函数了.封装到一个类里边的时候要注意,每个需要使用类对象或者实例对象
的方法里边一定含有一个参数self(只有一个方法中需要用到类对象或者实例对象时
才需要写self,静态方法就不用),其他的需要传参的再另写不管是类里边的属性还是
方法,在类里边调用的时候都要使用self.属性名/方法名的方式(self就相当于实例
对象自己,即相当于实例对象调用方法)
"""
# 查询所有商品
self.show_all_goods()
elif usc == "2":
# 查询商品种类
self.show_goods_cates()
elif usc == "3":
# 查询品牌分类
self.show_goods_brands()
elif usc == "4":
# 添加加商品分类
self.add_goods_cates()
elif usc == "5":
"""根据名字查询商品"""
self.find_goods_by_name() # 起名时,宁愿长也要追求可读性
else:
print("您的输入有误,请重新输入:")
def main():
"""用来完成主体的控制,所以mian函数越简单越好,想尽一切办法让main函数尽可能的简单,这就是封装"""
# 1.创建一个京东对象
jd = JD()
# 调用这个对象的run方法,让其执行
jd.run()
if __name__ == '__main__':
main()
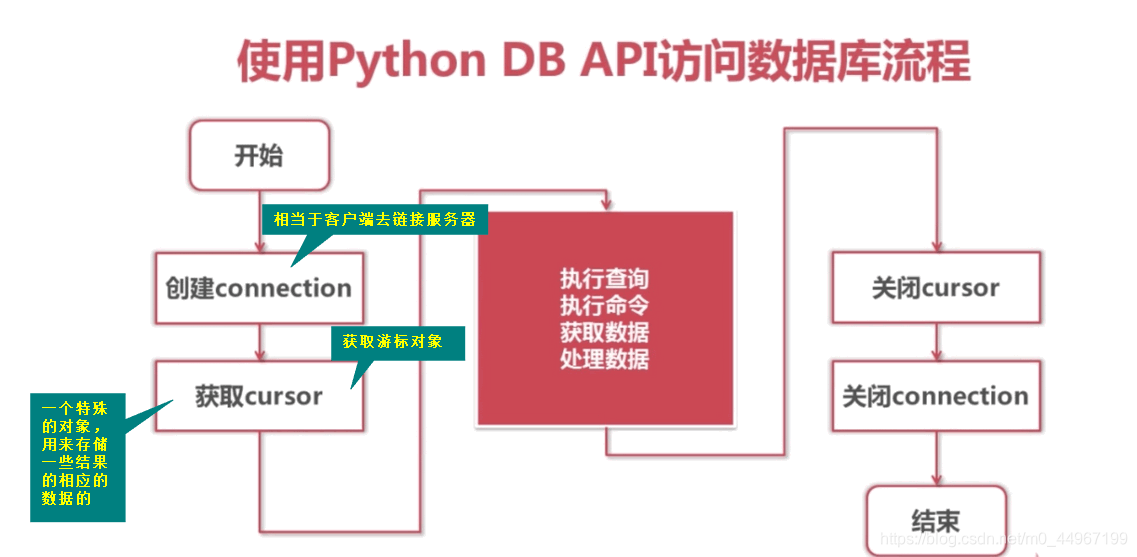
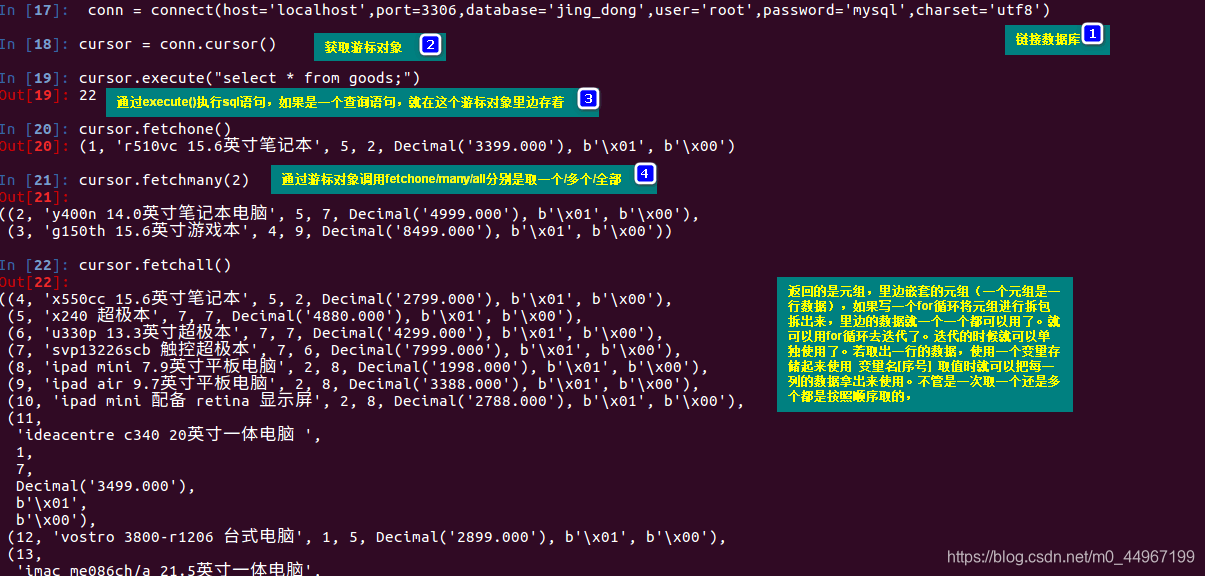
09_python中操作MQYSQL的步骤
03_MYSQL高级
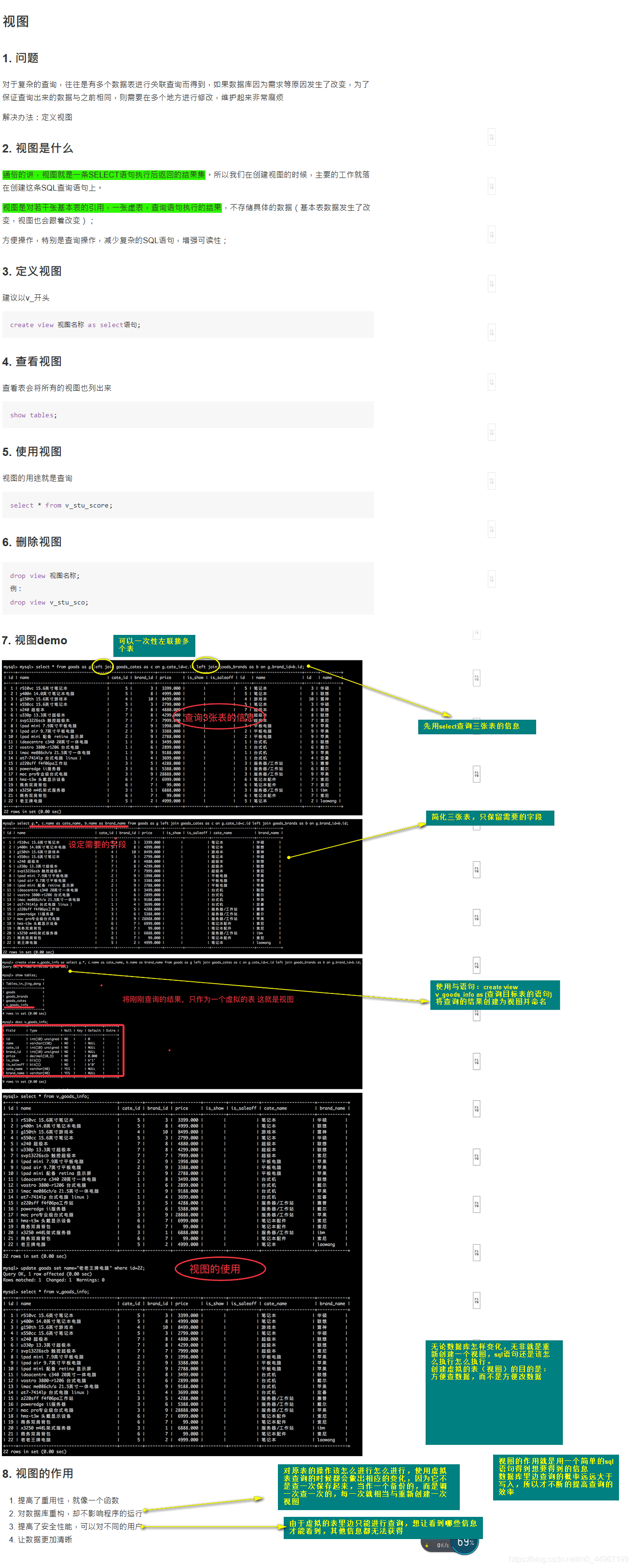
01_视图

02_事务

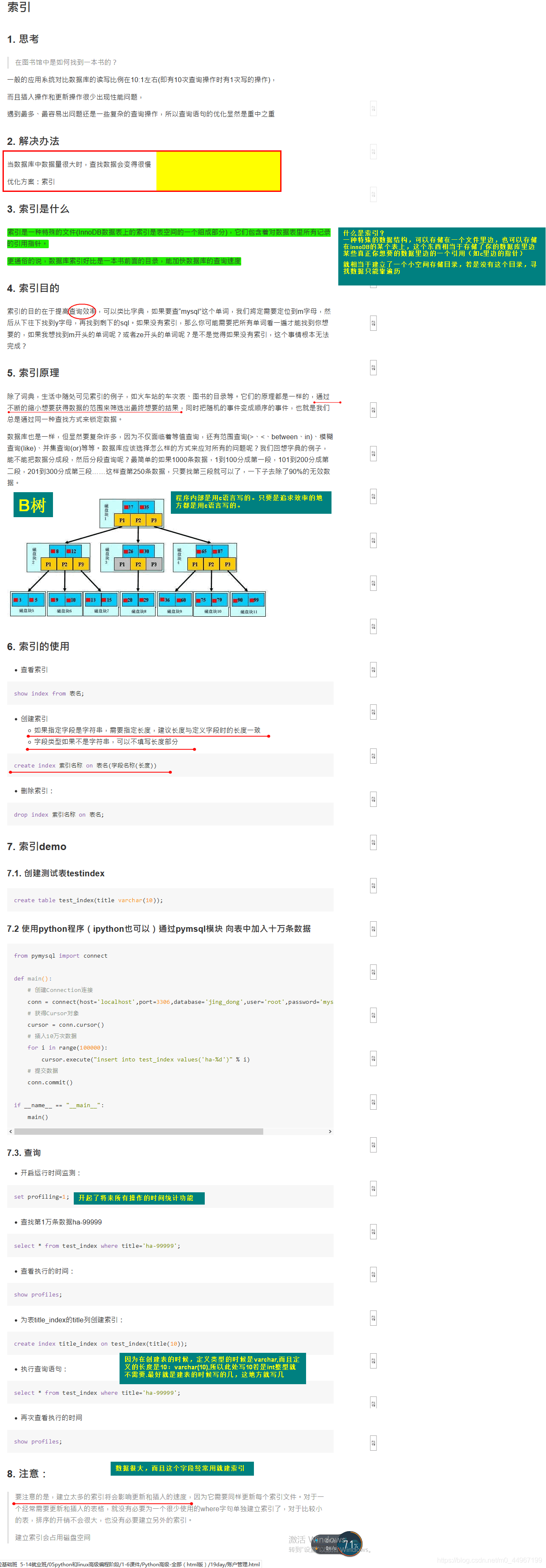
03_索引
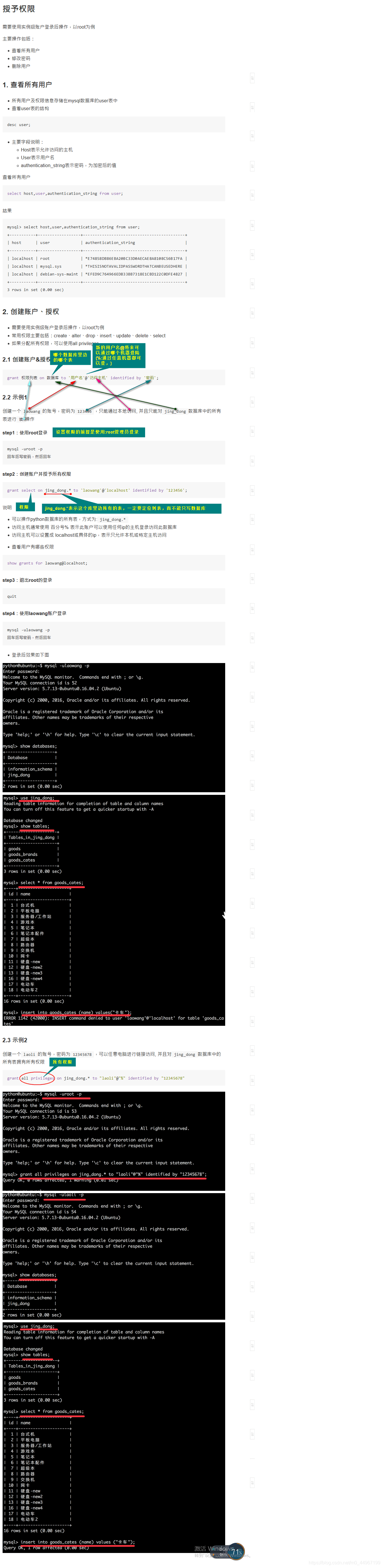
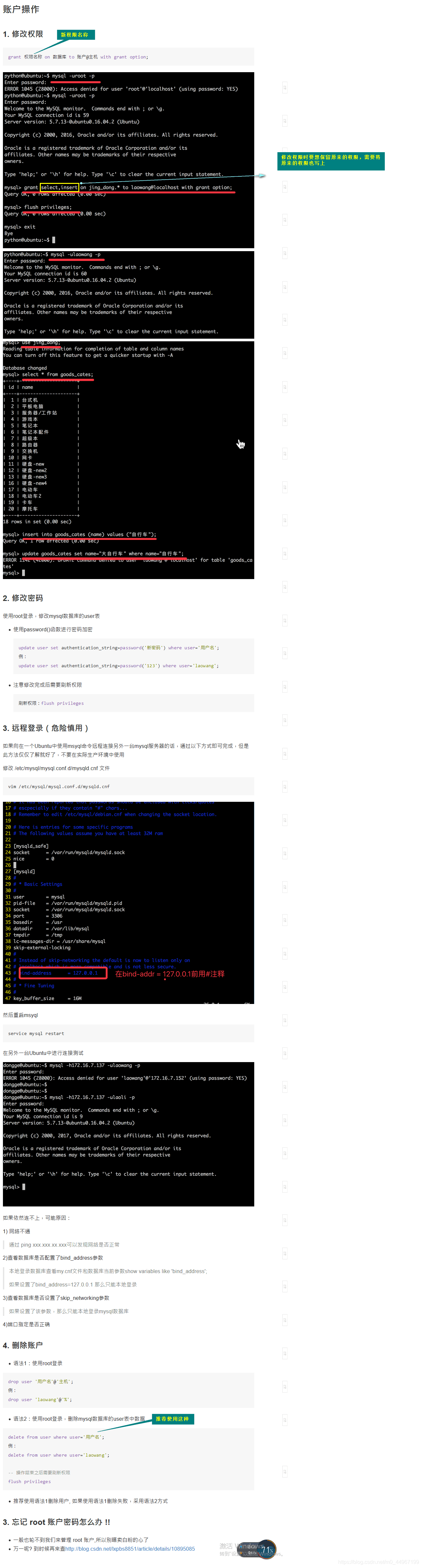
04_账户管理
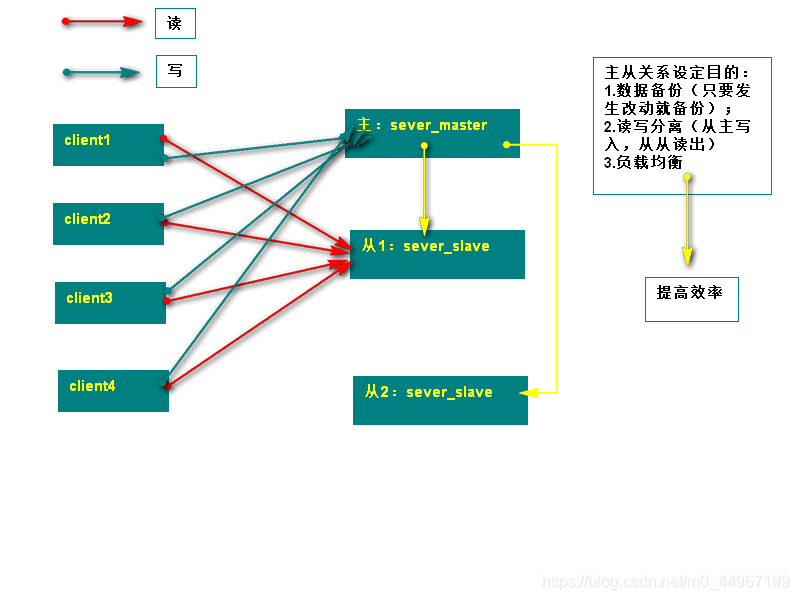
05_MYSQL主从

04-未归类
01_数据库_sql语句规范1

02_数据库相关信息
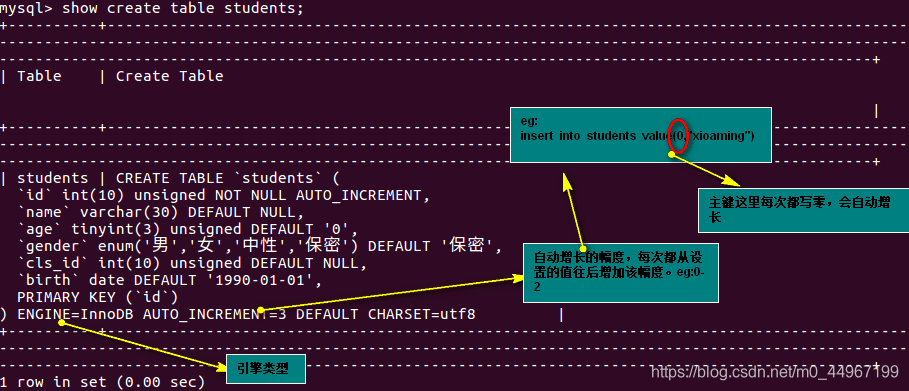
03_创建数据库数据表流程
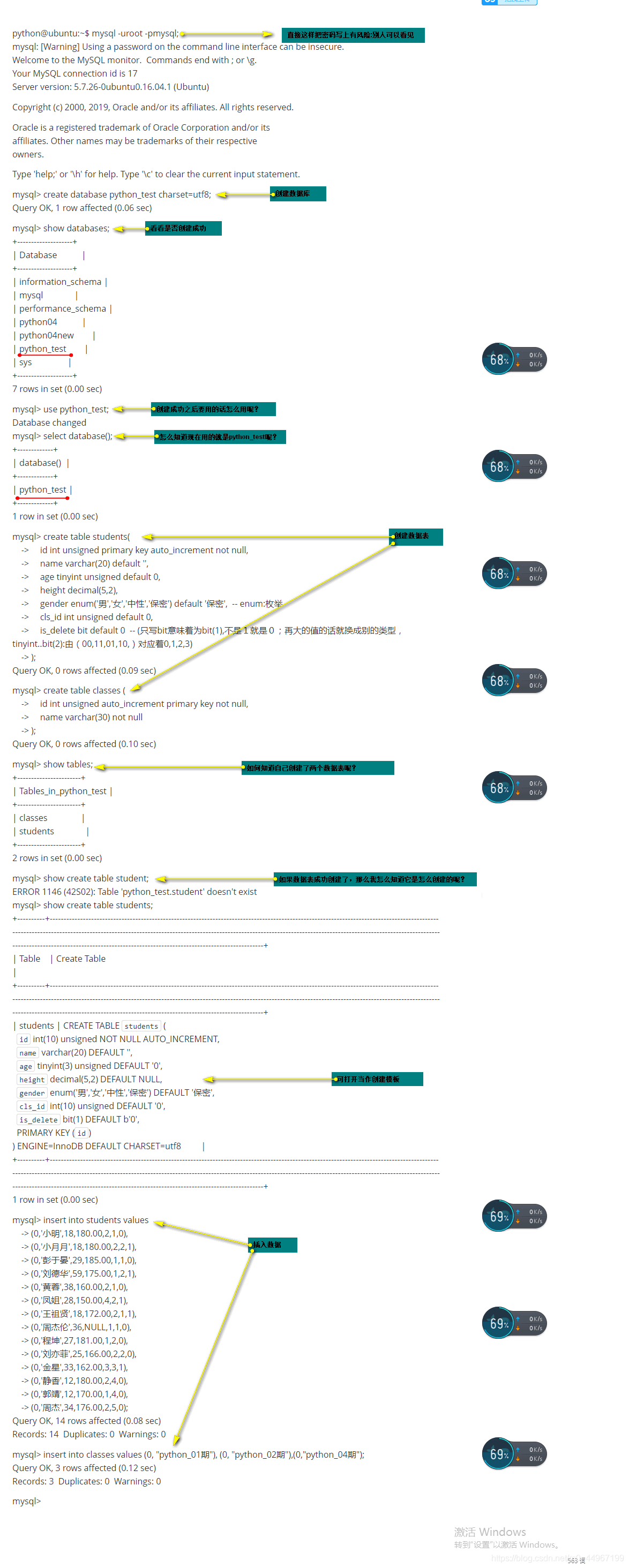
04_将一个sql文件(装有大量数据)直接导入mysql的表里边的步骤
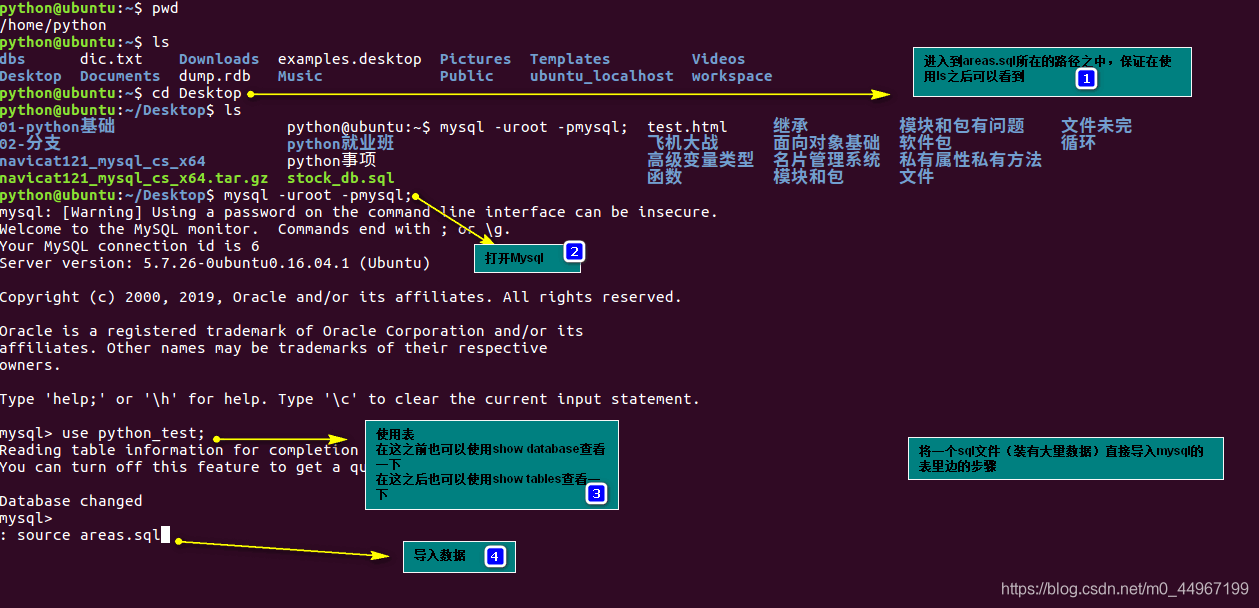
05_关系型数据库的分析与设计

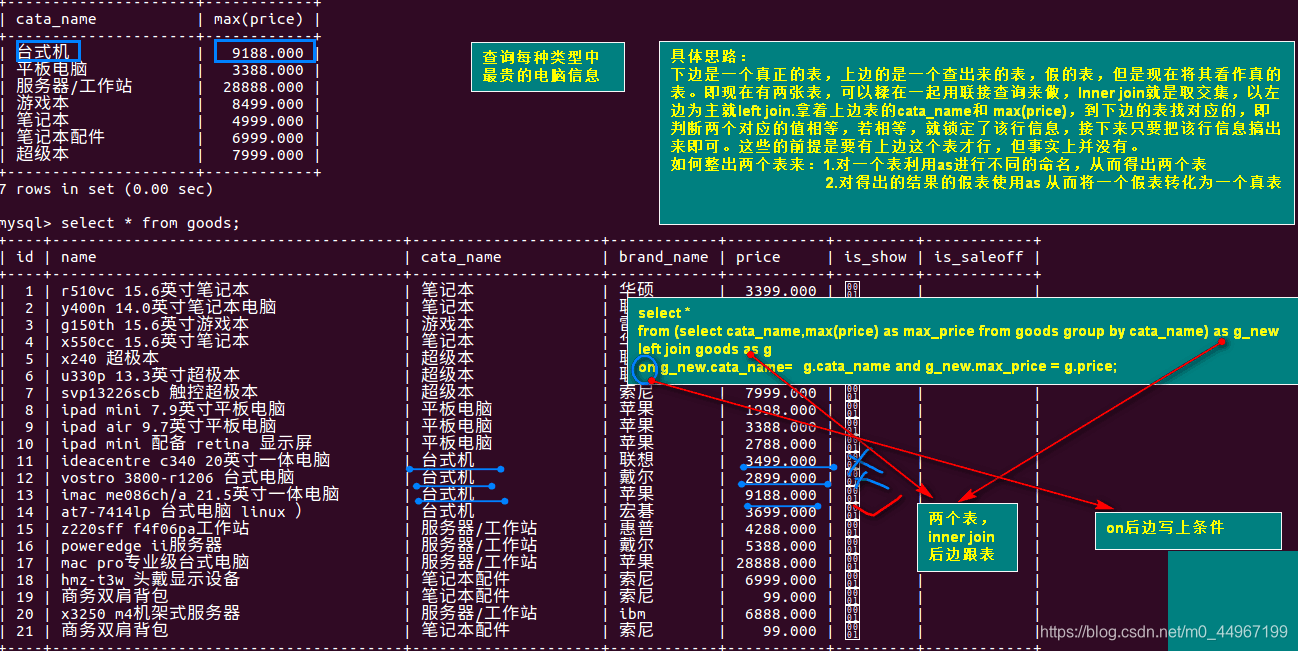
06_查询每种类型中最贵的电脑信息-一个模板
07_数据库设计之拆表思想

08_数据库增删改