一、什么是算法
- 算法,问题之解法也
- 广义而言,写的每个程序都是一个算法,其中的每个函数也都是一个算法
- 下面的一些文章我们将探讨极具复用价值的70余个STL算法,包括排序(sorting)、查找(searching)、排列组合(permutation)、以及用于数据移动、赋值、删除、比较、组合、运算等的算法
- 特定的算法往往搭配特定的数据结构,例如二叉搜索树(binary search tree)和红黑树(RB-tree)、哈希表(hash table)等
二、算法分析与算法复杂度
- 算法分析:分析算法所耗费的资源,包括空间和时间
- 算法的复杂度,可以作为我们衡量算法的效率的标准
- 一般而言,算法的执行时间和其所要处理的数据量有关,两者之间存在某种函数关系,可能是一次(线型,linear)、一次(quadratic)、三次(cubic)或对数(logarithm)关系
- 但数据量很小时,其中的每一项都可能对结果带来相当程序的影响
- 但是数据量很大时,只有最高次的项目才具有主导地位
算法复杂度表示方法

- 其他方法还有Big-Omega、Big-Theta、Little-Oh等
- 其中大O记法使用最广泛,但是不适用来标记小数据量的情况
下面是三个复杂度各异的问题
- ①最小元素问题:求取array中的最小元素
- 该问题的解法必须两两元素对比,因此N各元素需要N次对比,所以数据量与执行时间呈线性关系。该问题的复杂度为O(N)
- ②最短距离问题:求取X-Y平面上的N个点中,距离最近的两个点
- 该问题所需要计算的元素对共有N/(N-Z)/2!,所以大数据量和执行时间呈二次关系。该问题的复杂度为O(
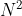 )
)
- ③三点共线问题:决定X-Y平面上的N个点中,是否有任何三点共线
- 该问题要计算的元素对共有N(N-1)(N-2)/3!,所以大数据量和执行时间呈三次关系。该问题的复杂度为O(
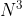 )
)
下面三个问题出现一种新的复杂度形式
- ④需要多少bits才能表现出N个连续整数
- 该问题中,B个bots可表现出
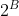 个不同的整数,因此想要表现出N个连续整数,需要满足方程式>=N,即B>=
个不同的整数,因此想要表现出N个连续整数,需要满足方程式>=N,即B>=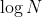
- ⑤从X=1开始,每次将X扩充两倍,需要多少次扩充才能使X>=N
- 该问题成为“持续加倍问题”,必须满足方程式
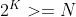 ,此问题与上面的问题相同,因此解答相同
,此问题与上面的问题相同,因此解答相同
- ⑥从X=N开始,每次将X缩减一半,需要多少次缩减才能使X<=1
- 该问题成为“持续减半问题”,与上面的问题相同,只不过方向相反
- 如果一个算法,花费固定时间(常数时间,O(1))将问题的规模降低某个固定比例(通常是1/2),基于上述问题⑥的解答,我们便说此算法的复杂度是O()
- 注意:问题规模的降低比例如何,并不会带来影响,因为他会反应在对数的底上,而底对于BIg-Oh标记法是没有影响的(任何的算法书上应该都会有证明)
三、STL算法总览
- 下图显示了STL算法(以及一些非标准的SGI STL算法)的名称、用途、文件分布等等
- 凡是不在STL标准之中的,都以*标记




四、质变算法、非质变算法
质变算法(mutating algorithms)——会改变操作对象的值
- 所有的STL算法都作用在由迭代器[first,last)所标示出来的区间上
- 质变算法在运算过程中会更改区间内的元素。但是不一定改变传入的对象,可能是复制一份再改变(见下面“五”中的介绍)
- 例如拷贝(copy)、交换(swap)、替换(replace)、填写(file)、删除(remove)、排列组合(permutation)、分割(partition)、随机重排(random shuffling)、排序(sort)等算法
- 所以如果你把这些算法运用在一个常数区间上是错误的。例如:
#include <vector>
#include <algorithm>
using namespace std;
int main()
{
int ia[] = { 22,30,30,17,33,40,19,23,22,12,20 };
vector<int> iv(ia, ia + sizeof(ia) / sizeof(int));
vector<int>::const_iterator citer1 = iv.begin();
vector<int>::const_iterator citer2 = iv.end();
sort(citer1, citer2);
return 0;
}
非质变算法(nonmutating algorithms)——不会改变操作对象的值
- 所有的STL算法都作用在由迭代器[first,last)所标示出来的区间上
- 质变算法在运算过程中不会更改区间内的元素
- 例如查找(find)、匹配(search)、计数(count)、遍历(for_each)、比较(equal,mismatch)、寻找极值(max,min)等算法
- 例如你在for_each算法身上应用一个会改变元素内容的仿函数,那么也可以让非质变算法变为质变算法
#include <vector>
#include <algorithm>
using namespace std;
template<class T>
struct plus2
{
void operator()(T& x)const
{
x += 2;
}
};
int main()
{
int ia[] = { 22,30,30,17,33,40,19,23,22,12,20 };
vector<int> iv(ia, ia + sizeof(ia) / sizeof(int));
for_each(iv.begin(), iv.end(), plus2<int>()); //正确
return 0;
}
五、STL算法的一些性质
算法操作的是迭代器的区间
- 算法的前两个参数都是一对迭代器,通常为分别为first和last
- STL习惯采用前闭后开区间。例如[first,last)区间表示包含first至last(但是不含last)。当first==last时,是一个空区间
- 这个[first,last)区间必要条件是,必须能够从first遍历到last。编译器本身无法强求这一点,但是如果你的程序不支持,那么就会造成不可预期的后果
- 在迭代器的文章中我们介绍了,迭代器可以分为5类:
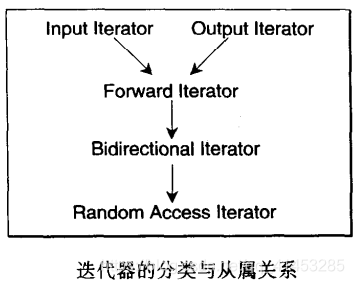
- 最低程度迭代器类型:
- 每种算法都需要其最低程序的迭代器类型。例如find()最低要求需要一个Input Iterator,这是其最低的要求
- 但是其也可以接受更高类型的迭代器,例如Forward Iterator,Bidirectiona Iterator或RandomAccess Iterator(因为这3个迭代器也都是Input Iterator的一种)
- 但是你绝不能将Output Interator传递给find()
有些算法不止一个版本
- STL有些算法不只支持一个版本。这类算法的某个版本采用缺省运算行为,其他版本提供额外的参数,接受外界传入一个仿函数
- 例如unique()缺省下使用equality操作符来比较两个相邻元素,但是用户也可以自己定义equality操作符然后传递给unique()
- 有些算法将两个不同版本的函数不同命名,附从的那个以_if结尾
- 例如find()的另一个版本为fond_if()
- 例如replace()的的另一个版本为replace_if()
质变算法通常提供两个版本
- 质变算法通常提供两个版本:
- 一个是in-place(就地进行)版本,就地改变其操作对象
- 另一个是copy(另地进行)版本,将操作对象的内容复制一份副本,然后在副本上修改并返回该副本。copy版本的总是以_copy的结尾
- 例如replace()是in-place版本的,但是replace_copy()是copy版本的
- 例如sort()就没有两个版本,因为我们希望这类“无copy”版本的质变算法实施于某一段区间元素的副本身上
头文件
- 所有的数值算法等都实现于<stl_numeric.h>中(这是个内部头文件)。应用层使用应该包含<numeric>
- 其他STL算法都实现于<stl_algo.h>和<stl_algobase.h>中(也是内部头文件)。应用层使用应该包含<alforithm>
六、算法的泛化过程
- 算法的泛化过程就是将算法独立于其所处理的数据结构之外,不受数据结构的约束。使一个算法适用于所有的数据结构(不论传入算的是vector、list还是deque等)
- 关键在于,只要把操作对象的类型加以抽象化,把操作对象的标示法和区间目标的移动行为抽象化,整个算法就可以在一个抽象层面上工作了。整个过程称为算法的泛型化,简称泛化
演示案例(一步一步的进行泛化)
- 第一步:现在我们需要设计一个算法,在数组中查找某一个特定的值,那么我们可能会设计下面的函数:
- 该算法在数组中查找元素,返回一个指针。如果找到就返回这个位置的地址,如果没有找到就返回数组最后一个元素的下一个位置
- 这种算法的缺点:这种算法暴露了容器太多的细节,也太过依赖于容器的类型
int* find(int* arrayHead, int arraySize, int value)
{
int i=0;
for (; i < arraySize; ++i)
{
if (arrayHead[i] == value)
break;
}
return &(arrayHead[i]);
}
int main()
{
const int arraySize = 7;
int ia[arraySize] = { 0,1,2,3,4,5,6 };
int *end = ia + arraySize;
int* ip = find(ia, arraySize, 4);
if (ip == end)
std::cout << "4 not found" << std::endl;
else
std::cout << "4 found." << *ip << std::endl;
return 0;
}
- 第二步:为了让算法更抽象些,应该让算法接受两个指针作为参数,表示出操作一个区间
- 这个函数在“前闭后开”区间[begin,end)内查找元素,返回值与第一步中的函数相同
- 但是这个算法只能适用于int型的数组,不能适用于其他类型的容器
int* find(int* begin, int* end, int value)
{
while ((begin != end) && (*begin != value))
++begin;
return begin;
}
int main()
{
const int arraySize = 7;
int ia[arraySize] = { 0,1,2,3,4,5,6 };
int *end = ia + arraySize;
int* ip = find(ia, end, 4);
if (ip == end)
std::cout << "4 not found" << std::endl;
else
std::cout << "4 found." << *ip << std::endl;
return 0;
}
- 第三步:我们可以将第二步的算法进行加工,声明为一个模板,使其适用于所有的类型
- 注意:参数3改了,改为了pass-by-reference-to-const
- 这个模板可以适用于任何容器
template<typename T>
T* find(T* begin, T* end, const T& value)
{
while ((begin != end) && (*begin != value))
++begin;
return begin;
}
- 第四步:上面的模板只能使用指针作为区间传入函数,但是STL设计的迭代器就是一种智能指针,迭代器是一种类似指针的对象。因此我们可以将指针改为迭代器然后作为算法的参数和返回值
- 这就是算法最终的泛化版本,在STL中的算法都是这样实现的
template<class Iterator,typename T>
Iterator* find(Iterator* begin, Iterator* end, const T& value)
{
while ((begin != end) && (*begin != value))
++begin;
return begin;
}
