一、线程
什么是线程?
CPU 调度和分派的基本单位,当前线程 CPU 时间片用完后,会让出 CPU 等下次操作系统调度,轮到自己执行的时候再执行。操作系统不会为线程分配内存,但是线程组之间可以共享所属进程的资源,比如文件,数据库,进程的代码段,打开的文件描述符,进程的当前目录,全局变量,静态变量等
线程的作用?
进程中运行的单元,运行的是线程(进程不运行,但是占据资源),如果线程不运行了,进程就没有存在的必要了。多个的线程运行在同一个进程中,可以提高事件的处理效率。例如有做饭、扫地、擦桌子、买菜等多件事,如果一个人做(一个主线程),肯定是按顺序一个一个做,显然很慢,怎么提高效率呢?我们让多个人(多个线程)来做,每个人做不同的事,让几件事可以同时发生,效率就上来了。
- 并发执行:指的是在操作系统上同时执行的进程数大于CPU数量时,进程的执行方式
- 并行执行:指的是在操作系统上同时执行的进程数不大于CPU数量时,进程之间不用抢占CPU的执行方式,即每个进程独占一个CPU
代码讲解
我们都知道如果歌手只是一动不动地唱歌,而没有肢体动作的话,那我们的体验肯定很差,下面这个代码就是歌手先一动不动地唱歌,唱完歌后再进行舞蹈(顺序执行)
1、一个简单的demo
import time
def sing():
"""唱歌3秒"""
for i in range(3):
print("----正在唱歌----%d" % i)
time.sleep(1)
def dance():
"""跳舞3秒"""
for i in range(3):
print("----正在跳舞----%d" % i)
time.sleep(1)
def main():
sing()
dance()
if __name__ == "__main__":
main()

显然,体验很差,唱歌和跳舞没有一起执行,这不是我们想要的。下面我们用多线程实现两个任务一起执行(即两个函数一起执行)
import time
import threading
def sing():
"""唱歌5秒"""
for i in range(5):
print("----正在唱歌----%d" % i)
time.sleep(1)
def dance():
"""跳舞3秒"""
for i in range(3):
print("----正在跳舞----%d" % i)
time.sleep(1)
def main():
t1 = threading.Thread(target=sing) # 此处主线程创建第一个普通对象
t2 = threading.Thread(target=dance) # 此处主线程创建第二个普通对象
t1.start() # 线程产生并开始执行
t2.start()
while True:
num = len(threading.enumerate())
if num == 1:
# 线程队列中只剩主线程时退出
print("当前线程数:{}".format(num))
break
print("当前线程数:{}".format(num))
if __name__ == "__main__":
main()

可以看见,现在唱歌和跳舞是一起进行的。接下来讲解一下代码中的注意点。
- 若创建线程执行的函数运行结束,意味着这个子线程消亡
- 一般情况下,主线程默认等待所有子线程执行完,再结束
- 若主线程提前消亡,则子线程也将消亡
- 调用threading.Thread() 仅仅只是创建一个普通的对象,线程队列threading.enumerate() 中并不会多一个线程,只有调用start后,线程队列中才会加入新的线程
2、类实现多线程
自定义类实现多线程需要继承threading.Thread类,并重写run方法,调用start方法就会自动调用类里面的run方法
import threading
import time
class MyThread(threading.Thread):
# 继承threading.Thread类,并实现run方法
def run(self):
for i in range(3):
time.sleep(1)
msg = "I'm " + self.name + "@" + str(i) # name封装的是当前线程的名字
print(msg)
def main():
t1 = MyThread()
t2 = MyThread()
t1.start() # 自动调用run方法
t2.start() # 自动调用run方法
if __name__ == "__main__":
main()

可以看到线程名字这部分是交替出现的,说明我们通过调用start方法实现了并发执行。嗯?不是说调用start方法会自动调用run方法,那如果我们直接调用run方法会怎么样呢?试试就知道了。
def main():
t1 = MyThread()
t2 = MyThread()
t1.run() # 手动调用run方法
t2.run() # 手动调用run方法

很明显这成了顺序执行,不是并发执行,前面说了只有调用start后,线程队列中才会加入新的线程,直接通过对象调用run方法,线程队列中并没有产生新的线程(始终只有一个主线程),于是就成了普通的顺序执行。现在理解了吗?
3、多线程共享所属进程的部分资源(全局变量为例)
我们让一个线程对全局变量加1,然后再让一个线程获取全局变量的值,若获取的是原值,则不共享资源,若获取的是+1后的值,则共享资源。为保证执行顺序,使用了延时操作。
import threading
import time
num = 100
# 将全局变量+1
def test1():
global num
num += 1
print("-----in test1----num:%s" % num)
# 获取全局变量并输出
def test2():
print("-----in test2----num:%s" % num)
def main():
t1 = threading.Thread(target=test1)
t2 = threading.Thread(target=test2)
t1.start()
time.sleep(1)
t2.start()
time.sleep(1)
print("-----in main----num:%s" % num)
if __name__ == '__main__':
main()
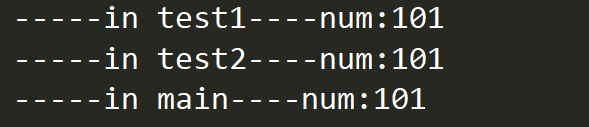
结论很明显,不管是主线程还是子线程都共享所属进程的资源
4、多线程共享资源导致的问题
多线程可以让处理多个事件,效率很高,那有没有什么弊端呢?当然是有的,我们来看看下面的代码
import threading
import time
num = 0
def test1(times):
global num
for i in range(times):
num += 1
def test2(times):
global num
for i in range(times):
num += 1
def main():
t1 = threading.Thread(target=test1, args=(1000000,))
t2 = threading.Thread(target=test2, args=(1000000,))
t1.start()
t2.start()
time.sleep(10)
print("-----in main----num:%s" % num)
if __name__ == '__main__':
main()

嗯?两个线程对同一个全局变量进行加1000000,结果应该是2000000。这不是我们想要的结果,这是因为CPU把num+=1分成了很多步骤,例如
- 获取num的值
- 将获取的值+1
- 把计算后的值存储起来,并让num指向改存储空间
有可能执行过程是这样的:
一开始num=0,当一个线程A获取值0,加1,这时很不巧,时间片用完了,无奈线程A让出CPU,让另一个线程执行。此时线程B第1步获取到的值为0,加1后然后保存,num的值变成1。时间片到了,轮到线程A执行,线程A从第3步开始执行,将计算结果1进行保存,num的值变成1。至此,两个线程都做了加1的操作,而结果等于1。
下面解决这种资源冲突问题。
5、互斥锁解决资源冲突
首先要知道,产生上述的原因是多线程破坏了事件的原子性(一个事件要么不执行,要么执行完)。要想事件保持原子性,我们需要上互斥锁。一个线程在执行某事件时,必须拿到锁,否则就等待,等待其他线程释放锁,成功上锁才可执行对应的事件。上面说num += 1被分成了很多步执行的,我们用上锁操作 acquire() 和解锁操作 release() 将次事件包裹起来,保证事件的所有步骤都能执行
import threading
import time
# 创建互斥锁
mutex = threading.Lock()
num = 0
def test1(times):
global num
for i in range(times):
mutex.acquire() # 上锁,若之前没有上锁,则此时上锁成功,否则阻塞直到锁被解开,才可再次使用mutex锁
num += 1
mutex.release()
def test2(times):
global num
for i in range(times):
mutex.acquire() # 上锁,若之前没有上锁,则此时上锁成功,否则阻塞直到锁被解开
num += 1
mutex.release()
def main():
t1 = threading.Thread(target=test1, args=(1000000,))
t2 = threading.Thread(target=test2, args=(1000000,))
t1.start()
t2.start()
time.sleep(2) # 等待两个子线程执行完
print("-----in main num=", num)
if __name__ == "__main__":
main()
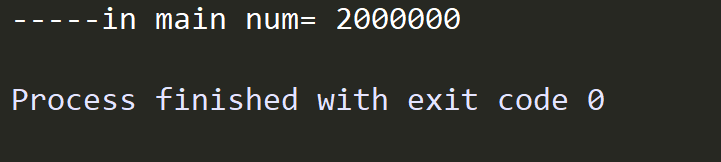
6、上锁导致的问题:死锁
上面我们说到,上锁可以解决共享资源冲突的问题,那上锁又会不会产生新的什么问题呢?我们看下面的代码
import time
import threading
mutex_1 = threading.Lock()
mutex_2 = threading.Lock()
class MyThread1(threading.Thread):
def run(self):
mutex_1.acquire()
print(self.name + "-------mutex_1被占-------")
time.sleep(1)
print(self.name + "-------等待mutex_2-------")
mutex_2.acquire() # 此时mutex_2已经被占用,阻塞直到mutex_2被释放
mutex_1.release()
mutex_2.release()
class MyThread2(threading.Thread):
def run(self):
mutex_2.acquire()
print(self.name + "-------mutex_2被占-------")
time.sleep(1)
print(self.name + "-------等待mutex_1-------")
mutex_1.acquire() # 此时mutex_1已经被占用,阻塞直到mutex_1被释放
mutex_1.release()
mutex_2.release()
def main():
t1 = MyThread1()
t2 = MyThread2()
t1.start()
t2.start()
if __name__ == '__main__':
main()
运行结果:
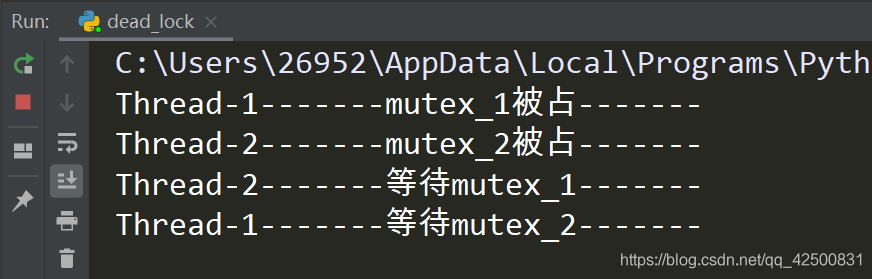
结果表现得很尴尬,程序一直卡着。原因很简单,mutex_1被Thread-1占了,mutex_2被Thread-2占了,而他们为了继续执行程序,都要获取被对方占着的锁,而对方又因等待着上锁,无法释放锁,故一直阻塞。
解决的方法也很简单,设置超时即可。
二、进程
1、什么是进程
- 进程= 执行的程序 + 分配的资源。例如在windows中一个exe文件是一个程序,双击exe后程序执行,操作系统给该程序分配内存空间,CPU,IO等资源后,操作系统上就多了一个进程。
- 进程是资源分配的单位,例如QQ运行起来后就是一个进程,分配的资源有摄像头,光标,扬声器,键盘等资源。QQ多开就是一种多进程
- 进程里的方法区,是用来存放进程中的代码片段的,是线程共享的
- 进程不是一个可执行的实体,是一个占用系统资源的实体,但一个进程至少有一个主线程去执行程序
2、多进程之间不共享资源(全局变量为例)
让进程1对全局变量进行操作,再让进程2对全局变量进行操作,分别获取操作后的结果,并打印id
import multiprocessing
import time
g_num = [1]
def test1(num):
for i in range(num):
g_num.append(2)
print("-----in test1---g_num=", g_num)
print("-----in test1---id(g_num) =", id(g_num))
def test2(num):
for i in range(num):
g_num.append(3)
print("-----in test2---g_num=", g_num)
print("-----in test2---id(g_num) =", id(g_num))
def main():
# 进程实现多任务,耗费资源非常大
p1 = multiprocessing.Process(target=test1, args=(1,))
p2 = multiprocessing.Process(target=test2, args=(1,))
p1.start() # 主进程创建子进程
time.sleep(2)
p2.start()
print("-----in main---g_num=", g_num)
print("-----in main---id(g_num) =", id(g_num))
if __name__ == "__main__":
print("--------id(g_num) =", id(g_num))
main()
运行结果:
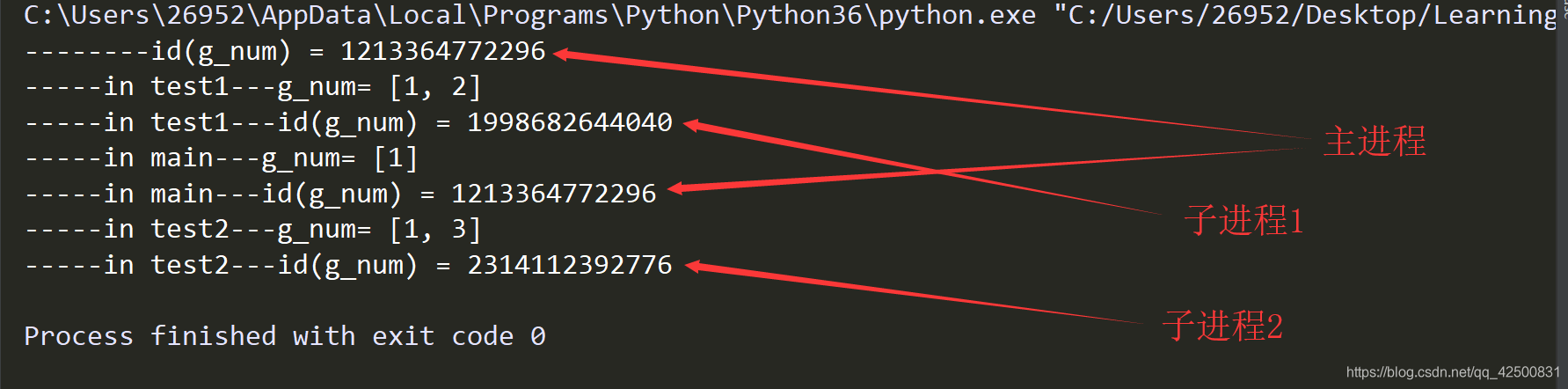
通过打印id我们可以发现,所有子进程和父进程使用的g_num地址都不一样,说明了,其实创建子进程后,子进程将父进程的资源复制一份,再去执行相关代码,进程间资源不共享
5、进程间通信
进程间的通信可以用很多方法,就是让一个进程把数据存储到一个中间区域,然后另一个进程到此区域获取即可。例如:
- socket:通过ip和端口将数据存储到互联网,另一个进程再到指定的端口取数据
- 文件:一个进程往文件里写数据,一个进程从文件读数据
- Queue队列:一个进程往队列放数据,一个进程从队列取数据
下面我们使用Queue队列实现进程间通信
主要用到的函数有:
1. q = multiprocessing.Queue() # 创建队列
2. q.put() # 放入数据,获取队列满时阻塞
3. q.put_nowait() # 放入数据,获取队列满时异常
4. q.get() # 获取数据,获取队列空时堵塞
5. q.get_nowait() # 获取数据,获取队列空时异常
6. q.full() # 判断队列是否满
7. q.empty() # 判断队列是否空
import multiprocessing
import time
def put_data(queue):
data = [11, 22, 33, 44]
for temp in data:
queue.put(temp)
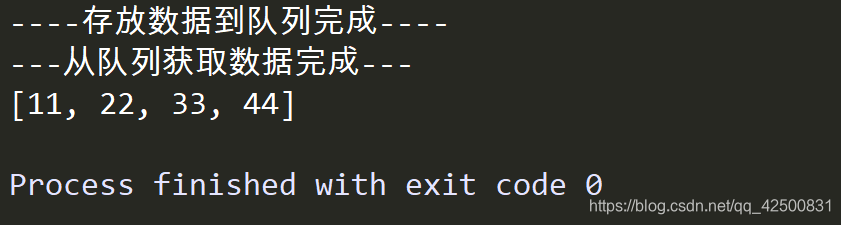
print("----存放数据到队列完成----")
def get_data(queue):
data_list = list()
while True:
data = queue.get()
data_list.append(data)
if queue.empty():
break
print("---从队列获取数据完成---")
print(data_list)
def main():
# 创建一个Queue
q = multiprocessing.Queue()
# 创建多个进程,将Queue的引用当作实参传递到进程里
p1 = multiprocessing.Process(target=put_data, args=(q,))
p2 = multiprocessing.Process(target=get_data, args=(q,))
p1.start()
time.sleep(1)
p2.start()
if __name__ == '__main__':
main()
4、进程池Pool
为什么使用进程池?
如果有大量任务需要多进程完成,则可能需要频繁的创建删除进程,给计算机带来较多的资源消耗。故我们准备一个进程池放入适当数量的进程,当需要处理事件时可以使用进程池中的进程处理,处理完成后不销毁该进程,而是重复利用该进程处理其他事件
使用方法:
- 创建进程池,并放入适当数量的进程
- 往进程池的等待队列中添加事件,此时进程池中的进程会开始处理事件
- 关闭进程池
- 回收进程池
创建进程池
pool = Pool()
往进程池等待队列中添加任务,以及携带参数
pool.apply_async( function,(args,) )
关闭进程池后,pool不再接收新的事件
pool.close()
join使得主进程阻塞。在进程池中,主进程不会等待子进程执行结束,需要手动阻塞。若是没有join,则主进程可能提前结束,所有子进程消亡
pool.join()
from multiprocessing import Pool
import os, time, random
def worker(msg):
t_start = time.time()
print("%s 号事件开始执行,进程号为%d" % (msg, os.getpid()))
time.sleep(random.random()*2)
t_stop = time.time()
print(msg, "号事件执行完毕,耗时%0.2f秒" % (t_stop-t_start))
def main():
pool = Pool(2) # 定义一个进程池,最大容量为2
for i in range(5):
pool.apply_async(worker, (i,))
print("-----start----")
pool.close()
pool.join()
print("-----end-----")
if __name__ == '__main__':
main()
运行结果:
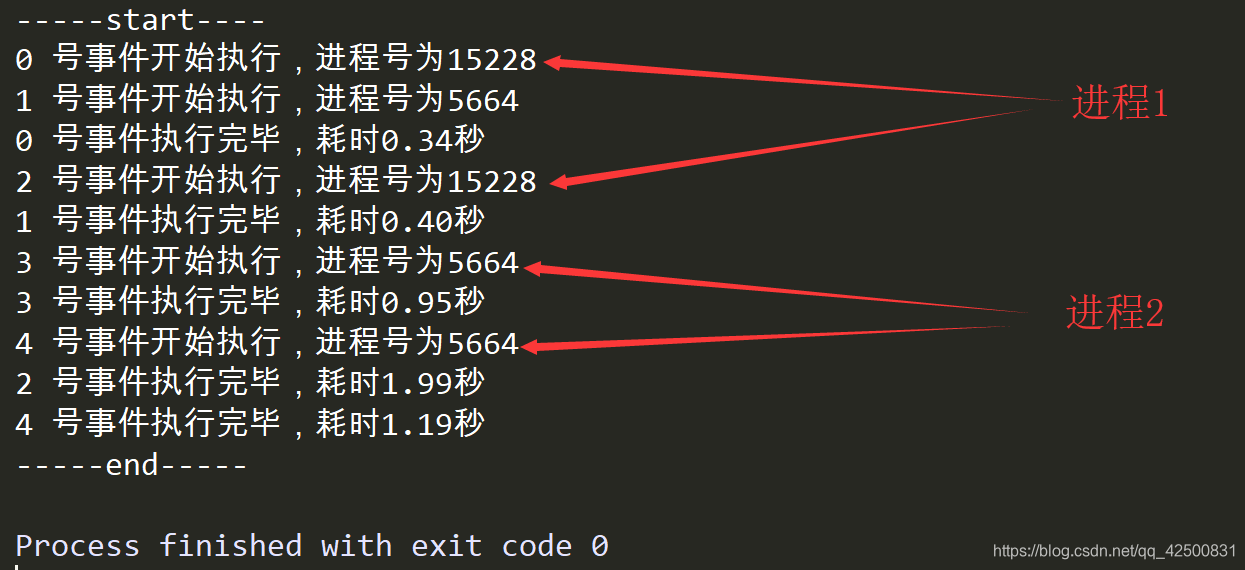
可以看到,5个事件只有2个进程在交替执行
三、进程和线程的分析与比较
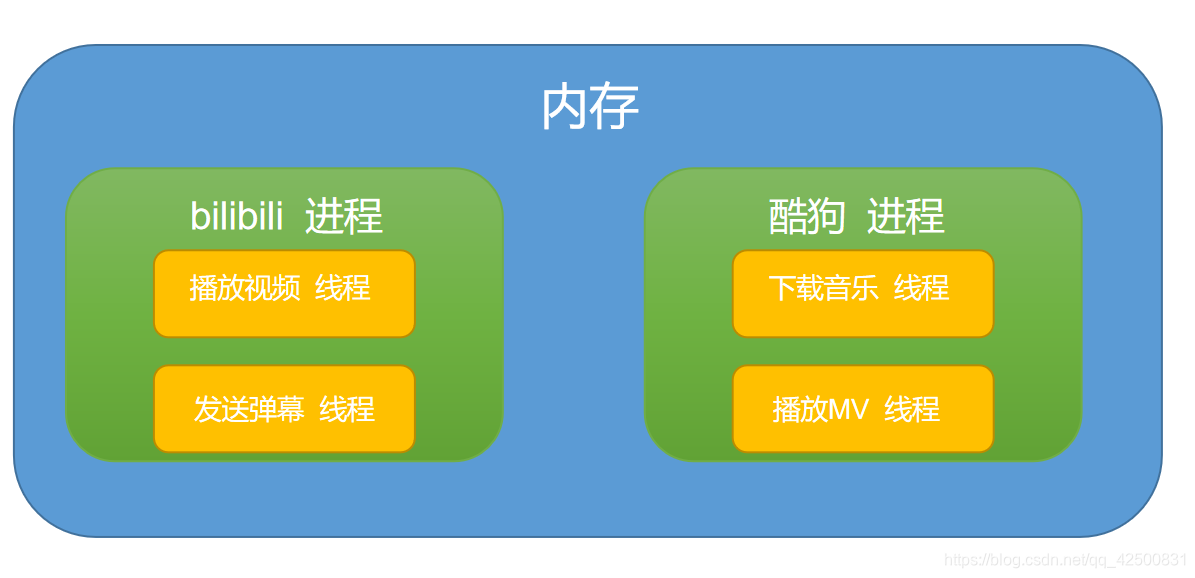
下面这张图,还是很形象的
比较:
- 本质: 进程是操作系统资源分配的基本单位,线程是任务调度和执行的基本单位。进程只是资源分配的单位,线程拿着这些资源去做事,一个进程至少有一个主线程做事。
- 资源共享: 进程之间资源独立,不共享。而线程组之间可以共享所属进程的资源。
- 内存分配: 系统在运行的时候会为每个进程分配不同的内存空间,建立数据表来维护代码段、堆栈段和数据段;除了 CPU 外,系统不会为线程分配内存,线程所使用的资源来自其所属进程的资源
- 通信: 进程通过套接字、文件、消息队列等方式通信,而线程通过共享全局变量、静态变量等数据进行通信。
- 健壮性: 每个进程之间的资源是独立的,当一个进程崩溃时,不会影响其他进程;同一进程的线程共享此进程的资源,当此进程发生崩溃时,线程也发生崩溃。线程容易出现共享与资源竞争产生的各种问题,如死锁等
- 开销: 每个进程都有独立的代码和数据空间,进程之间的切换会有较大的开销;线程可以看做轻量级的进程,同一类线程共享代码和数据空间,每个线程都有自己独立的运行程序计数器和栈,线程之间切换的开销小
进程与线程的选择:
选择:
- 需要频繁创建销毁的优先使用线程。因为进程创建、销毁一个进程代价很大,需要不停的分配资源;线程频繁的调用只改变 CPU 的执行
- 线程的切换速度快,需要大量计算,切换频繁时,用线程
- 耗时的操作使用线程可提高应用程序的响应
- 线程对 CPU 的使用效率更优,多机器分布的用进程,多核分布用线程
- 需要跨机器移植,优先考虑用进程
- 需要更稳定、安全时,优先考虑用进程-
- 需要速度时,优先考虑用线程
- 并行性要求很高时,优先考虑用线程
参考文献https://www.javanav.com/interview/c1c5c5964574489c8d010c3e1a6f3362.html
