Celery定义:
Celery是一个简单、灵活且可靠的,处理大量消息的分布式系统
专注于实时处理的异步任务队列
同时也支持任务调度
Celery原理:
Celery执行过程中redis中key的变化:
执行后可看到 redis 上生成了两个 key
_kombu.binding.celery:这个不用管(我推测是 celery 服务的某个 id 标记)
celery:表示当前正在队列中的 task,等待被 worker 所接收
然后启动一个 worker
$celery worker -A a --loglevel=debug
执行后可看到 celery 这个 key 消失了,同时新增了 2 个 key
celery 消失说明任务已经被刚启动的 worker 接收了,worker 会自己去执行这个 task,当前没有等待被接收的任务
_kombu.binding.celery.pidbox:这个也不用管(我推测也是 celery 服务的某个 id 标记)
_kombu.binding.celeryev:这个我推测是当前连接到这个 redis 的 worker 的列表,每一行表示有一个 worker,但有时会多出来几行,这个我也没搞明白,总之这个不重要
下面我们试一下延时任务
test_task.apply_async(('==== ttttt2 =====', ), countdown=60)
然后启动脚本,发起一个60秒后执行任务,并且开启 celery 准备执行任务
celery worker -A a --loglevel=debug
在 60 秒内查看 redis,可以看到没有出现 celery 这个 key,但多出了另外两个 key
unacked:可以理解为这个是被 worker 接收了但是还没开始执行的 task 列表(因为60秒后才会开始执行)
unacked_index:用户标记上面 unacked 的任务的 id,理论上行数应该和 unacked 的行数是一样的
60 秒后再次查看 redis,可以看到 redis 中的 key 又回到了无任务的状态
这表示被 worker 领取的任务确实在 60 秒后执行了
结论,由此可以推测出 celery 和 redis 之间交互的基本原理:
celery 和 redis 之间交互的基本原理:
1、当发起一个 task 时,会向 redis 的 celery key 中插入一条记录。
2、如果这时有正在待命的空闲 worker,这个 task 会立即被 worker 领取。
3、如果这时没有空闲的 worker,这个 task 的记录会保留在 celery key 中。
4、这时会将这个 task 的记录从 key celery 中移除,并添加相关信息到 unacked 和 unacked_index 中。
5、worker 根据 task 设定的期望执行时间执行任务,如果接到的不是延时任务或者已经超过了期望时间,则立刻执行。
6、worker 开始执行任务时,通知 redis。(如果设置了 CELERY_ACKS_LATE = True 那么会在任务执行结束时再通知)
7、redis 接到通知后,将 unacked 和 unacked_index 中相关记录移除。
8、如果在接到通知前,worker 中断了,这时 redis 中的 unacked 和 unacked_index 记录会重新回到 celery key 中。(这个回写的操作是由 worker 在 “临死” 前自己完成的,所以在关闭 worker 时为防止任务丢失,请务必使用正确的方法停止它,如: celery multi stop w1 -A proj1)
9、在 celery key 中的 task 可以再次重复上述 2 以下的流程。
使用场景:
异步任务,将耗时操作提交给Celery去异步执行,比如发送短信/邮件/消息推送。音视频处理等等
定时任务。类似于crontab,比如每日数据统计
Celery架构:
组成架构图:
Celery的架构由三部分组成,消息中间件(message broker)、任务执行单元(worker)和 任务执行结果存储(task result store)组成。
2.1 消息中间件
Celery本身不提供消息服务,但是可以方便的和第三方提供的消息中间件集成。包括,RabbitMQ, Redis等等
2.2 任务执行单元
Worker是Celery提供的任务执行的单元,worker并发的运行在分布式的系统节点中。
2.3 任务结果存储
Task result store用来存储Worker执行的任务的结果,Celery支持以不同方式存储任务的结果,包括AMQP,Redis等
2.4 版本支持情况
Celery version 4.0 runs on
Python ❨2.7, 3.4, 3.5❩
PyPy ❨5.4, 5.5❩
This is the last version to support Python 2.7, and from the next version (Celery 5.x) Python 3.5 or newer is required.
If you’re running an older version of Python, you need to be running an older version of Celery:
Python 2.6: Celery series 3.1 or earlier.
Python 2.5: Celery series 3.0 or earlier.
Python 2.4 was Celery series 2.2 or earlier.
Celery is a project with minimal funding, so we don’t support Microsoft Windows. Please don’t open any issues related to that platform.
功能架构图:
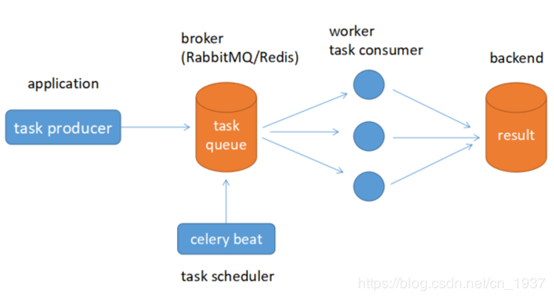
组件介绍
Producer : 任务生产者. 调用 Celery API , 函数或者装饰器, 而产生任务并交给任务队列处理的都是任务生产者。
Broker : 消息代理, 队列本身. 也称为消息中间件. 接受任务生产者发送过来的任务消息, 存进队列再按序分发给任务消费方(通常是消息队列或者数据库). 通常用 RabbitMQ或者Redis
Celery Beat : 任务调度器. Beat 进程会读取配置文件的内容, 周期性的将配置中到期需要执行的任务发送给任务队列.例如如下配置的一个周期性执行的一个任务:
CELERYBEAT_SCHEDULE = { 'send_mail': { 'task': 'work.notify.email.send_mail', # 'schedule': timedelta(minute=1), 'schedule': crontab(minute='*/1'), 'args': ('usr', 'sub', 'msg') }
}
任务调度主要是为了解决业务场景中定时或周期任务,分别使用timedelta和crontab来定义计划任务,crontab的精度无法精确到秒时可使用timedelta代替,CELERYBEAT_SCHEDULE下可以定义多个计划/周期任务,send_mail为任务名称,task为任务单元导入名,schedule为具体调度,args为任务单元的参数.
运行时可先启动work进程池(celery worker -A work.app -l info)然后再启动beat进程池(celery beat -A work.app -l info),观察会发现beat进程每分钟生成一个任务,work进程发现任务后立即执行
Celery Worker : 执行任务的消费者, 通常会在多台服务器运行多个消费者, 提高运行效率.
Result Backend : 任务处理完成之后保存状态信息和结果, 以供查询.
Celery安装配置:
pip install celery
pip install celery[redis]
Celery异步执行任务:
示例:使用任务调度配置,执行celery任务(add, div)
知识点:
- 配置CELERYBEAT_SCHEDULE定时任务配置(timedelta,crontab)
- 导入指定的任务模块
- bind=True的使用(包括:内部如何调用self.retry方法)
- base=MyTask捕获任务状态函数使用(包括:添加循环引用时候使用)
代码如下:
#=======新建proj1项目(python package包) #=======修改init初始化文件内: __author__ = "xiaoming" from celery import Celery app = Celery('celery-demo1') ##, include=["proj.tasks"] app.config_from_object("proj1.celeryconfig")
#=======修改celery配置文件: from datetime import timedelta from celery.schedules import crontab BROKER_URL = "redis://127.0.0.1:6379/1" CELERY_RESULT_BACKEND = "redis://127.0.0.1:6379/2" # 设置时区 CELERY_TIMEZONE = 'Asia/Shanghai' # 导入指定的任务模块 CELERY_IMPORTS = ( 'proj1.tasks' ) CELERYBEAT_SCHEDULE = { 'task1': { #每隔10秒钟执行任务 'task': 'proj1.tasks.add', 'schedule': timedelta(seconds=10), 'args': (2, 8) }, #每天的19:28分执行任务 'task2':{ 'task': 'proj1.tasks.div', 'schedule':crontab(hour=16, minute=2), 'args': (4, 5) } } # 使用 # Worker celery worker -A task -l INFO 启动worker # Beat: celery beat -A task -l INFO 启动beat # celery -B -A task worker -l INFO 同时启动beat worker、 # celery worker --help
#=======修改tasks.py文件 from celery import Task from proj1 import app from celery.utils.log import get_task_logger logger = get_task_logger(__name__) @app.task(bind=True) def div(self, x, y): logger.info(('Executing task id {0.id}, args: {0.args!r}' 'kwargs: {0.kwargs!r}').format(self.request)) try: result = x / y except ZeroDivisionError as e: raise self.retry(exc=e, countdown=5, max_retries=3) # 发生 ZeroDivisionError 错误时, 每 5s 重试一次, 最多重试 3 次. return result # tasks.py class MyTask(Task): def on_success(self, retval, task_id, args, kwargs): print('task done: {0}'.format(retval)) # add.apply_async(args) #添加循环引用时候使用 return super(MyTask, self).on_success(retval, task_id, args, kwargs) def on_failure(self, exc, task_id, args, kwargs, einfo): print('task fail, reason: {0}'.format(exc)) return super(MyTask, self).on_failure(exc, task_id, args, kwargs, einfo) # 正确函数, 执行 MyTask.on_success() : @app.task(base=MyTask) def add(x, y): return x + y # # 错误函数, 执行 MyTask.on_failure() : # @app.task # 普通函数装饰为 celery task # def add(x, y): # raise KeyError # return x + y
启动命令:
Windows启动
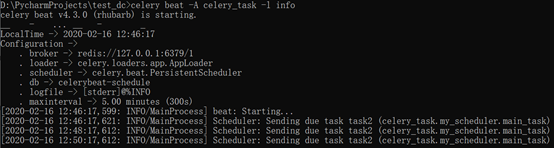
启动worker : celery worker -A proj1 -l info -P eventlet
启动beat : celery beat -A proj1 -l INFO
执行效果:

示例:基于celery的Task类实现任务的调度执行
知识点:
- 通过重写类中方法来跟踪业务的状态信息处理
- 定时任务配置,任务队列设置
- Task类中使用的参数
- 无用任务如何杀掉任务,如何获取任务的状态信息
代码如下:
Celery_task/__init__.py文件
#===============新建项目名称: celery_task(python package) #===============项目中初始化内容 init.py文件内容 from celery import Celery app = Celery('tasks') app.config_from_object('celery_task.celeryconfig')
/celery_task/celeryconfig.py文件
#===============celeryconfig配置文件内容 # from __future__ import absolute_import #以绝对路径引用文件 from celery.schedules import crontab from datetime import timedelta from kombu import Queue, Exchange BROKER_URL = "redis://127.0.0.1:6379/1" CELERY_RESULT_BACKEND = "redis://127.0.0.1:6379/2" # 时区设置 CELERY_TIMEZONE = 'Asia/Shanghai' CELERY_IMPORTS = ( 'celery_task.my_scheduler', 'celery_task.tasks' ) #定义执行任务的队列 #定义队列机制,来分别处理不同的task,达到充足的worker去执行 CELERY_QUEUES = ( Queue('default', exchange=Exchange('default'), routing_key='default'), Queue('app_task2', exchange=Exchange('app_task2'), routing_key='app_task2'), ) #然后定义routes用来决定不同的任务去哪一个queue CELERY_ROUTES = { # 'celery_task.tasks.collectiontask': {'queue': 'default', 'routing_key': 'default'}, 'celery_task.my_scheduler.main_task': {'queue': 'app_task2', 'routing_key': 'app_task2'} } PERIOD = 10 CELERYBEAT_SCHEDULE = { # 'task1': { # 'task': 'my_collect', # 'schedule': timedelta(seconds=30), # 'options': { # 'queue': 'app_task1' # } # }, 'task2': { 'task': 'celery_task.my_scheduler.main_task', 'schedule': timedelta(seconds=120), 'options': { 'queue': 'app_task2' } } }
/celery_task/my_scheduler.py文件
#===============my_scheduler.py文件中的内容: from celery_task import app import time from celery_task.tasks import collectiontask from celery.result import AsyncResult # from celery.app.control import Control @app.task() def main_task(): a = [] b = [] for task in range(1,2): # task=1 print("mian_task run") status = collectiontask.apply_async(args=('hello{}'.format(task),), queue='default', retry=True) print(f"status.id: {status.id}, status.task_id:{status.task_id}") a.append(status.id) b.append(status.task_id) # print("1setter",collectiontask.request.setter) # print("1deleter",collectiontask.request.deleter) # print("1fdel============================================",collectiontask.request.fdel) # print("1fset",collectiontask.request.fset) # print("1getter",collectiontask.request.getter) time.sleep(10) for ii in a: state = AsyncResult(id=str(ii), app=collectiontask.app) print("任务的状态是1:=================================", state) with open("1.txt", 'a') as fd: fd.write("state:{}\n".format(state)) for ii in b: # print("**********************************************************************") # celery_control = Control(collectiontask.app) # celery_control.revoke(str(ii), terminate=True, signal='SIGTERM') # time.sleep(2) state = AsyncResult(id=str(ii), app=collectiontask.app).status print("任务的状态是2:=================================", state) with open("2.txt", 'a') as fd: fd.write("state:{}\n".format(state))
Celery_task/asks.py文件
#===============tasks.py文件中的内容是: import time from celery.result import AsyncResult from celery.app.control import Control from celery.task import Task # from celery_task import app def test1(x): print("test1", x) def test2(x): print("test2", x) class collectiontask(Task): name = 'my_collect' def run(self, *args, **kwargs): if args[0] == 'hello0': pass else: try: b = 0 a = 1 / b except Exception as exc: # raise self.retry(countdown=3, exc=exc) # self.on_failure(exc=exc, task_id=self.request.id, args=args, kwargs=kwargs, einfo=self.request.delivery_info) self.on_failure(exc=exc, task_id=self.request.id, args=(11,22), kwargs=[], einfo=self.request.delivery_info) def on_success(self, retval, task_id, args, kwargs): print("task_id:", task_id) print("args:", args) print("kwargs:",kwargs) print(self.name) # collectiontask.apply_async(args, countdown=PERIOD) collectiontask.apply_async(args=args, queue='default',countdown=20) return super(collectiontask, self).on_success(retval, task_id, args, kwargs) def on_failure(self, exc, task_id, args, kwargs, einfo): print(f"f task_id: {task_id}") print(f"f args: {args}") print(f"f kwargs: {kwargs}") print(f"f einfo: {einfo}") print(f"f_exc: {exc}") print(f"type(exc): {type(exc)}") state = AsyncResult(id=str(task_id), app=self.app).state print(f"任务失败后该状态:{state}") celery_control = Control(collectiontask.app) celery_control.revoke(str(task_id), terminate=True, signal='SIGTERM') # collectiontask.app.control.revoke(task_id, terminate=True, signal='SIGTERM') time.sleep(5) state = AsyncResult(id=str(task_id), app=self.app).state print(f"失败任务杀掉后的状态是:{state}") return super(collectiontask, self).on_failure(exc, task_id, args, kwargs, einfo) def on_retry(self, exc, task_id, args, kwargs, einfo): print(f"重试任务r_exc:{exc}") print(f"重试的次数: {self.request.retries}") print(f"重试任务r_task_id:{task_id}") print(f"重试任务r_args: {args}") if self.request.retries == 2: celery_control = Control(self.app) celery_control.revoke(str(task_id), terminate=True, signal='SIGTERM') print(f"重试任务,杀任务成功!!!") #===============任务的启动命令: # celery beat -A celery_task -l info # celery worker -A celery_task -l info -P eventlet
import redis result = redis.StrictRedis(host='127.0.0.1', db=1, port=6379) print(result.keys()) result.flushall()
启动命令:
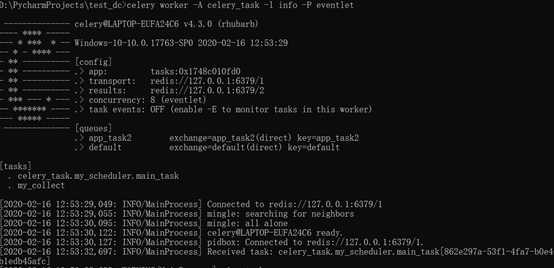
# celery beat -A celery_task -l info
# celery worker -A celery_task -l info -P eventlet
执行效果:
遗留问题:
杀任务失败(windows环境)
在window10系统中通过cmd启动任务,这对杀死worker功能,没有执行成功!
显示如下的问题:
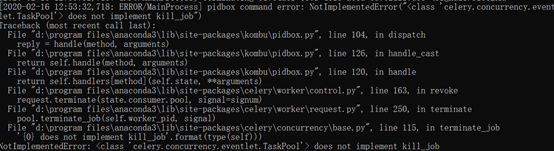
采用的方法是:
id = task_id["task_id"] state = AsyncResult(id=str(id), app=main.app).state # 这个是查看当前celery该任务的状态 # 停止任务 celery_control = Control(main.app) celery_control.revoke(str(id), terminate=True)
此种方法,我在linux系统中执行是成功的,不确定是什么原因导致,有知道的还望指点!!
Celery相关配置和命令:
相关配置(一般常用的):
# 注意,celery4版本后,CELERY_BROKER_URL改为BROKER_URL BROKER_URL = 'amqp://username:passwd@host:port/虚拟主机名' # 指定结果的接受地址 CELERY_RESULT_BACKEND = 'redis://username:passwd@host:port/db' # 指定任务序列化方式 CELERY_TASK_SERIALIZER = 'msgpack' # 指定结果序列化方式 CELERY_RESULT_SERIALIZER = 'msgpack' # 任务过期时间,celery任务执行结果的超时时间 CELERY_TASK_RESULT_EXPIRES = 60 * 20 # 指定任务接受的序列化类型. CELERY_ACCEPT_CONTENT = ["msgpack"] # 任务发送完成是否需要确认,这一项对性能有一点影响 CELERY_ACKS_LATE = True # 压缩方案选择,可以是zlib, bzip2,默认是发送没有压缩的数据 CELERY_MESSAGE_COMPRESSION = 'zlib' # 规定完成任务的时间 CELERYD_TASK_TIME_LIMIT = 5 # 在5s内完成任务,否则执行该任务的worker将被杀死,任务移交给父进程 # celery worker的并发数,默认是服务器的内核数目,也是命令行-c参数指定的数目 CELERYD_CONCURRENCY = 4 # celery worker 每次去rabbitmq预取任务的数量 CELERYD_PREFETCH_MULTIPLIER = 4 # 每个worker执行了多少任务就会死掉,默认是无限的 CELERYD_MAX_TASKS_PER_CHILD = 40 # 设置默认的队列名称,如果一个消息不符合其他的队列就会放在默认队列里面,如果什么都不设置的话,数据都会发送到默认的队列中 CELERY_DEFAULT_QUEUE = "default" # 设置详细的队列 CELERY_QUEUES = { "default": { # 这是上面指定的默认队列 "exchange": "default", "exchange_type": "direct", "routing_key": "default" }, "topicqueue": { # 这是一个topic队列 凡是topictest开头的routing key都会被放到这个队列 "routing_key": "topic.#", "exchange": "topic_exchange", "exchange_type": "topic", }, "task_eeg": { # 设置扇形交换机 "exchange": "tasks", "exchange_type": "fanout", "binding_key": "tasks", }, }
相关命令:
celery -A app.celery_tasks.celery worker -Q queue --loglevel=info # -A参数指定创建的celery对象的位置,该app.celery_tasks.celery指的是app包下面的celery_tasks.py模块的celery实例,注意一定是初始化后的实例,后面加worker表示该实例就是任务执行者; # -Q参数指的是该worker接收指定的队列的任务,这是为了当多个队列有不同的任务时可以独立;如果不设会接收所有的队列的任务; 发布任务 celery -A celery_task beat 执行任务 celery -A celery_task worker -l info -P eventlet 将以上两条合并 celery -B -A celery_task worker 后台启动celery worker进程 celery multi start work_1 -A appcelery 停止worker进程,如果无法停止,加上-A celery multi stop WORKNAME 重启worker进程 celery multi restart WORKNAME 查看进程数 celery status -A celery_task # -l参数指定worker输出的日志级别;
分析序列化的消息:
将序列化消息反序列化
{"body": "gAJ9cQAoWAQAAAB0YXNrcQFYGAAAAHRlc3RfY2VsZXJ5LmFkZF90b2dldGhlcnECWAIAAABpZHEDWCQAAAA2NmQ1YTg2Yi0xZDM5LTRjODgtYmM5OC0yYzE4YjJjOThhMjFxBFgEAAAAYXJnc3EFSwlLKoZxBlgGAAAAa3dhcmdzcQd9cQhYBwAAAHJldHJpZXNxCUsAWAMAAABldGFxCk5YBwAAAGV4cGlyZXNxC05YAwAAAHV0Y3EMiFgJAAAAY2FsbGJhY2tzcQ1OWAgAAABlcnJiYWNrc3EOTlgJAAAAdGltZWxpbWl0cQ9OToZxEFgHAAAAdGFza3NldHERTlgFAAAAY2hvcmRxEk51Lg==",
# body是序列化后使用base64编码的信息,包括具体的任务参数,其中包括了需要执行的方法、参数和一些任务基本信息
"content-encoding": "binary", # 序列化数据的编码方式
"content-type": "application/x-python-serialize", # 任务数据的序列化方式,默认使用python内置的序列化模块pickle
"headers": {},
"properties":
{"reply_to": "b7580727-07e5-307b-b1d0-4b731a796652", # 结果的唯一id
"correlation_id": "66d5a86b-1d39-4c88-bc98-2c18b2c98a21", # 任务的唯一id
"delivery_mode": 2,
"delivery_info": {"priority": 0, "exchange": "celery", "routing_key": "celery"}, # 指定交换机名称,路由键,属性
"body_encoding": "base64", # body的编码方式
"delivery_tag": "bfcfe35d-b65b-4088-bcb5-7a1bb8c9afd9"}}
常见的数据序列化方式
binary: 二进制序列化方式;python的pickle默认的序列化方法; json:json 支持多种语言, 可用于跨语言方案,但好像不支持自定义的类对象; XML:类似标签语言; msgpack:二进制的类 json 序列化方案, 但比 json 的数据结构更小, 更快; yaml:yaml 表达能力更强, 支持的数据类型较 json 多, 但是 python 客户端的性能不如 json 经过比较,为了保持跨语言的兼容性和速度,采用msgpack或json方式; 比如: CELERY_TASK_SERIALIZER = 'msgpack' CELERY_RESULT_SERIALIZER = 'msgpack' CELERY_TASK_RESULT_EXPIRES = 60 * 60 * 24 # 任务过期时间 CELERY_ACCEPT_CONTENT = ["msgpack"] # 指定任务接受的内容序列化的类型.
Celery遇到的坑:
中间件redis无法连接:
问题如下:
[2020-02-15 14:45:03,340: ERROR/MainProcess] consumer: Cannot connect to redis://localhost:6379/1: Error 10060 connecting to localhost:6379. WSAETIMEDOUT..
Trying again in 2.00 seconds...
问题分析:
Redis没有启动,查看windows10服务,redis服务已经启动(重启后还是无效)
关闭windows10关联的redis服务,手动启动redis服务(无效)
//手动启动命令D:\Program Files\Redis> .\redis-server.exe redis.windows.conf
解决方法:
Redis服务启动保持不变,通过调整broker和backend
BROKER_URL = "redis://localhost:6379/1"
CELERY_RESULT_BACKEND = "redis://localhost:6379/2"
改为:
BROKER_URL = "redis://127.0.0.1:6379/1"
CELERY_RESULT_BACKEND = "redis://127.0.0.1:6379/2"
Celery任务出现未注册的任务:
问题如下:
[2020-02-15 14:48:52,934: ERROR/MainProcess] Received unregistered task of type 'proj.tasks.add'.
The message has been ignored and discarded.
Did you remember to import the module containing this task?
Or maybe you're using relative imports?
问题分析:
'proj.tasks.add'.这个引用包,在celery中无法注册,因此寻找能够注册该任务的方法
解决方法:
方法1:在配置文件里添加以下代码:
CELERY_IMPORTS = (
"proj.tasks"
) #注意没有逗号
方法2: 通过项目初始化init文件中添加如下的代码,通过include 加载进来
from celery import Celery
app = Celery('celery-demo', include=["proj.tasks"])
app.config_from_object("proj.celeryconfig")’
解决后效果如下:

参考:
https://www.cnblogs.com/cwp-bg/p/8759638.html