笔者是一个痴迷于挖掘数据中的价值的学习人,希望在平日的工作学习中,挖掘数据的价值,找寻数据的秘密,笔者认为,数据的价值不仅仅只体现在企业中,个人也可以体会到数据的魅力,用技术力量探索行为密码,让大数据助跑每一个人,欢迎直筒们关注我的公众号,大家一起讨论数据中的那些有趣的事情。
我的公众号为:livandata

推荐系统的重要性已经不需要过多的强调了,随处一搜索就能看到各领域的大佬告诉你推荐系统的构建方法,面试的时候不讲几个协同都不好意思说自己懂算法,各个资料都会对协同的每一个细节详细描述,不知大家看完之后有没有一个感触:各个知识点都了解了,就是串不起了,而且也多少会有些疑惑,就这么简单?被全宇宙的人推崇的推荐算法就是简单的几个表的来回计算吗?那平时我们应用的机器学习的各种算法都去哪里了?
1、协同推荐算法数理表达:
市面上能接触到的推荐内容主要有两类:一类是协同,多个表之间的计算推到,有一些机器学习的影子,但是明显感觉到机器学习算法是对协同的一次次补充,不是推荐的主流算法,再深究一下,很多人就开始大肆宣传深度学习的神奇之处,用深度学习进行推荐推演是多么的精准高效。一时间搞的笔者一头雾水。笔者也就这个问题咨询过一些老牌的推荐大佬,得到了各种各样的答案。深思良久,笔者将自己对推荐算法的一些理解整理出来,有不足之处欢迎大家批评指正:
1)推荐算法本质上不是一个技术问题,而是一个用技术解决问题的解决方案。
推荐的产生是由于产品越来越多,而由于精力、手机屏幕大小的限制,客户能看到的范围有限,长尾现象越来越严重,为了方便客户获取到想要的产品,各个公司开始考虑根据用户的喜好推荐客户有倾向的产品,尽量减少马太效应,推荐系统应运而生。
2)推荐算法不是一个算法,而是一套算法集合,其算法范围无所不包容。
推荐算法是由一系列算法组合而成,每个算法应用场景不一样,各个公司根据各自的客户特征和商品属性,挑选适合本公司使用的推荐逻辑,使用的算法也不完全一样。协同推荐算法是比较早被研发出来的推荐逻辑,因为其逻辑较为清晰、可解释性比较强、数据兼容性、可执行性和工程化比较好,所以一直被各个公司应用,后期推出的基于模型的推荐、基于深度学习的推荐也都能看到协同推荐的影子,可以说协同推荐是现在各个公司推荐系统的基础逻辑。
本文从推荐基础的角度,将各个协同推荐的逻辑串联在一起,希望能将协同推荐的基本结构描述清楚,如有不足之处请指正:
协同推荐的基本内容主要有三部分:
1)基于用户相似的推荐:
主要是找寻兴趣喜好相似的用户,然后根据用户购买的商品将商品推荐给相似的用户。
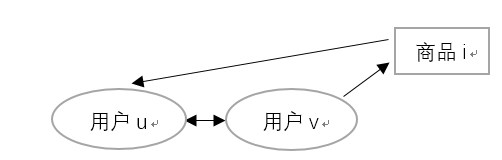
u, v用户是相似用户,v用户购买了商品i,则为u用户推荐i商品。
用户相似度(以余弦定理计算):
![]()
其中,用户u和用户v,令N(u)表示用户u曾经有过正面反馈的物品集合。
用户对物品的感兴趣程度:
![]()
其中,S(u,K)包含和用户u兴趣相近的K个用户,N(i)是对物品i有过行为的用户集合。Wuv是用户u和用户v的相似度,![]() 代表用户v对物品i的兴趣,以评分表中的评分表示。
代表用户v对物品i的兴趣,以评分表中的评分表示。
2)基于物品相似的推荐:
主要是找寻相似的商品,然后根据用户购买的商品清单将相似商品推荐给用户。
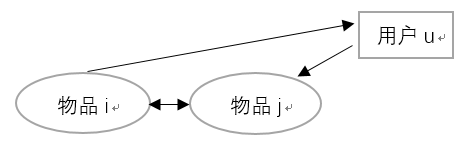
物品i和物品j是相似产品,用户u喜欢物品j,故向用户u推荐物品i。
物品相似度为:
![]()
其中,![]() 是喜欢物品i的用户数。
是喜欢物品i的用户数。![]() 是同时喜欢物品i和j的用户数。
是同时喜欢物品i和j的用户数。
用户对物品的喜好程度为:
![]()
其中,N(u)是用户u喜欢的物品集合,S(j,K)是和物品j最相似的K个物品集合,wij是物品i和j的相似度,rui是用户u对物品i的兴趣,以评分表中的评分表示。
3)基于标签的推荐:
本文没有专门描述基于内容的推荐算法,而是将其融入到基于标签的推荐算法中,主要是因为基于内容的推荐是在用户和物品之间找寻中间因子,而基于标签的推荐是在物品和用户之间找寻相关标签(如果我理解的不正确,请指正~),笔者认为这两个算法的原理相同,因此只介绍标签的推荐算法。
标签系统的主要原理是通过一定的方式标记出用户和商品的标签,进而通过标签关联用户和商品。

方式有很多种,很多公司会选择人工的方式,为每一个商品添加对应的标签,然后计算每个用户对各个标签的喜好程度。
用户对标签的喜好程度为![]() :
:
![]()
其中:
![]()
![]()
![]()


![]()

4)基于上下文的推荐:
基于上下文的推荐是在上面三种协同推荐的基础上添加上下文的因素,常见的上下文场景即为:“热门惩罚”、“时间衰退”。
常规的基于用户协同的推荐为:
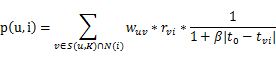
在此基础上修改计算方法为:
其中,![]() 为计算用户相似度时的时间衰减函数,
为计算用户相似度时的时间衰减函数,![]() 为对物品i产生过行为的用户个数,α为时间衰减因子,
为对物品i产生过行为的用户个数,α为时间衰减因子,![]() 为热门惩罚函数。
为热门惩罚函数。
![]() 为用户对物品评分时的时间衰减函数。
为用户对物品评分时的时间衰减函数。
由此可以得出新的推荐计算方式。
通过上面的描述,大家是不是对推荐算法有一个数理方面的了解呢?不知道有多少大佬看到这里,接下来我们用库表的语言再进行一次汇总描述,毕竟,我们的所有计算最终都是要落到数据仓库中的,表的形式表达是IT人员的必经之路。
2、协同推荐算法的库表表达:
上面五花八门的公式怎么用?我们在构建基本推荐系统时需要预先处理几张表?这些恐怕是推荐算法设计时的灵魂拷问吧。作为一个产品经理,特别是数据产品经理,在沟通推荐的需求的时候如果拿着上面的公式去找IT恐怕会被打回来吧,那我们下面将它转换成计算机人员比较喜欢的表的结构图。
先聊一下推荐的基本结构吧,大家都执迷于算法的推演,其算法的重要性已经不用多言了,他在整个推荐系统中处于什么位置呢?
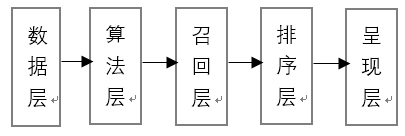
从上面可以看出算法是立根于底部的一层结构,从整个大数据仓库中获取数据,再在算法层进行运算,将运算结果放入召回层,然后在排序层对召回的内容进行排序,最终呈现在页面上。其中,召回层是指将满足用户喜好的前K个物品从数据层提取到这一层次,等待呈现备用,排序层则是根据一定的排列规则,加入随机因子,按照用户的喜好进行排序的层级。排序层也是有各种算法的,这里的算法主要是解决如何高效的按照喜好进行排序?在什么位置放置用户最喜欢的商品?如何添加随机因子以保证数据的多样性?等。
简单讲完算法的位置,我们还是回到协同算法上来,毕竟这篇文章主要讲解的是算法。
汇总上面的几个推荐算法,有没有感觉无论如何都离不来两张表:U-V评分表、商品标签表,清爽~,我们的整个协同推荐算法体系中,这两张表可以说是异常重要,一定要首先构建完成,然后再在这两张表的基础上进行计算延伸。
图表结构如下:
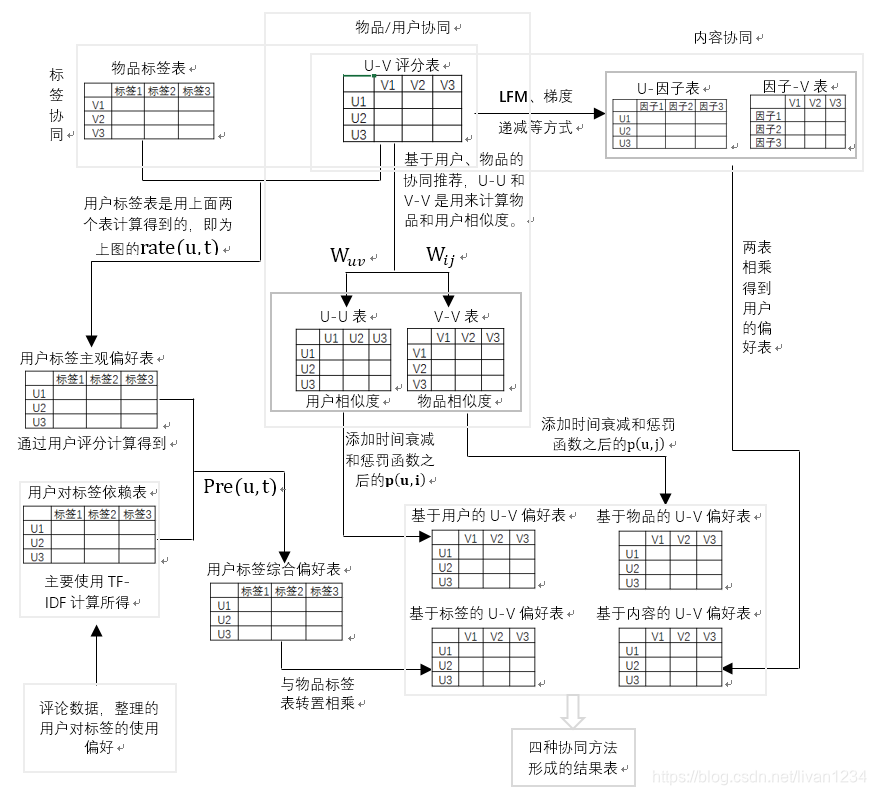
从上面的表逻辑中是否能够看出一些端倪呢?
上面的表虽然看起来较为复杂,但是整体的思路还是很明确的,公司最初构建两个表:物品标签表和U-V评分表,在这两个表的基础上构建下面的一长串表,然后经过各种运算,实现底端的四个“U-V偏好表”,作为推荐表。这四个表在平时生产中一般会有多个,因其使用场景不同,推荐时往往会综合使用。
上面讲述了基本的四种推荐算法的常用套路以及对应的图表结构,初创公司往往会使用一些类似的图表结构,其复杂程度也相对简单,但是随着应用场景的逐渐增多,以及对公司客户/商品的深入了解,上述数据表结构就会日趋复杂了。
比如:
1)添加什么逻辑能够增加推荐的稳健性,不至于因为脏数据而引发推荐大的波动?
2)如何优化冷启动的问题?
3)公司新添加社交链该如何应用到推荐中?
4)喜欢某个新闻的人不一定对相似的新闻感兴趣怎么解决?
5)放入到召回池中的数据如何排序?
6)如何避免出现“信息茧房”,使用户看到多样化的内容?
文章一开始笔者也讲过,推荐系统本身是一套解决方案,随着发现的问题越来越多,越来越多的解决思路也呈现出来,这一文章作为推荐的基础篇,希望能给大家带来一些有价值的思考。
