本篇是数据的整理与分类
比赛链接
https://www.tinymind.cn/competitions/47?rron=banner
当我看到这个比赛的时候,热身赛已经结束了,不过也觉得自己不可能拿奖金,练习一下技术还是可以的。

下载下来训练集后,发现是九种面值的大集合,需要将他们分类,同时给了一个csv文件,里边放着对应图片的面值,这个时候就需要整理一下了。
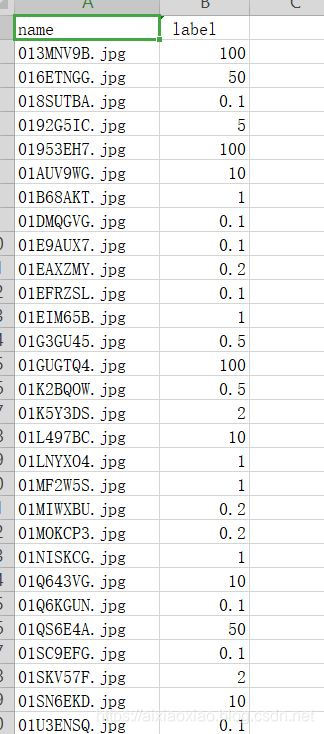
原始训练集展示
给定的训练集文件如下图:

原始csv文件展示
给定的csv文件如下图:
文件整理结果
我们需要把文件整理成如下格式:
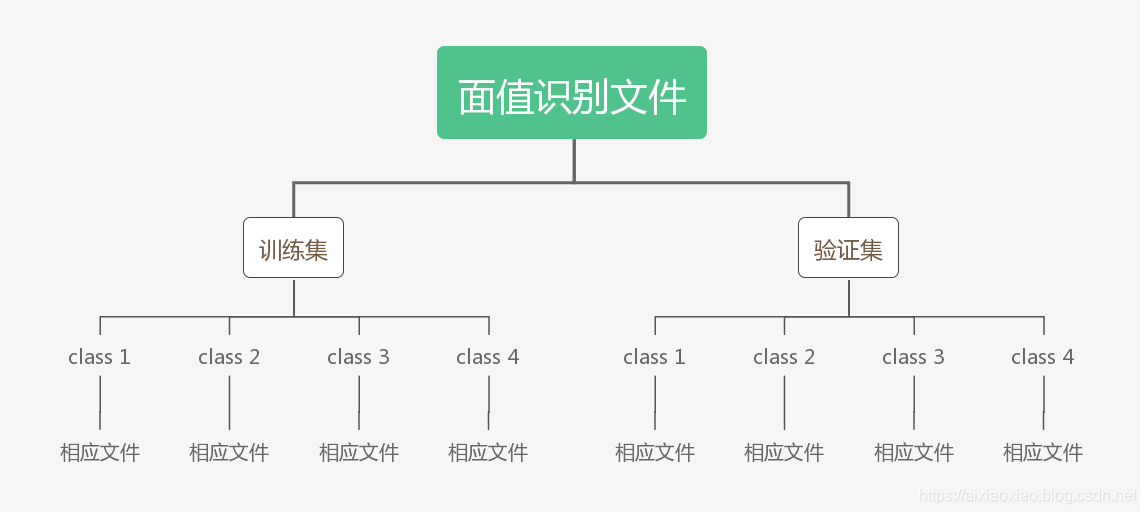
验证集可以从训练集中剪切部分出来,注意!注意!注意!是剪切不是复制,训练集中不能有验证集的图片,不然容易出现过拟合,而且得到的结果都是骗你的。
整理过程当然是用代码,结果如下:
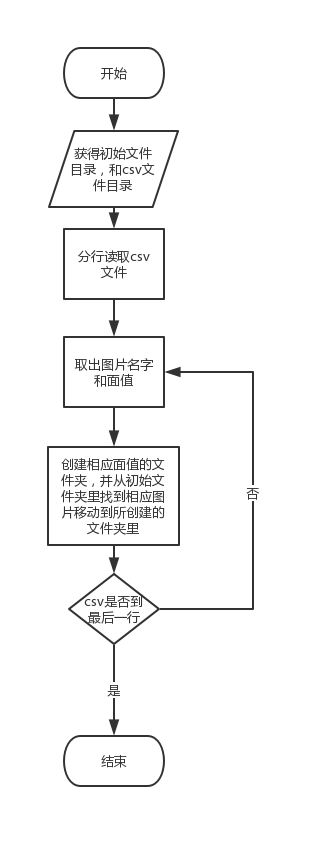
流程图
当然类别不止这些,思路也不只一种,也都是我自己想的,下边写一下流程图:
完整代码
代码如下:
注释很清晰
import os,shutil
face_value_label = open('train_face_value_label.csv','r')
start_dir = 'H:/face_value_check/val_data_test/' #数据原始目录
target_dir = 'H:/face_value_check/val_data/' #数据最终目录
dictionary = {'0.1':'A','0.2':'B','0.5':'C','1':'D','2':'E','5':'F','10':'G','50':'H','100':'I'}
#采用合理的名字给文件进行命名
lable_lists = face_value_label.readlines()
si = 0
if os.path.isdir(target_dir) == False:
os.mkdir(target_dir)
#如果没有目标目录,就创建一个目录
max_num = len(os.listdir(start_dir))
#获得初始文件夹中图片的数量
for li in lable_lists:
li = li[:-1]
name_label = li.split(',')
if name_label[0] == 'name':
continue #第一行数据是无效数据,不进行处理
if os.path.isfile('{0}{1}'.format(start_dir,name_label[0])) == True:
if os.path.isdir('{0}label_{1}'.format(target_dir,dictionary[name_label[1]])) == False:
os.mkdir('{0}label_{1}'.format(target_dir,dictionary[name_label[1]]))
shutil.copy('{0}{1}'.format(start_dir,name_label[0]),'{0}label_{1}/{2}'.format(target_dir,dictionary[name_label[1]],name_label[0]))
#创建文件夹并移动文件
si += 1 #记录次数
progress = (si / max_num) * 100
progress = round(progress,1)
#progress = si / len(os.listdir('./val_data_test/'))
print('成功复制{0},进度:{1}%'.format(name_label[0],progress))
#打印复制进度
处理过程解析
csv文件处理:
首先将图片按面值来分一下类,也就是相同面值的放到一起,因为面值是有大小的,所以我直接按照面值来排序就行了,变成了下边这个样子:

这样我们整理起来就会非常方便。
使用字典更换名字解释:
dictionary = {'0.1':'A','0.2':'B','0.5':'C','1':'D','2':'E','5':'F','10':'G','50':'H','100':'I'}
这行代码需要解释一下,在程序里它的排序并不会和Excel里一样,它会先比较第一个数的大小,再比较第二个数的大小,比如当你使用面值来命名文件的时候,它的排序如下:
0.1,0.2,0.5,1,10,100,2,5,50
这样我们在处理的时候就会遇到一些麻烦,虽然也能解决,但是我感觉还是不太舒服,所以我将他们换成了ABCDE这样来比较,可以获得正确的顺序
