一、 Iterator 是什么?
1、迭代器模式
迭代器模式(Iterator Pattern)是一种非常常见的设计模式,这种模式用于顺序访问集合对象的元素,而不需要知道集合对象内部的实现方式。
所以,迭代器模式的优点就是:简化了聚合类。无论是增加新的聚合类还是增加迭代器类都会很方便,无须修改原有的代码。
它的优点也导致了它的缺点:由于迭代器模式将存储数据和遍历数据的职责分离,增加新的聚合类时也需要对应增加新的迭代器类,耦合度很高,这在一定程度上增加了系统的复杂性。
2、Iterator 接口
在 Java 中,提供了一个迭代器接口 Iterator ,把在集合对象中元素之间遍历的工作交给迭代器,而不是集合对象本身,迭代器为遍历不同的集合对象提供一个统一的接口。这就是 Java 集合框架中 Iterable 接口位于框架结构最顶层的原因。这其实也就是面向对象的思想。
二、Iterator 的使用
下面我们先看看 Iterator 是如何使用的。
1、Iterator 中的方法
先从 Iterator 接口的源码来分析一下:
public interface Iterator<E> {
boolean hasNext();
E next();
default void remove() {
throw new UnsupportedOperationException("remove");
}
default void forEachRemaining(Consumer<? super E> action) {
Objects.requireNonNull(action);
while (hasNext())
action.accept(next());
}
}
可以看到,Iterator 接口提供的方法很少,也比较简单:
boolean hasNext():如果迭代中还有更多的元素,则返回true,否则返回false;E next():返回迭代中的下一个元素;default void remove():从集合中移除此迭代器返回的最后一个元素,它是一个可选的操作;default void forEachRemaining(Consumer action):对每个剩余元素执行给定的操作,直到所有元素都已处理完毕或该操作引发异常。
2、Iterator 基本示例
了解了 Iterator 提供的方法,下面我们来使用一下:
import java.util.Iterator;
import java.util.LinkedList;
public class Main {
public static void main(String[] args) {
LinkedList<String> names = new LinkedList<String>();
names.add("Deepspace");
names.add("chenxingxing");
Iterator<String> namesIterator = names.iterator();
while (namesIterator.hasNext()) {
System.out.println(namesIterator.next());
}
}
}
输出结果为:
Deepspace
chenxingxing
其实,我们也可以使用 foreach 方法来遍历集合:
for (String name : names) {
System.out.println(name);
}
我们再试试 remove 方法:
public class Main {
public static void main(String[] args) {
List<String> names = new LinkedList<String>();
names.add("E-1");
names.add("E-2");
names.add("E-3");
names.add("E-n");
Iterator<String> namesIterator = names.iterator();
while (namesIterator.hasNext()) {
String next = namesIterator.next();
System.out.println(next);
if ("E-3".equals(next)) {
namesIterator.remove();
}
}
System.out.println(names); // [E-1, E-2, E-n]
}
}
可以看到 E-3 这个元素被移除掉了。
再看看 forEachRemaining 方法(注意,该方法是没有返回值的):
import java.util.Iterator;
import java.util.LinkedList;
import java.util.List;
public class Main {
public static void main(String[] args) {
List<String> names = new LinkedList<String>();
names.add("E-1");
names.add("E-2");
names.add("E-3");
names.add("E-n");
List<String> targetList = new LinkedList<String>();
Iterator<String> namesIterator = names.iterator();
while (namesIterator.hasNext()) {
String next = namesIterator.next();
if ("E-3".equals(next)) {
namesIterator.remove();
namesIterator.forEachRemaining(targetList::add); // 这里用到了 Java8 里的新语法
}
}
System.out.println(targetList); // [E-3, E-n]
}
}
三、Iterator 内部是如何工作的?
下面我们来了解下 Java 迭代器及其方法是如何在内部工作的。以 LinkedList 对象为例。
创建一个 List 集合,并插入几条数据:
List<String> names = new LinkedList<String>();
names.add("E-1");
names.add("E-2");
names.add("E-3");
names.add("E-n");
现在在 List 对象上创建一个迭代器对象:
Iterator<String> namesIterator = names.iterator();
可以用下面的图来表示 nameIterator :
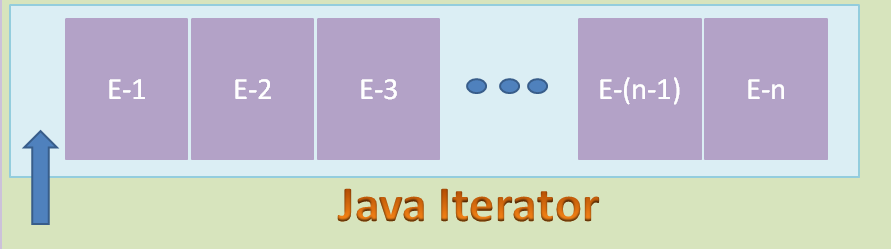
这里,Iterator 的 Cursor (光标)指向 List 的第一个元素之前。
下面我们再运行下面两行代码:
namesIterator.hasNext();
namesIterator.next();
这个时候,Iterator 的 Cursor 指向 List 中的第一个元素,如下图所示:
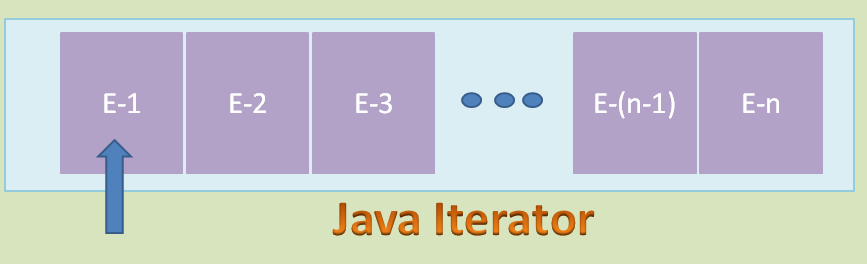
我们再运行一下刚才的两行代码:
namesIterator.hasNext();
namesIterator.next();
Iterator 的 Cursor 会指向 List 中的第二个元素:
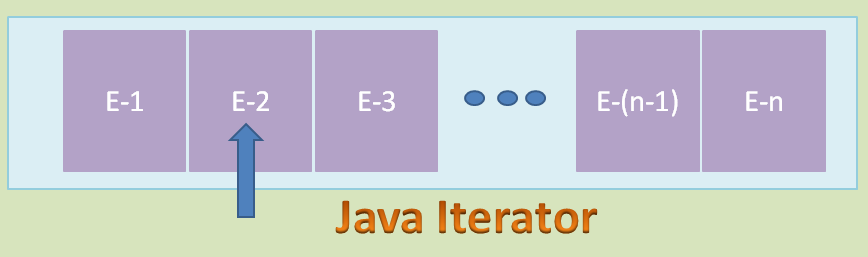
以此类推,重复执行此过程,可将 Iterator 的 Cursor 指向 List 中的最后一个元素。
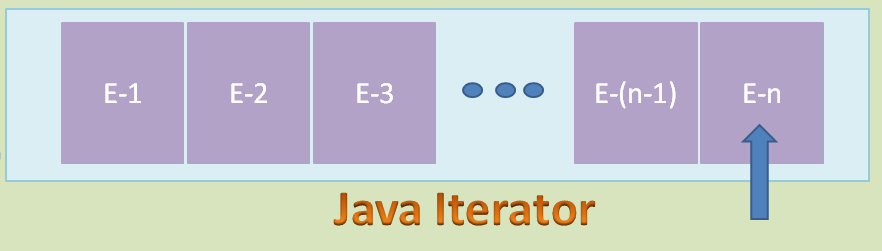
当读取最后一个元素后,如果继续运行下面的代码片段,它将返回 false 。
从上面的描述可以看出,Java 迭代器只支持如下图所示的前进方向迭代。
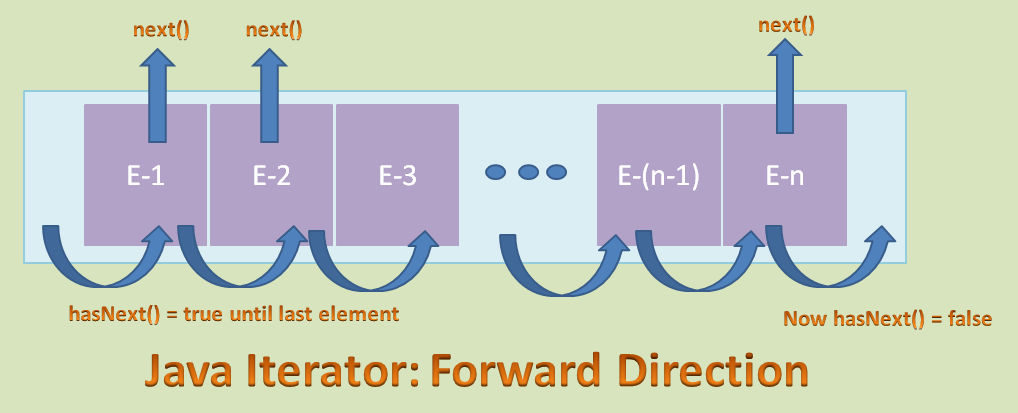
所以在一些地方迭代器也称为单向光标。
四、Iterator 的优缺点
从前面的讲解中,我们可以知道 Iterator 有以下优点:
- 可以在任何集合类中使用它,对于集合
API是通用的; - 它支持
READ和REMOVE操作; - 它的方法名称简单且易于使用。
但是它也有一些缺陷和限制:
- 在
CRUD操作中,它不支持CREATE和UPDATE操作; - 它只支持连续迭代(正向迭代),迭代时不支持迭代元素并行(与
Spliterator相比,我们待会讲到)。
什么是并行呢?
并行指的是以某种方式利用多核 CPU 单元进行编程。也就是说,要完成一项任务,可以将其分解为可以并行处理的单独的子任务,然后汇总所有已处理单元的结果以完成原始工作
五、ListIterator
Java 中也提供了一个 ListIterator 接口,该接口继承了 Iterator 接口,只对 List 实现的类有用。我们看看源码:
public interface ListIterator<E> extends Iterator<E> {
boolean hasNext();
E next();
boolean hasPrevious();
E previous();
int nextIndex();
int previousIndex();
void remove();
void set(E e);
void add(E e);
}
可以看到,ListIterator 接口新增了一些方法,可以在迭代的时候进行 UPDATE 和 ADD 的操作,所以 ListIterator 接口就完全支持 CURD 操作了。
同时,我们也可以从 newIndex 和 previous 方法中发现,ListIterator 是一个双向迭代器,支持正向迭代和反向迭代。
这里要注意,ListIterator 没有当前元素;它的光标位置始终位于 previous() 返回的元素和 next() 的返回的元素之间。
1、ListIterator 基本示例
import java.util.LinkedList;
import java.util.List;
import java.util.ListIterator;
public class Main {
public static void main(String[] args) {
List<String> names = new LinkedList<String>();
names.add("E-1");
names.add("E-2");
names.add("E-3");
names.add("E-n");
ListIterator<String> namesIterator = names.listIterator();
while (namesIterator.hasNext()) {
String next = namesIterator.next();
System.out.println(next);
if ("E-3".equals(next)) {
namesIterator.add("E-4");
}
if ("E-n".equals(next)) {
namesIterator.set("E-5");
}
}
System.out.println("\nFor Loop");
for (String name : names) {
System.out.println(name);
}
}
}
输出结果为:
E-1
E-2
E-3
E-n
For Loop
E-1
E-2
E-3
E-4
E-5
上面的代码演示了 UPDATE 和 ADD 操作。下面我们再看看,ListIterator 的方法如何执行前向和后向迭代。
import java.util.LinkedList;
import java.util.List;
import java.util.ListIterator;
public class Main {
public static void main(String[] args) {
List<String> names = new LinkedList<String>();
names.add("E-1");
names.add("E-2");
names.add("E-3");
names.add("E-n");
ListIterator<String> namesIterator = names.listIterator();
System.out.println("Forward Direction Iteration:");
while(namesIterator.hasNext()){
System.out.println(namesIterator.next());
}
System.out.println("Backward Direction Iteration:");
while(namesIterator.hasPrevious()){
System.out.println(namesIterator.previous());
}
}
}
输出结果为:
Forward Direction Iteration:
E-1
E-2
E-3
E-n
Backward Direction Iteration:
E-n
E-3
E-2
E-1
2、ListIterator 的局限性
与 Iterator 相比,ListIterator 有许多优势。 但是它仍然存在一些局限性:
- 它不适用于整个集合
API,只对List实现的类有用,而Iterator支持所有的集合类型; - 依然不支持元素的并行迭代;
六、Spliterator
最早的时候,那个时候 CPU 还是单核时代,Java 提供顺序遍历迭代器 Iterator 时,可以满足需求;但到了多核时代下,顺序遍历已经不能满足需求了,如何把多个任务分配到不同核上并行执行,最大发挥多核的能力,所以 Spliterator 就诞生了。
Spliterator 是 Java8 中新增的一个 API,除了支持顺序遍历之外,还支持高效的并行遍历。
由于是
Java8中新增的API,所以在介绍它的使用上,读者需要具备Stream和Lambda表达式的一些知识。
1、Spliterator 中的方法
1).characteristics():返回 Spliterator 数据对应的特征值。根据文档给出的例子,它返回的是多个特征码的按位或的结果:
public int characteristics() {
return ORDERED | SIZED | IMMUTABLE | SUBSIZED;
}
2).hasCharacteristics(int characteristics):如果这个 Spliterator 的 .characteristics() 包含所有给定的特征,则返回 true;
3).estimateSize():在执行前,将要遍历遇到的元素数量进行估算并返回估计值(long 类型),如果无法返回(包括正无穷、位置或者计算超时等情况)则返回 long.MAX_VALUE;
4).forEachRemaining(E e):在当前线程中,按顺序对集合中的每个剩余元素执行给定操作;
5).getComparator():如果该 Spliterator 的源是由 Comparator 排序的,则会将 Comparator 返回;
6).getExactSizeIfKnown():如果 estimateSize 的大小已知,则返回 .estimateSize() 方法的返回值,也就是数量的大小,否则返回 -1;
7).tryAdvance(E e):如果存在剩余元素,则对其执行给定操作,成功则返回 true,否则返回 false;
-
注意,该方法和
forEachRemaining是有区别的,官方给的示例是:public boolean tryAdvance(Consumer<? super T> action) { if (origin < fence) { action.accept((T) array[origin]); origin += 2; return true; } else // cannot advance return false; } -
从中我们可以看到该方法只执行一次,如果成功就返回
true否则返回false,而forEachRemaining是会循环执行的:public void forEachRemaining(Consumer<? super T> action) { for (; origin < fence; origin += 2) action.accept((T) array[origin]); }
8).trySplit():这个方法其实就是负责并行的方法,官方文档是这样描述的:
* <p>A Spliterator may also partition off some of its elements (using
* {@link #trySplit}) as another Spliterator, to be used in
* possibly-parallel operations. Operations using a Spliterator that
* cannot split, or does so in a highly imbalanced or inefficient
* manner, are unlikely to benefit from parallelism. Traversal
* and splitting exhaust elements; each Spliterator is useful for only a single
* bulk computation.
理解起来就是,可以使用这个方法对 Spliterator 对象的元素进行切分,用切分出来的部分创建一个新的Spliteraor 对象并返回,以方便进行并行操作。而调用该方法的线程会将返回的 Spliterator 交给另一个新的线程,新的线程又可以继续分区,这样就使得程序的执行速度大大提高。
那该分成多少个线程呢?如果线程池中线程数量过多,最终它们会与处理其它任务的线程来竞争稀缺的处理器和内存资源,浪费大量的时间在上下文切换上。反之,如果线程的数目过少,那么多核处理器的一些核可能就无法充分利用。这个问题在这里暂不讨论,会在并发编程里讲解。
2、Spliterator 的基本示例
下面我们将通过一个例子讨论 Spliterator 如何使用并行化更有效地遍历我们可以分解的 Stream 。
先看看其中的一些方法:
import java.util.ArrayList;
import java.util.List;
import java.util.Spliterator;
import java.util.stream.Stream;
public class Main {
public static void main(String[] args) {
List<String> mutants = new ArrayList<>();
mutants.add("Professor X");
mutants.add("Magneto");
mutants.add("Storm");
mutants.add("Jean Grey");
mutants.add("Wolverine");
mutants.add("Mystique");
// Obtain a Stream to the mutants List.
Stream<String> mutantStream = mutants.stream();
// Getting Spliterator object on mutantStream.
Spliterator<String> mutantList = mutantStream.spliterator();
// .estimateSize() method
System.out.println("Estimate size: " + mutantList.estimateSize());
// .getExactSizeIfKnown() method
System.out.println("\nExact size: " + mutantList.getExactSizeIfKnown());
System.out.println("\nContent of List:");
// .forEachRemaining() method
mutantList.forEachRemaining((n) -> System.out.println(n));
}
}
输出结果为:
Estimate size: 6
Exact size: 6
Content of List:
Professor X
Magneto
Storm
Jean Grey
Wolverine
Mystique
3、实现并行
再看看使用 trySplit() 方法,实现并行:
import java.util.ArrayList;
import java.util.List;
import java.util.Spliterator;
import java.util.stream.Stream;
public class Main {
public static void main(String[] args) {
List<String> mutants = new ArrayList<>();
mutants.add("Professor X");
mutants.add("Magneto");
mutants.add("Storm");
mutants.add("Jean Grey");
mutants.add("Wolverine");
mutants.add("Mystique");
Stream<String> mutantStream = mutants.stream();
// 创建一个新的 Stream.
Spliterator<String> splitList1 = mutantStream.spliterator();
// 调用 .trySplit() 方法,从 splitList1 中拆分一个 splitList2
Spliterator<String> splitList2 = splitList1.trySplit();
// 如果 splitList1 可以被拆分,也就说 splitList2 不为 null, 那就使用 splitList2.
if (splitList2 != null) {
System.out.println("\nOutput from splitList2:");
splitList2.forEachRemaining((n) -> System.out.println(n));
}
// 这里用 splitList1
System.out.println("\nOutput from splitList1:");
splitList1.forEachRemaining((n) -> System.out.println(n));
}
}
输出结果为:
Output from splitList2:
Professor X
Magneto
Storm
Output from splitList1:
Jean Grey
Wolverine
Mystique
七、Iterable 接口
我们发现,在集合框架的最顶层就是 Iterable 接口,该接口中只有三个方法,源码如下:
public interface Iterable<T> {
Iterator<T> iterator();
default void forEach(Consumer<? super T> var1) {
Objects.requireNonNull(var1);
Iterator var2 = this.iterator();
while(var2.hasNext()) {
Object var3 = var2.next();
var1.accept(var3);
}
}
default Spliterator<T> spliterator() {
return Spliterators.spliteratorUnknownSize(this.iterator(), 0);
}
}
其中,返回了一个 Iterator ,Spliterator 方法是 Java8 中新增的。
那么问题就来了,为什么集合框架一定要实现 Iterable 接口,而不直接实现 Iterator 接口呢?
通过前面的讲解,我们知道 Iterator 接口的核心方法是 next() 和 hasNext() 方法,而这两个方法是依赖于迭代器的当前迭代位置的。如果 Collection 直接实现 Iterator 接口,那就会导致集合对象中包含当前迭代位置的数据(指针)。
当集合在不同方法间被传递时,由于当前迭代位置不可预知,那么 next() 方法的结果也就会变成不可预知。 除非再为 Iterator 接口添加一个 reset() 方法,用来重置当前迭代位置。 但是即使这样做的话,Collection 也只能同时存在一个当前迭代位置。
而集合框架实现了 Iterable 接口,每次调用都会返回一个从头开始计数的迭代器,这样多个迭代器是互不干扰的。
所以,基于上面的原因,集合框架实现的是 Iterable 接口,而不是直接实现 Iterator 接口。
八、编写自定义的 Iterator
有的时候,我们需要要创建一个自定义的 Iterator 接口。
通过 Iterator 接口的源码,我们知道:要创建自定义 Iterator,我们最少需要实现 .hasNext() 和 .next() 方法。
CustomList.java :
import java.util.Iterator;
import java.util.List;
import java.util.NoSuchElementException;
public class CustomList<T> implements Iterable<T> {
private List<T> list;
CustomList(List<T> list) {
this.list = list;
}
public Iterator<T> iterator() {
return new EvenIterator<T>();
}
private class EvenIterator<T> implements Iterator<T> {
int size = list.size();
int currentPointer = 0;
public boolean hasNext() {
return (currentPointer < size);
}
public T next() {
if (!hasNext()) {
throw new NoSuchElementException();
}
T val = (T) list.get(currentPointer);
currentPointer += 1;
return val;
}
}
}
Student.java :
public class Student {
private String name;
private int age;
public Student(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "name: " + name + ", age: " + age + ".";
}
}
Main.java :
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
public class Main {
public static void main(String[] args) {
List<Student> list = new ArrayList<>();
list.add(new Student("xiaoming", 22));
list.add(new Student("xiaohgong", 33));
list.add(new Student("xiaobai", 34));
list.add(new Student("xiaohuang", 48));
CustomList<Student> myList = new CustomList<Student>(list);
Iterator<Student> iter = myList.iterator();
while (iter.hasNext()) {
System.out.println(iter.next());
}
}
}
输出结果为:
name: xiaoming, age: 22.
name: xiaohgong, age: 33.
name: xiaobai, age: 34.
name: xiaohuang, age: 48.
九、Enumeration 接口
Enumeration 接口也可以用于迭代,其中定义了一些方法,通过这些方法可以枚举(一次获得一个)对象集合中的元素。
public interface Enumeration<E> {
boolean hasMoreElements();
E nextElement();
}
hasMoreElements()方法用于检测Enumeration对象中是否还有元素,有则返回true,否则返回false;nextElement(): 如果Enumeration对象还有元素,该方法用于获取下一个元素。
可以看到,Enumeration 接口的作用与 Iterator 接口类似。但是它只提供了遍历 Vector 和 Hashtable 类型集合元素的枚举功能,不支持元素的移除操作。
看个例子:
import java.util.Enumeration;
import java.util.Vector;
public class Main {
public static void main(String[] args) {
Enumeration<Integer> company;
Vector<Integer> employees = new Vector<Integer>();
// add values to employees
employees.add(1001);
employees.add(2001);
employees.add(3001);
employees.add(4001);
company = employees.elements();
while (company.hasMoreElements()) {
// get elements using nextElement()
System.out.println("Emp ID = " + company.nextElement());
}
}
}
1、Enumeration 接口和 Iterator 接口的区别
下面我们看看两者的区别:
1)函数接口不同
Enumeration只有2个函数接口;通过Enumeration,我们只能读取集合的数据,而不能对数据进行修改;- 而
Iterator接口中还有其他方法,除了能读取集合的数据之外,也能对数据进行删除操作。
2)Iterator 支持 fail-fast 机制,而 Enumeration 不支持
什么是 fail-fast 机制呢?
fail-fast 机制是 Java 集合中的一种错误机制。当多个线程对同一个集合的内容进行操作时,就可能会产生 fail-fast 事件。例如:当某一个线程 A 通过 Iterator 去遍历某集合的过程中,若该集合的内容被其他线程所改变了,那么线程 A 访问集合时,就会抛出 ConcurrentModificationException 异常,产生 fail-fast 事件。
Enumeration 是 JDK 1.0 添加的接口。使用到它的函数包括 Vector、Hashtable 等类,这些类都是 JDK 1.0 中加入的,Enumeration 存在的目的就是为它们提供遍历接口。Enumeration 本身并没有支持同步,而在 Vector、Hashtable 实现 Enumeration 时,添加了同步。
而 Iterator 是 JDK 1.2 才添加的接口,它也是为了 HashMap、ArrayList 等集合提供遍历接口。 Iterator 是支持 fail-fast 机制的,当多个线程对同一个集合的内容进行操作时,就可能会产生 fail-fast 事件。
所以,使用 Iterator 更加安全。
3)性能方面,对于 Vector 和 Hashtable 类型集合来说,Enumeration 的速度比 Iterator 接口快,同时所需的内存也远比 Iterator 低。
我们测试一下:
import java.util.Enumeration;
import java.util.Hashtable;
import java.util.Iterator;
import java.util.Random;
public class IteratorEnumeration {
public static void main(String[] args) {
int val;
Random r = new Random();
Hashtable table = new Hashtable();
for (int i = 0; i < 1000000; i++) {
// 随机获取一个[0,100)之间的数字
val = r.nextInt(100);
table.put(String.valueOf(i), val);
}
// 通过Iterator遍历Hashtable
iterateHashtable(table);
// 通过Enumeration遍历Hashtable
enumHashtable(table);
}
/*
* 通过Iterator遍历Hashtable
*/
private static void iterateHashtable(Hashtable table) {
long startTime = System.currentTimeMillis();
Iterator iter = table.entrySet().iterator();
while (iter.hasNext()) {
iter.next();
}
long endTime = System.currentTimeMillis();
countTime(startTime, endTime);
}
/*
* 通过Enumeration遍历Hashtable
*/
private static void enumHashtable(Hashtable table) {
long startTime = System.currentTimeMillis();
Enumeration enu = table.elements();
while (enu.hasMoreElements()) {
enu.nextElement();
}
long endTime = System.currentTimeMillis();
countTime(startTime, endTime);
}
private static void countTime(long start, long end) {
System.out.println("time: " + (end - start) + "ms");
}
}
