集合(set)
储存多个各不相同的元素。
Redis 的集合以无序的方式储存多个各不相同的元素。
用户可以快㏿地向集合添加元素,或者从集合里面 删除元素,也可以对多个集合进行集合运算操作,比如计算并集、交集和差集。
元素操作
添加元素、删除元素、检查元素是否存在、返回集合的大小,等等。
添加元素
SADD key element [element …]
将一个或多个元素添加到 给定的集合里面,已经存在于集合的元素会自 动被忽略,命令返回新添加到集合的元素数量。
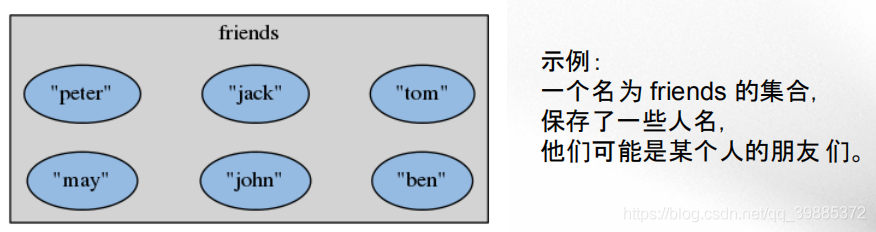
redis> SADD friends "peter"
(integer) 1
redis> SADD friends "jack" "tom" "john"
(integer) 3
redis> SADD friends "may" "tom"
(integer) 1
命令的复杂度为 O(N),N 为成功添加的元素数量。
移除元素
SREM key element [element …]
移除集合中的一个或者多个元素,不存在于集合中的元素会自 动被忽略,命令返回存在并且被移除的元素数量。
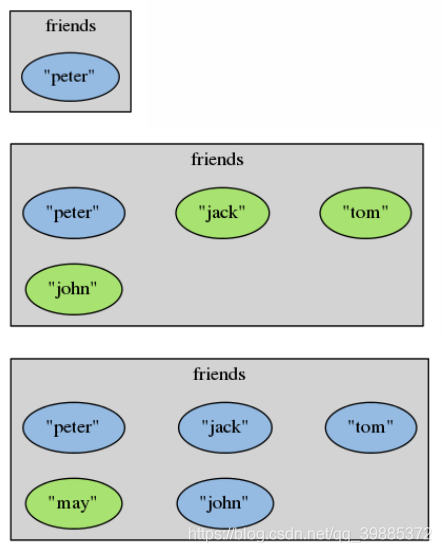
redis> SREM friends “peter”
(integer) 1
redis> SREM friends "tom" "john"
(integer) 2
命令的复杂度为 O(N),N 为被移除元素的数量。
检查给定元素是否存在于集合
SISMEMBER key element
检查给定的元素是否存在于集合,存在的 话返回 1 ;如果元素不存在,或者 给定的键不存在,那么返回 0 。
redis> SISMEMBER friends "peter"
(integer) 1
redis> SISMEMBER friends "li lei"
(integer) 0
redis> SISMEMBER NOT-EXISTS-KEY "element"
(integer) 0
命令的复杂度为 O(1) 。
返回集合的大小
SCARD key
返回集合包含的元素数量(也即是集合的基数)。
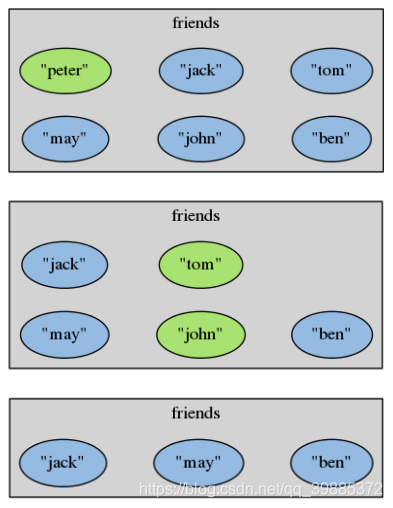
redis> SCARD friends
(integer) 6
redis> SREM friends "peter" "jack" "tom"
(integer) 3
redis> SCARD friends
(integer) 3
因为 Redis 会储存集合的长度,所以命令的复杂度为 O(1) 。
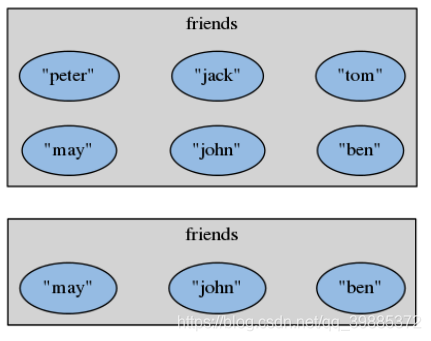
返回集合包含的所有元素
SMEMBERS key
返回集合包含的所有元素。
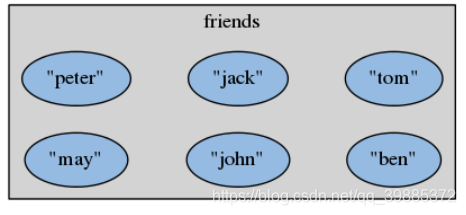
redis> SMEMBERS friends
1) "jack"
2) "peter"
3) "may"
4) "tom"
5) "john"
6) "ben"
命令的复杂度为 O(N) ,N 为集合的大小。
当集合的基数比较大时,执行这个命令有可能会造成服务器阻塞,将来会介绍更好的方式来迭代集合中的元素。
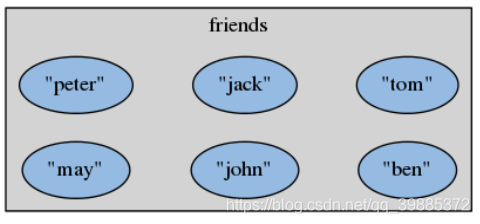
集合的无序性质
redis> SADD friends "peter" "jack" "tom" "john"
"may" "ben"
(integer) 6
redis> SMEMBERS friends
1) "jack"
2) "peter"
3) "may"
4) "tom"
5) "john"
6) "ben"
redis> SADD another-friends "ben" "may" "john"
"tom" "jack" "peter"
(integer) 6
redis> SMEMBERS another-friends
1) "may"
2) "ben"
3) "john"
4) "tom"
5) "jack"
6) "peter"
对于相同的一集元素,同一个集合命令可能会返回不同的 结果。
结论:不要使用集合来储存有序的数据。如果想要储存有序且重复的值,可以使用列表;如果想要储存有序且无重复的值,可以使用之后介绍的有序集合。
示例:赞、喜欢、Like、签到……
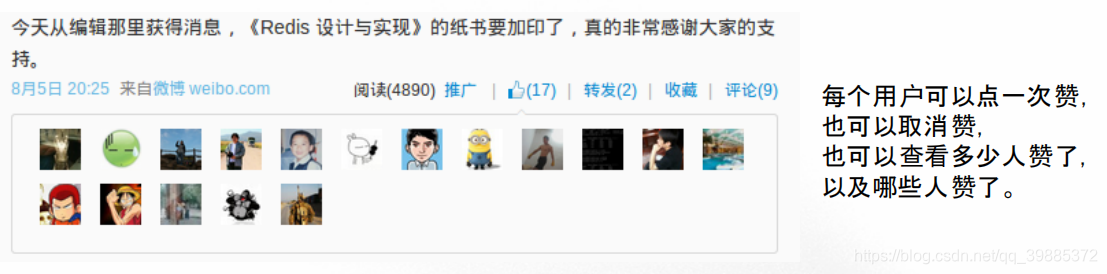
除了微博的赞之外,网上还有很多作用类似的功能,比如豆瓣的 “喜欢”、Facebook 的“Like”、以及一些网站上的“签到”等等。
这些功能实际上都是一种投票功能,比如 “赞”就是投一票,而“取消赞”就是撤销自己的投票。
通过使用 Redis 的集合,我们也可以实现类似的投票功能。
投票功能的 API 及其实现
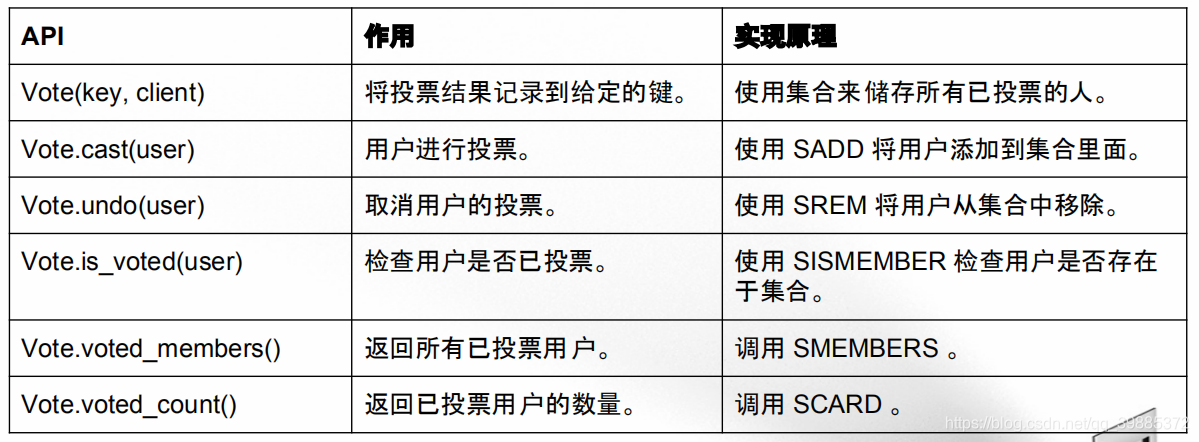
这个投票程序的实现源码可以在 vote.py 看到。
vote.py
# encoding: utf-8
class Vote:
def __init__(self, key, client):
self.key = key
self.client = client
def cast(self, user):
# 因为 SADD 命令会自动忽略已存在的元素
# 所以我们无须在投票之前检查用户是否已经投票
self.client.sadd(self.key, user)
def undo(self, user):
self.client.srem(self.key, user)
def is_voted(self, user):
if self.client.sismember(self.key, user):
return True
else:
return False
def voted_members(self):
return self.client.smembers(self.key)
投票功能的使用示例
like = Vote('weibo::10086::like', client) # 记录 ID 为 10086 的微博的“赞”
like.cast('peter') # 'peter' 赞了这条微博
like.cast('john') # 'john' 赞了这条微博
like.cast('tom') # 'tom' 因为误操作而赞了这条微博
like.undo('tom') # 然后它通过“取消”按钮撤消了“赞”操作
like.is_voted('peter') # 返回 True ,因为 peter 已经赞过了
like.voted_members() # 返回 {'peter', 'john'}
like.voted_count() # 返回 2
示例:打标签功能
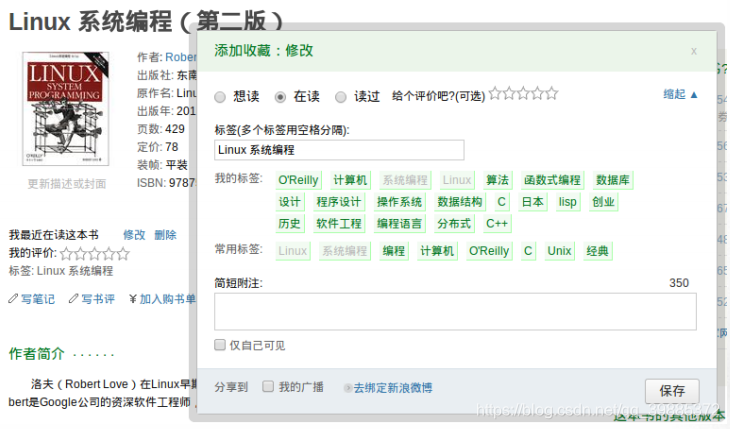
豆瓣允许你在标记一本书的同时,为 这本书添加标签,比如“Linux”、“系统 编程”、“计算机”、“C”、“编程”,等等。使用 Redis 的集合也可以实现这样的加标签功能。
打标签功能的 API 及其实现
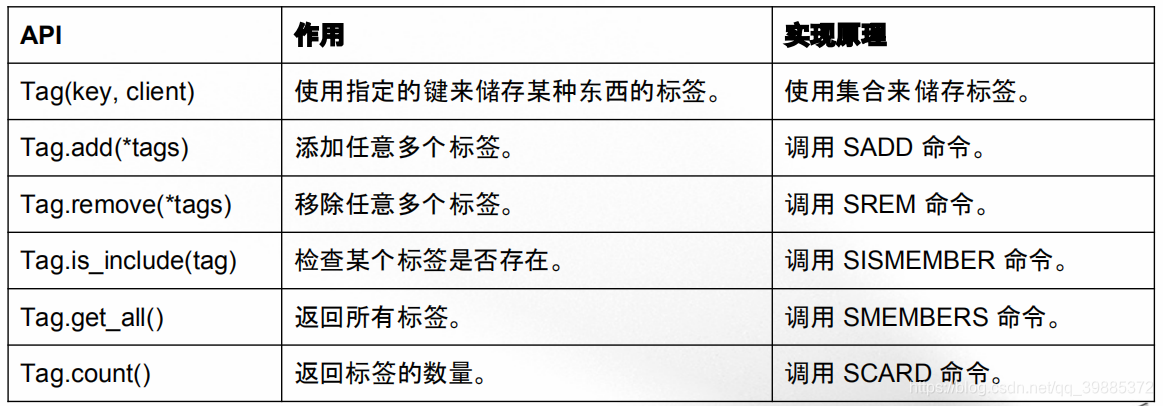
这个打标签程序的实现代码可以在 tag.py 看到。
tag.py
# encoding: utf-8
class Tag:
def __init__(self, key, client):
self.key = key
self.client = client
def add(self, *tags):
self.client.sadd(self.key, *tags)
def remove(self, *tags):
self.client.srem(self.key, *tags)
def is_include(self, tag):
return self.client.sismember(self.key, tag)
def get_all(self):
return self.client.smembers(self.key)
def count(self):
return self.client.scard(self.key)
打标签功能的使用示例
# 创建一个集合键来保存书本的标签
book_tag = Tag('Linux System Programming :: Tag', client)
# 给书本打标签
book_tag.add('linux', 'system programming', 'c', 'windows')
# 获取书本的所有标签
book_tag. get_all()
# 移除指定的标签
book_tag.remove('windows')

从集合里面随机地弹出一个元素
SPOP key
随机地从集合中移除并返回一个元素,复杂度为 O(1) 。
redis> SADD friends "peter" "jack" "tom" "john" "may" "ben"
(integer) 6
redis> SPOP friends
"may"
redis> SMEMBERS friends
1) "tom"
2) "john"
3) "jack"
4) "peter"
5) "ben"
从集合里面随机地返回元素
SRANDMEMBER key [count]
如果没有给定可选的 count 参数,那么命令随机地返回集合中的一个元素。
如果给定了 count 参数,那么:
• 当 count 为正数,并且少于集合基数 时,命令返回一个包含 count 个元素的数组,数组中的每个元素各不相同。如果 count 大于或等于集合基数,那么命令返回整个集合。
• 当 count 为负数时,命令返回一个数组,数组中的元素可能会重复出现多次,而数组的长度为count 的绝对值。 和 SPOP 不同, SRANDMEMBER 不会移除被返回的元素。
命令的复杂度为 O(N),N 为被返回元素的数量。
SRANDMEMBER 的使用示例
redis> SADD friends "peter" "jack" "tom" "john" "may" "ben"
(integer) 1
redis> SRANDMEMBER friends # 随机地返回一个元素
"ben"
redis> SRANDMEMBER friends 3 # 随机地返回三个无重复的元素
1) "john"
2) "jack"
3) "peter"
redis> SRANDMEMBER friends -3 # 随机地返回三个可能有重复的元素
1) "may"
2) "peter"
3) "may"
示例:抽奖系统
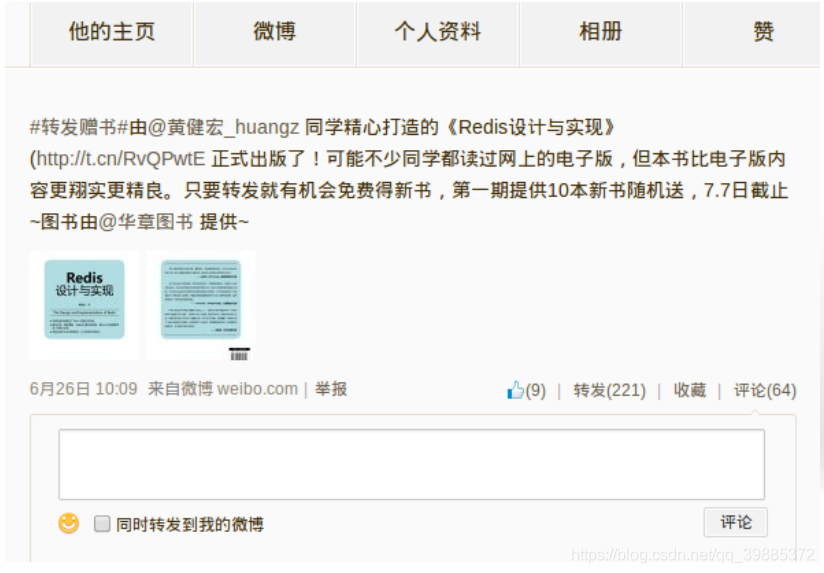
微博上的转发抽奖活动:每个参与者只需要进行转发,就有机会获得奖品。通过将参与抽奖的所有人都添加到一个集合里面,并使用SRANDMEMBER 命令来抽取获奖得主,我们也可以构建一个类似的抽奖功能。
抽奖程序的 API 及其实现

这个抽象程序的实现代码可以在 loterry.py 找到。
lottery.py
# encoding: utf-8
class Lottery:
def __init__(self, key, client):
self.key = key
self.client = client
def add_player(self, *users):
self.client.sadd(self.key, *users)
def get_all_players(self):
return self.client.smembers(self.key)
def player_count(self):
return self.client.scard(self.key)
def draw(self, n):
return self.client.srandmember(self.key, n)
抽奖程序的使用示例
# 创建一个赠送 Redis 书的抽奖活动
book_loterry('loterry::redis_book', client)
# 不断地添加参与者
book_loterry.add_player('peter', 'jack', 'tom', 'may', ..., 'ben')
# 抽出三名幸运的获奖者
book_loterry.draw(3)
集合运算操作
计算并集、交集和差集。
差集运算

交集运算

并集运算
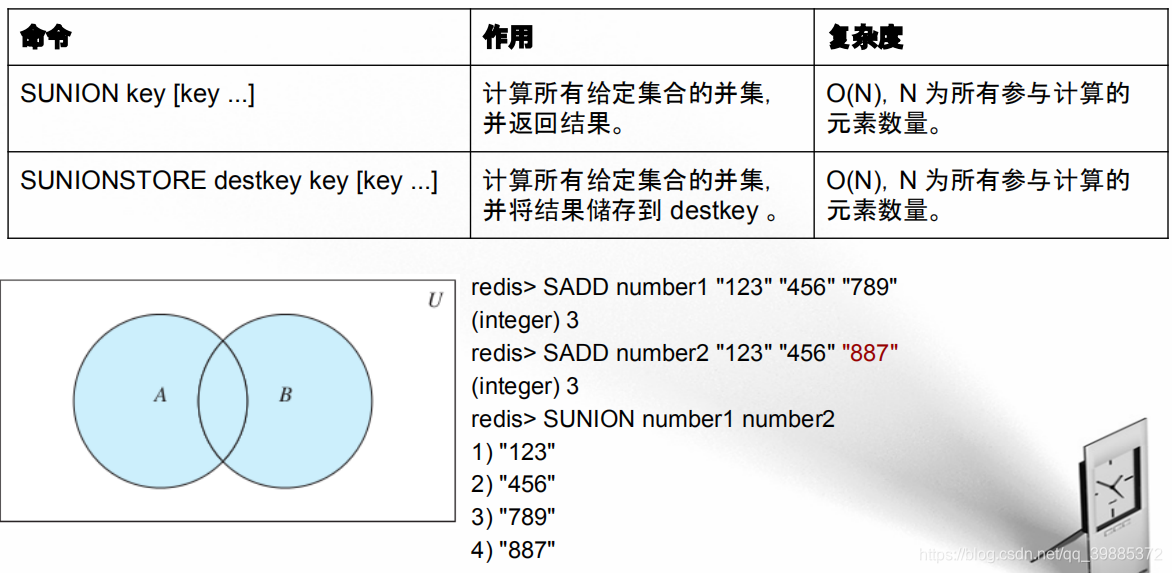
示例:使用集合实现共同关注功能
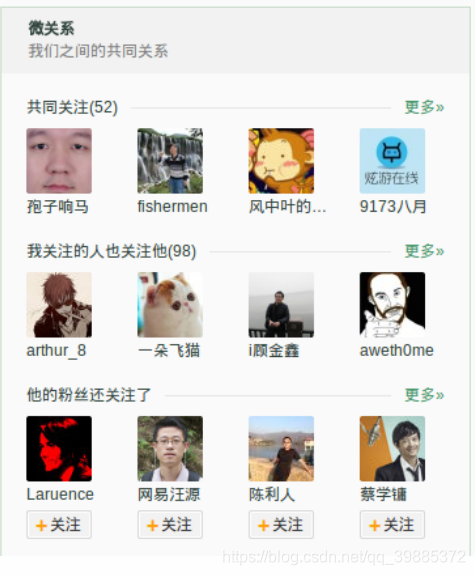
新浪微博的共同关注功能:当用 户访问另一个用户时,该功能会显示出两个用户关注了哪些相同的用户。如果我们把每个用户的关注对象都分别放到一个集合里面的话,那么我们可以使用 SINTER 或者 SINTERSTORE 命令来实现这个共同关注功能。
例如:
peter = {‘john’, ‘jack’, ‘may’}
ben = {‘john’, ‘jack’, ‘tom’}
那么 peter 和 ben 的共同关注为:
SINTER peter ben = {‘john’, ‘jack’}
还可以使用 SINTERSTORE 来避免重复计算。
示例:构建商品筛选功能

京东上的一个手机筛选系统,用户可以根据品牌、价格、网 络、屏幕尺寸等条件,对商品进 行筛选。 对于每个条件的每个选项,我们可以使用一个集合来保存 该选项对应的所有商品,并通过在多个选项之间进行交集计算,从而达到筛选的目的。
示例:构建商品筛选功能
对于品牌条件,我们可以创建这样的集合,比如 apple = { ‘iPhone 5c’, ‘iPhons 5s’, …} ,而 samsung = {‘Galaxy S5’, ‘Galaxy S4’, …} ,诸如此类。 而对于价格条件,我们可以创建这样的集合,比如 price_2900_to_4099 = { ‘Galaxy S5’, ‘Galaxy S4’, …} ,以及 price_uppon_4100 = { ‘iPhone 5c’, ‘iPhone 5S’, …} ,诸如此类。
每当用户添加一个过滤选项时,我们就计算出所有被选中选项的交集,而交集的计算结果就是符合筛 选条件的商品。
示例:构建商品筛选功能
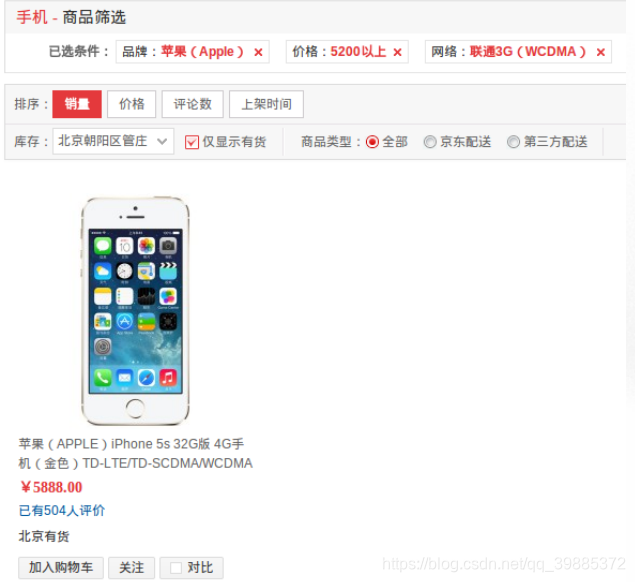
ZINTER apple price_uppon_5200 unicom_wcdma‘iPhone 5s 32G’当然,每次过滤都要计算一次交集的话,㏿度就太慢了,因此我们可以预先计算好,然后把结果储存在一个固定的地方,比如:
ZINTERSTORE
apple&price_uppon_5200&unicom_wcdma
apple price_uppon_5200 unicom_wcdma
SMEMBER
apple&price_uppon_5200&unicom_wcdma
商品筛选功能的实现及其 API
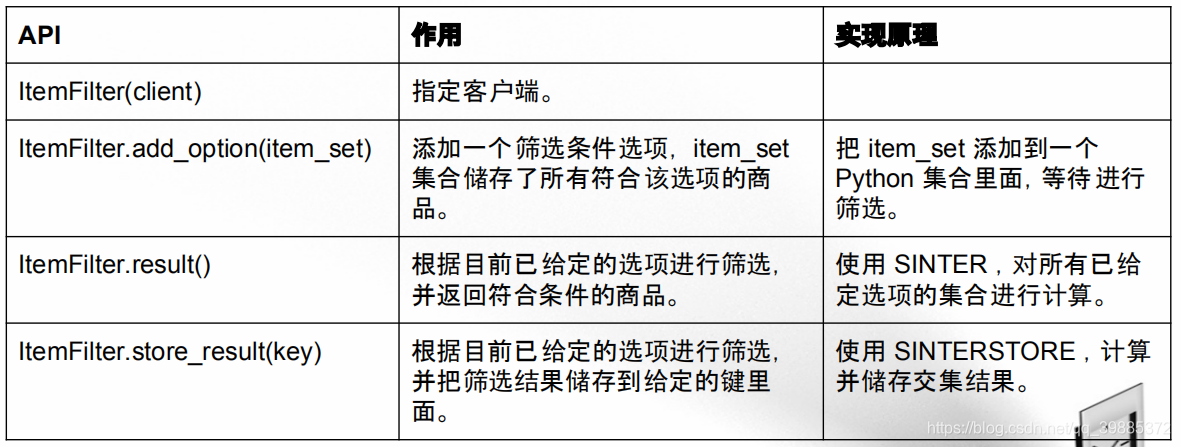
这个商品筛选功能的实现代码可以在 item_filter.py 看到。
#item_filter.py
# encoding: utf-8
class ItemFilter:
def __init__(self, client):
self.client = client
self.options = set()
def add_option(self, item_set):
self.options.add(item_set)
def result(self):
return self.client.sinter(*self.options)
def store_result(self, key):
return self.client.sinterstore(key, *self.options)
商品筛选功能的使用示例
# 创建一个筛选器
filter = ItemFilter(client)
# 只保留 Apple 公司的产品
filter.add_option(apple_product_set)
filter.result()
# 只保留 Apple 公司生产,并且售价 5200 块以上的商品
filter.add_option(price_uppon_5200_product_set)
filter.result()
# 储存起 Apple 公司生产的、售价 5200 块以上并且支持联通 WCDMA 网络的商品
filter.add_option(unicom_wcdma_product_set)
filter.store_result('apple&price_uppon_5200&unicom_wcdma')
复习
集合可以以无序的方式 储存多个各不相同的元素,并且可以 执行添加元素、删除元素、获取所有元素等操作,以及交集、并集、差集等集合运算。

