memcached是怎么工作的?
当查询数据时,客户端首先(参考节点列表)计算出入参key的哈希值(阶段一哈希),找到对应节点;然后memcached节点通过一个内部的哈希算法(阶段二哈希),查找真正的数据(item)。
举个列子,假设有3个客户端1, 2, 3,3台memcached A, B, C:
Client 1想把数据”barbaz”以key “foo”存储。Client 1首先参考节点列表(A, B, C),计算key “foo”的哈希值,假设memcached B被选中。接着,Client 1直接connect到memcached B,通过key “foo”把数据”barbaz”存储进去。 Client 2使用与Client 1相同的客户端库(意味着阶段一的哈希算法相同),也拥有同样的memcached列表(A, B, C)。
于是,经过相同的哈希计算(阶段一),Client 2计算出key “foo”在memcached B上,然后它直接请求memcached B,得到数据”barbaz”。
各种客户端在memcached中数据的存储形式是不同的(perl Storable, php serialize, java hibernate, JSON等)。一些客户端实现的哈希算法也不一样。但是,memcached服务器端的行为总是一致的。
最后,从实现的角度看,memcached是一个非阻塞的、基于事件的服务器程序。这种架构可以很好地解决C10K problem ,并具有极佳的可扩展性。
可以参考A Story of Caching ,这篇文章简单解释了客户端与memcached是如何交互的。
memcached缓存的实现原理?
缓存策略
当ms的hash表满了之后,新的插入数据会替代老的数据,更新的策略是LRU(优先删最近最少使用),以及每个kv对的有效时限
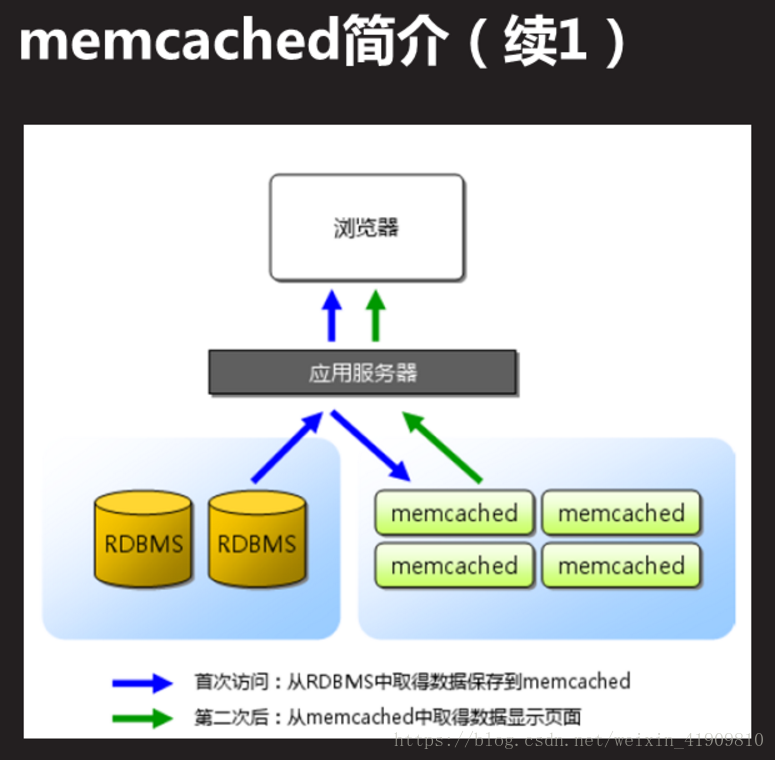
memcached最大的优势是什么?
极佳水平可扩展性,特别是在一个巨大的系统中。由于客户端自己做了一次哈希,那么我们很容易增加大量memcached到集群中。memcached之间没有相互通信,因此不会增加 memcached的负载;没有多播协议,不会网络通信量爆炸(implode)。memcached的集群很好用。内存不够了?增加几台 memcached吧;CPU不够用了?再增加几台吧;
memcached和服务器的local cache(比如PHP的APC、mmap文件等)相比,有什么优缺点?
* local cache面临着严重的内存限制,这一点上面已经提到。
memcached的cache机制是怎样的?
Memcached主要的cache机制是LRU(最近最少用)算法+超时失效。内存满了,就优先删这两种。
memcached如何处理容错的?
不处理!:) 在memcached节点失效的情况下,集群没有必要做任何容错处理。如果发生了节点失效,应对的措施完全取决于用户。节点失效时,下面列出几种方案供您选择:
* 把失效的节点从节点列表中移除。做这个操作千万要小心!在默认情况下(余数式哈希算法),客户端添加或移除节点,会导致所有的缓存数据不可用!因为哈希参照的节点列表变化了,大部分key会因为哈希值的改变而被映射到(与原来)不同的节点上。
* 启动热备节点,接管失效节点所占用的IP。这样可以防止哈希紊乱(hashing chaos)。
如何将memcached中item批量导入导出?
您不应该这样做!Memcached是一个非阻塞的服务器。因为量大不是单线程,可能导致memcached暂停或瞬时拒绝服务。向 memcached中批量导入数据往往不是您真正想要的!想象看,如果缓存数据在导出导入之间发生了变化,您就需要处理脏数据了;如果缓存数据在导出导入之间过期了,您又怎么处理这些数据呢?
但是我确实需要把memcached中的item批量导出导入,怎么办??
好吧好吧。如果您需要批量导出导入,最可能的原因一般是重新生成缓存数据需要消耗很长的时间,或者数据库坏了让您饱受痛苦。
memcached是如何做身份验证的?
没有身份认证机制!。memcached的客户端和服务器端之所以是轻量级的,部分原因就是完全没有实现身份验证机制。这样,memcached可以很快地创建新连接,服务器端也无需任何配置。
如果您希望限制访问,您可以使用防火墙
memcached的多线程是什么?如何使用它们?
线程就是定律(threads rule)!在Steven Grimm和Facebook的努力下,memcached 1.2及更高版本拥有了多线程模式。多线程模式允许memcached能够充分利用多个CPU,并在CPU之间共享所有的缓存数据。memcached使用一种简单的锁机制来保证数据更新操作的互斥。相比在同一个物理机器上运行多个memcached实例,这种方式能够更有效地处理multi gets。
如果您的系统负载并不重,也许您不需要启用多线程工作模式。如果您在运行一个拥有大规模硬件的、庞大的网站,您将会看到多线程的好处。
简单地总结一下:命令解析(memcached在这里花了大部分时间)可以运行在多线程模式下。memcached内部对数据的操作是基于很多全局锁的(因此这部分工作不是多线程的)。未来对多线程模式的改进,将移除大量的全局锁,提高memcached在负载极高的场景下的性能。
memcached能接受的key的最大长度是多少? memcached对item的过期时间有什么限制?
key的最大长度是250个字符。过期时间最大可以达到30天。memcached把传入的过期时间(时间段)解释成时间点后,一旦到了这个时间点,memcached就把item置为失效状态。这是一个简单但obscure的机制。
memcached最大能存储多大的单个item? 为什么单个item的大小被限制在1M byte之内?
一、答:1MB。如果你的数据大于1MB,可以考虑在客户端压缩或拆分到多个key中。
二、答:简单的回答:因为内存分配器的算法就是这样的。
详细的回答:Memcached的内存存储引擎(引擎将来可插拔…),使用slabs来管理内存。内
memcached是原子的吗?
单个命令是完全原子的,但是没有锁的概念,并发更新应用是不安全的。
常用命令需注意点?
-
et与add在key不存在时效果一致,add在key存在时不会成功。
-
set与replace在key存在时效果一致,replace在key不存在不会成功。
