1.什么是索引
索引就是按用户任意指定的字段对数据进行排序的一种数据结构
2.为什么需要索引?
索引是数据表种一个或者多个列进行排序的数据结构
索引能够大幅提升检索速度
创建、更新索引本身也会耗费空间和时间
3.创建索引类型
普通类型(CREATE INDEX)
唯一索引,索引列的值必须唯一(CREATE UNIQUE INDEX)
多列索引
主键索引(PRIMARY KEY),一个表只能有一个
全文索引(FULLTEXT INDEX),InnoDB 不支持
4.什么时候创建索引
经常用作查询条件的字段
经常用作表连接的字段
经常出现在 order by,group by 之后的字段
5.创建索引有哪些需要注意的?
非空字段 NOT NULL,Mysql 很难对空值作查询优化
区分度高,离散度大,作为索引的字段值尽量不要有大量相同值
索引的长度不要太长(比较耗费时间)
6.索引什么时候失效?
模糊匹配、类型隐转、最左匹配
以 % 开头的 LIKE 语法,模糊搜索
出现隐式类型转换
没有满足最左前缀原则
7. 什么是最左前缀原则
例如对于下面这一张表
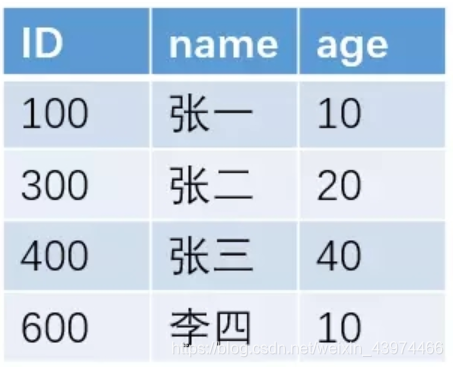
如果我们按照 name 字段来建立索引的话,采用B+树的结构,大概的索引结构如下
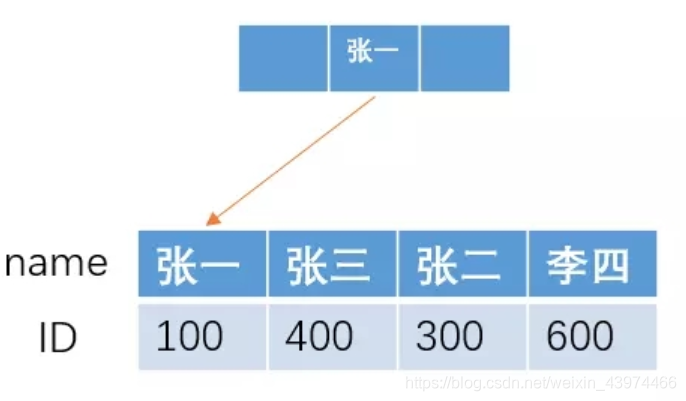
如果我们要进行模糊查找,查找name 以“张"开头的所有人的ID,即 sql 语句为
select ID from table where name like '张%'
由于在B+树结构的索引中,索引项是按照索引定义里面出现的字段顺序排序 的,索引在查找的时候,可以快速定位到 ID 为 100的张一,然后直接向右遍历所有张开头的人,直到条件不满足为止。
也就是说,我们找到第一个满足条件的人之后,直接向右遍历就可以了,由于索引是有序的,所有满足条件的人都会聚集在一起。
而这种定位到最左边,然后向右遍历寻找,就是我们所说的最左前缀原则。
8.索引保存方法
主要用B+树数据结构.
Innodb引擎 保存 行和页, 内存查询
局部原理 : 从磁盘取出,放到内存
Innodb一页有16kb;
页目录,通过数组实现
查询 : 二分法
从左到右 : 全表扫描
从上到下 : 索引扫描
分页: limit 取前面500条数据,比后面的500条数据快
取后面的500条数据:查询前面500条的最大ID,再最左前缀原则
9. 为什么用 B+ 树做索引而不用哈希表做索引?
1、哈希表是把索引字段映射成对应的哈希码然后再存放在对应的位置,这样的话,如果我们要进行模糊查找的话,显然哈希表这种结构是不支持的,只能遍历这个表。而B+树则可以通过最左前缀原则快速找到对应的数据。
2、如果我们要进行范围查找,例如查找ID为100 ~ 400的人,哈希表同样不支持,只能遍历全表。
3、索引字段通过哈希映射成哈希码,如果很多字段都刚好映射到相同值的哈希码的话,那么形成的索引结构将会是一条很长的链表,这样的话,查找的时间就会大大增加。
10. 主键索引和非主键索引有什么区别?
例如对于下面这个表,且ID是主键。
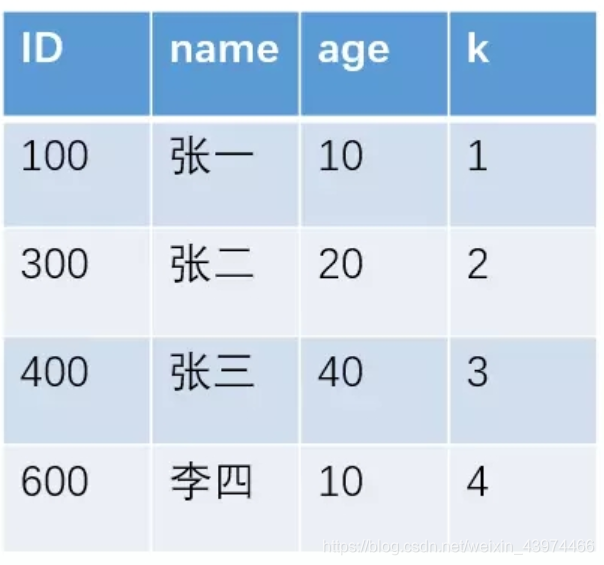 主键索引和非主键索引的示意图如下:
主键索引和非主键索引的示意图如下:
 其中R代表一整行的值。
其中R代表一整行的值。
从图中不难看出,主键索引和非主键索引的区别是:非主键索引的叶子节点存放的是主键的值,而主键索引的叶子节点存放的是整行数据,其中非主键索引也被称为二级索引,而主键索引也被称为聚簇索引。
根据这两种结构我们来进行下查询,看看他们在查询上有什么区别。
1、如果查询语句是 select * from table where ID = 100,即主键查询的方式,则只需要搜索 ID 这棵 B+树。
2、如果查询语句是 select * from table where k = 1,即非主键的查询方式,则先搜索k索引树,得到ID=100,再到ID索引树搜索一次,这个过程也被称为回表。
