MySQL系列文章
MySQL(一)基本架构、SQL语句操作、试图
MySQL(二)索引原理以及优化
MySQL(三)SQL优化、Buffer pool、Change buffer
MySQL(四)事务原理及分析
MySQL(五)缓存策略
MySQL(六)主从复制
数据库三范式
文章目录
前言
MySQL数据库是用来保存海量数据的,但是海量数据涉及到一个快速查找问题,怎么从海量数据查找到我想要的数据呢?
常见的办法就是将表中每一列类比成索引来定位我是这一列哪一个单元。那我定位表中这一列的某一个数据,就通过索引去查找就好了。
但肯定不能一个一个去遍历,这里就涉及到MySQL 数据库的数据结构组成。用一些数据结构可以加快查找效率。
而MySQL常用的innodb存储引擎采用的是B+树作为索引的数据结构。
为什么选B+树?
简单说一下有哪些便于查找的数据结构和不足:
- 有序数组+二分法:数组不便于增删节点,增删节点需变化节点之后的数据。
- 二分查找树:解决了增删节点的问题,但是可能会退化成链表。
- 平衡二叉树:解决了退化链表的问题,但是数据多了,树的高度会很高(二叉树的每多一层就需要多一次IO磁盘操作)。且插入删除数据自旋节点的次数会比较多。
- 红黑树:不是完全平衡,但可以减少增删节点的自旋次数。同样有树的高度会很高的问题。
- B树:解决了树高度问题,但是每个节点包含了索引和数据,IO操作会占用内存资源。并且范围查找效率也不是很高。
最后来到了B+树:解决了范围查找,IO磁盘次数这些问题。
详细内容参考https://www.xiaolincoding.com/mysql/index/why_index_chose_bpuls_tree.html
一、索引
索引存储结构分类:聚集索引和非聚集索引;
刚刚提到MySQL 用的B+树存储索引。聚集索引和非聚集索引都是用各自的B+树存储的。
区别在于:
- 聚集索引的叶子节点存放的是实际数据,所有完整的用户记录都存放在聚集索引的叶子节点。
- 非聚集索引的叶子节点存放的是主键值(就是聚集索引值),而不是实际数据。
例子:S0001是辅助索引,生成的B+树的叶子节点存的是主键的值,通过辅助索引查数据时需要先找到主键,再在主键的表中找到相应的数据。
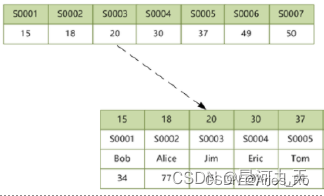
详细内容参考:https://juejin.cn/post/7001094401858469918
索引除了结构分类,还可以通过使用特性分类:主键索引、唯一索引、普通索引、组合索引、以及全文索引(elasticsearch);
主键索引
非空唯一索引,一个表只有一个主键索引;在 innodb 中,主键索引的 B+ 树包含表数据信息;
PRIMARY KEY(key)
唯一索引
不可以出现相同的值,可以有 NULL 值;
UNIQUE(key)
普通索引
允许出现相同的索引内容;
INDEX(key)
-- OR
KEY(key[,...])
组合索引
对表上的多个列进行索引
INDEX idx(key1,key2[,...]);
UNIQUE(key1,key2[,...]);
PRIMARY KEY(key1,key2[,...]);
使用组合索引可以减少开销,因为分开的话,一个索引需要建立一个B+树,而组合索引只需要一颗B+树。
全文索引
将存储在数据库当中的整本书和整篇文章中的任意内容信息查找出来的技术;关键词 FULLTEXT;
在短字符串中用 LIKE % ;在全文索引中用 match 和against ;
FULLTEXT(KEY)
SELECT * FROM article WHERE MATCH(title,content)AGAIN('查询字符串');
————————————————
上述只有主键索引是聚集索引,其他索引都是辅助索引;例如唯一索引,普通索引等。
二、主键选择
innodb 中表是索引组织表,每张表有且仅有一个主键,可以设置,也可以让系统自动生成;
如果显示设置 PRIMARY KEY ,则该设置的 key 为该表的主键;
如果没有显示设置,则从非空唯一索引中选择;
只有一个非空唯一索引,则选择该索引为主键;
有多个非空唯一索引,则选择声明的第一个为主键;
没有非空唯一索引,则自动生成一个 6 字节的 _rowid 作为主键;
约束
为了实现数据的完整性,对于 innodb,提供了以下几种约束,primary key,unique key,foreign key,default,not null;
外键约束
外键用来关联两个表,来保证参照完整性;MyISAM 存储引擎本身并不支持外键,只起到注释作用;而 innodb 完整支持外键,并具备事务性;
create table parent (
id int not null,
primary key(id)
) engine=innodb;
create table child (
id int,
parent_id int,
foreign key(parent_id) references parent(id)
ON DELETE CASCADE ON UPDATE CASCADE
) engine=innodb;
-- 被引用的表为父表,引用的表称为子表;
-- 外键定义时,可以设置行为 ON DELETE 和 ON UPDATE,行
为发生时的操作可选择:
-- CASCADE 子表做同样的行为
-- SET NULL 更新子表相应字段为 NULL
-- NO ACTION 父类做相应行为报错
-- RESTRICT 同 NO ACTION
INSERT INTO parent VALUES (1);
INSERT INTO parent VALUES (2);
INSERT INTO child VALUES (10, 1);
INSERT INTO child VALUES (20, 2);
DELETE FROM parent WHERE id = 1;
约束与索引的区别
创建主键索引或者唯一索引的时候同时创建了相应的约束;
约束是逻辑上的概念;
索引是一个数据结构既包含逻辑的概念也包含物理的存储方式;
索引存储
innodb 由段、区、页组成;段分为数据段、索引段、回滚段等;区大小为 1 MB(一个区由 64 个连续页构成);页的默认值为 16k;页为逻辑页,磁盘物理页大小一般为 4K 或者 8K;为了保证区中的页的连续,存储引擎一般一次从磁盘中申请4~5 个页;
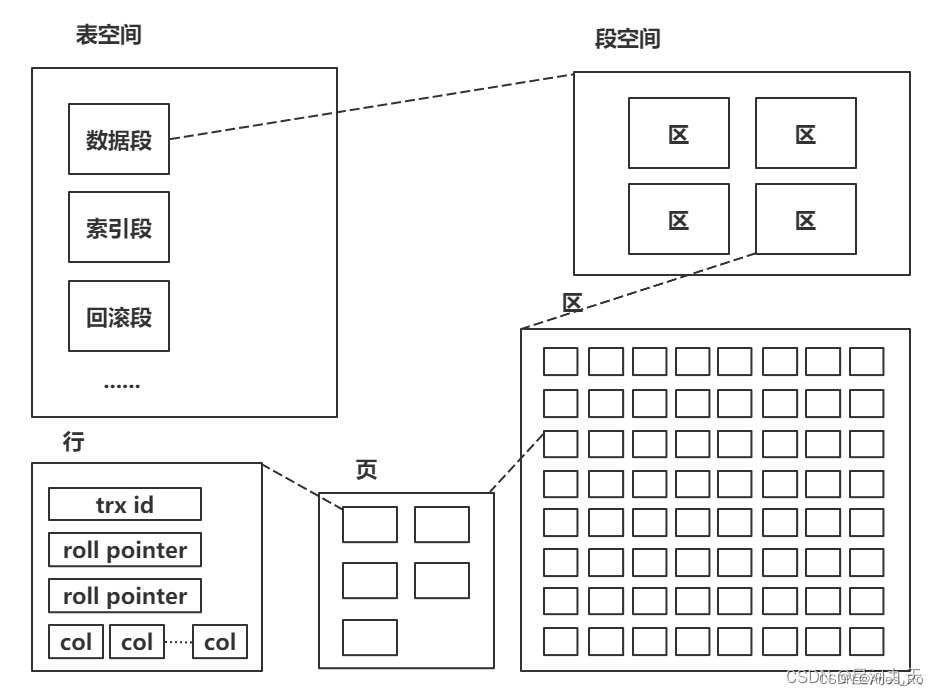
页
页是 innodb 磁盘管理的最小单位;默认16K,可通过innodb_page_size 参数来修改;
特点:
B+ 树的一个节点的大小就是该页的值;
主键B+树非叶子节点中的页数据存储的是索引,叶子节点存储的是索引和表的行数据。
自增id
超过类型最大值会报错;
big int 类型 的范围:(-263 ,263-1)
假设采用 big int 类型的话,1 秒插入 1 亿条数据,大概需要 5849 年才会用完索引;
最左匹配原则
对于组合索引,从左到右依次匹配,遇到 > < between like就停止匹配会采用遍历查询。索引组合索引时尽量避免使用范围查询。
覆盖索引
从非聚集索引中就能找到数据,而不需通过聚集索引查找;利用非聚集索引树高度一般低于聚集索引树;较少磁盘 IO;所以用select时,尽量避免使用 select * from …。应该将所需要的列都标明。
索引下推
为了减少回表次数,提升查询效率;在 MySQL 5.6 的版本开始推出;
MySQL 架构分为 server 层和存储引擎层;
没有索引下推机制之前,server 层向存储引擎层请求数据,在server 层根据索引条件判断进行数据过滤;
有索引下推机制之后,将部分索引条件判断下推到存储引擎中过滤数据;最终由存储引擎将数据汇总返回给 server 层;
索引失效
- select … where A and B 若 A 和 B 中有一个不包含索引,则索引失效;
- 索引字段参与运算,则索引失效;例如:select * from student where id-1 = 1;
- 索引字段发生隐式转换,则索引失效;例如:将列隐式转换为某个类型,实际等价于在索引列上作用了隐式转换函数;例如查询字符串时没用引号括起来,导致转换成int类型。
- LIKE 模糊查询,通配符 % 开头,则索引失效;例如: select * from user where name like ‘%Mark’;
- 组合索引中,没使用第一列索引,索引失效;
- 查询条件中有or;例如SELECT * FROM student where id =1 or birthday = “2021-12-23”;
索引失效就会使用全表查询,也就是遍历查询,非常耗时。
索引原则
- 查询频次较高且数据量大的表建立索引;索引选择使用频次较高,过滤效果好的列或者组合;
- 使用短索引;节点包含的信息多,较少磁盘 IO 操作;比如:smallint , tinyint ;
- 对于很长的动态字符串,考虑使用前缀索引;
- 对于组合索引,考虑最左侧匹配原则和覆盖索引;
- 尽量选择区分度高的列作为索引;该列的值相同的越少越好;
- 尽量扩展索引,在现有索引的基础上,添加复合索引;最多6个索引。
- 不要 select * ; 尽量只列出需要的列字段;方便使用覆盖索引;
- 索引列,列尽量设置为非空;
- 可选:开启自适应 hash 索引或者调整 change buffer;
后记
索引大大提高了查询速度,同时却会降低更新表的速度,比如对表进行INSERT,UPDATE和DELETE。因为更新表时,Mysql不仅要保存数据,还要保存一下索引文件,建立索引会占用磁盘空间的索引文件。