1.背景介绍
出租车多按里程或时间收费,但进入21世纪,电话预约叫车量逐年增加。每天早晚高峰、雨雪等恶劣天气以及长假的某些时段,各大出租汽车调度中心的预约叫车业务供不应求。随着出租车业务的不断提升,相关部门也制定了相应的政策来调价。比如北京2013年6月6日北京市发改委在官网上公布北京市出租车最终的价格调整方案。2013年6月10日起起步价涨至13元。因此综合来看,出租车票价不仅受里程和时间影响,还可能受恶劣天气、早晚高峰、乘车人数等多方面因素影响。
本文的目的就是根据纽约市的出租车的相关数据对其票价进行建模和预测。
数据来源:kaggle比赛数据
2.数据集介绍
本文所利用的数据集是kaggle的比赛数据集,根据给定的接送地点,预测纽约市出租车的票价(包括通行费)。 提供的数据集字段主要有:‘key’, ‘fare_amount’, ‘pickup_datetime’, ‘pickup_longitude’, ‘pickup_latitude’, ‘dropoff_longitude’, ‘dropoff_latitude’, ‘passenger_count’。其中’fare_amount’是票价,即因变量,我们要预测的变量。'key’为每条数据的ID, 'pickup_datetime’为接到乘客的时间点, 'pickup_longitude’为接到乘客的经度, 'pickup_latitude’为接到乘客的纬度, 'dropoff_longitude’为送达乘客的经度, 'dropoff_latitude’为送达乘客的纬度, 'passenger_count’为乘客的人数。
事实证明,如果仅基于两点之间的距离来获得基本估计,这将导致$ 5- $ 8的误差。因此本文利用所得的数据集进行缺失值处理、特征提取和选择、建模等步骤,最后利用测试集来预测票价。
3.数据清理
3.1数据概览
首先检查训练集和测试集的大小。可以看出训练集一共1000000条数据,测试集一共9914条数据。
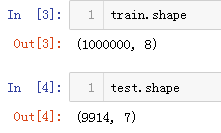
下面查看前几行数据。可以看到时间数据景区到了时分秒,这是数据我们后面进行特征工程的时候可以应用。
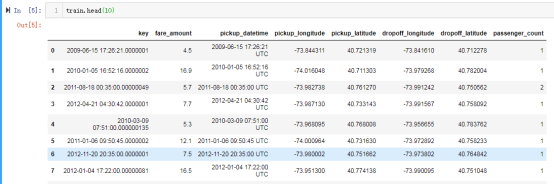
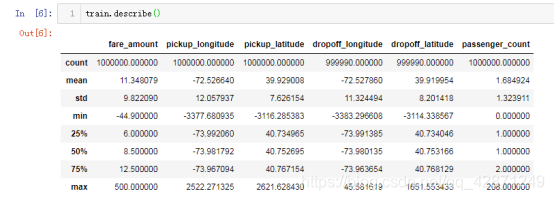
接下来看一下数据的描述,可以看出部分数据有缺失值,后面会进行处理。通过最大值最小值也可以看出,部分字段数据有异常值,需要进行处理。
3.2缺失值处理
首先检查训练数据和测试数据的缺失值。如下图,可以看出训练集有10条缺失值,测试集没有缺失值。


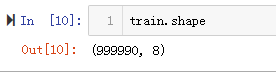
由于缺失值占比非常小,这里直接将缺失值删除。删除缺失值之后还剩下999990条数据。
3.3异常值处理
接下来检查因变量。可以看出最小值为负数,这是不合理。计算’fare_amount’小于0的,一共有38个,全部将其删除。
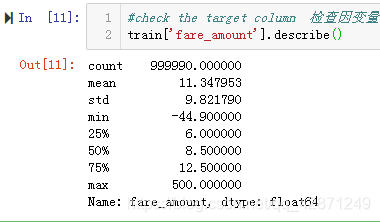
下面查看坐车人数。max是208位乘客。 假设公交车是纽约市的“出租车”,我们认为公交车不能载208名乘客。
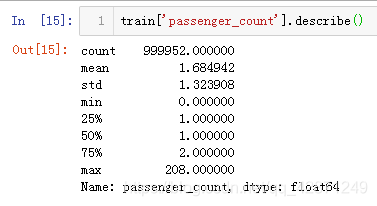
下面让我们看看这个领域的分布,坐车人数大于6的只有一条记录, 这绝对是一个离群值。让我们删除它就好了。

将其删除之后,现在更加整洁,最多可容纳6位乘客。这是说出租车是SUV 。
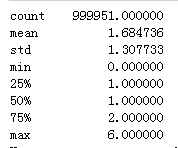
接下来,让我们探索经度和纬度。

快速谷歌搜索可以知道:纬度范围是-90至90,经度的范围是-180至180。上面的描述明显地显示了一些异常值。 让我们删除它们。
删除之后的训练集还有999928条记录。

3.4相关字段的类型转换
检查每一列的数据类型:
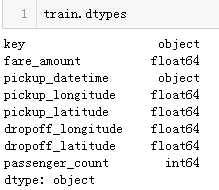
key和pickup_datetime似乎是对象格式的datetime列。我们将它们转换为日期时间。
4. 探索性数据分析(EDA)
4.1字段提取
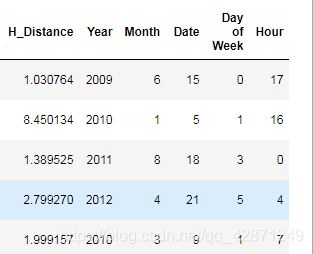
首先,让我们将接到乘客的日期时间字段“ pickup_datetime”拆分为年、月、日期、小时、星期几。
下面再计算接到乘客的地点和乘客下车地点的距离。利用Haversine公式算得。Haversine公式表示给出纬度和经度时,我们可以计算球体中的距离(网址https://en.wikipedia.org/wiki/Haversine_formula )Haversine(θ)=sin²(θ/ 2)。利用纬度经度,地球半径R(平均半径= 6,371 km)来计算。得到结果如图所示。
看一下我们上面重新创建的列:
4.2乘客人数
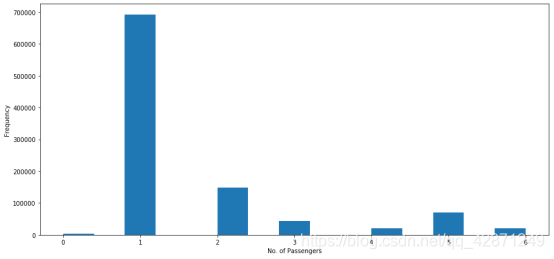
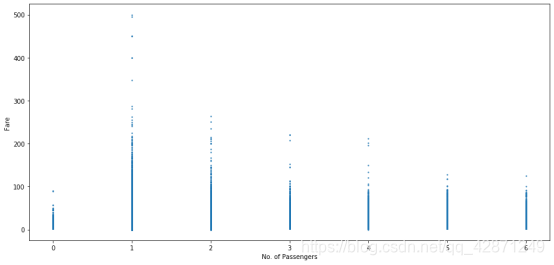
下面的两个图表中,第一个图为乘车人数分布的条形图,第二个图横坐标为乘客车人数,纵坐标为票价。我们可以看到单身乘客是最常出行的旅客,而票价最高的似乎也来自仅载有一名乘客的出租车。
4.3取车的日期和时间
下面的图横坐标为日期,纵坐标为票价。可以看出整个月的票价大部分似乎是统一的,最高票价是在12号。
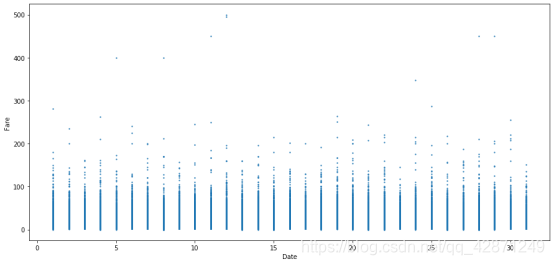
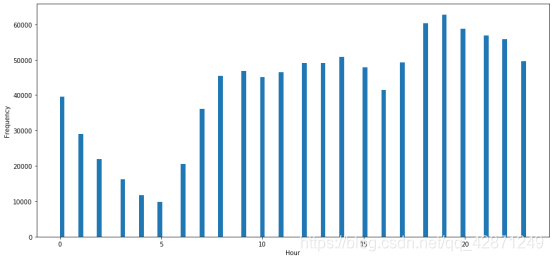
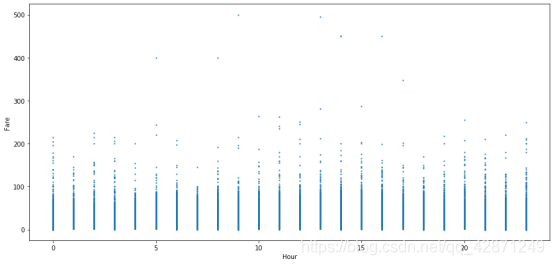
从下面的两个图表中,第一个图为接到乘客的时间分布图,第二个图横坐标为时间,纵坐标为票价。一天中的时间肯定起着重要的作用。我们可以看到, 乘坐出租车的频率似乎在上午5点最低,在下午7点最高。但是,票价似乎在5AM和10AM,以及2PM至4PM偏高。 也许住在偏远地方的人喜欢早点出行,以避免交通高峰时间。
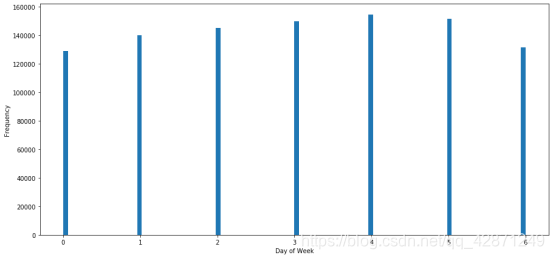
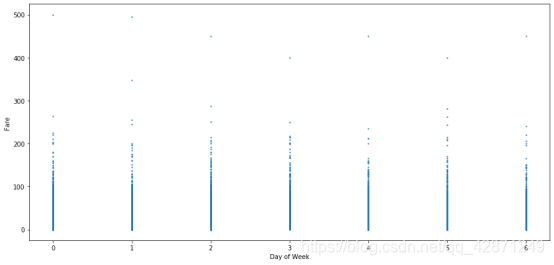
4.4星期几与票价
从下面的两个图表中,第一个图为一周中每日的频数分布图,第二个图横坐标为星期几,纵坐标为票价。我们可以看到,星期几对出租车的乘车次数影响不大。
最高票价似乎在星期日和星期一,而最低票价在星期三和星期五。也许人们在周日和周一旅行很远(拜访家人并返回家中),因此票价偏高。人们只是想在忙碌的一周后的星期五更多愿意呆在家里,或者从附近喝一杯。
4.5距离
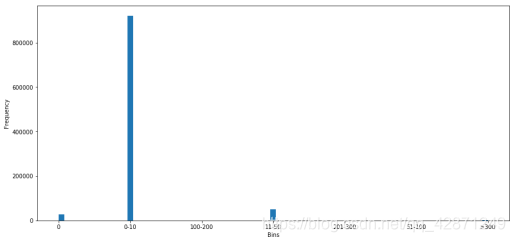
距离很明显会极大地影响票价。我们将其可视化。首先,让我们检查使用Haversine公式计算的距离的频率。 我们通过创建bin(0-10公里,10-20公里等)并检查是否存在异常值。
(1)删除缺失值
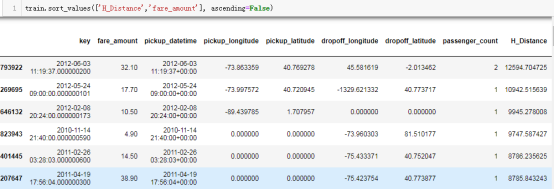
通过下图可以看出,max距离大于100公里,在纽约,不确定为什么人们会乘出租车行驶100多公里。由于bin100-200公里的数量很多,暂时保留这些数据。这些异常值可能是由于拼写错误或纬度或经度中缺少值。
首先以下字段进行处理:
1.Pickup latitude和pickup longitude为0,但dropoff latitude和longitude不为0,但票价为0。
2.跟第一点相反的亦然,同样删除。
3.Pickup latitude和pickup longitude为0,但dropoff latitude和longitude不为0,但票价不为0。这里,就不得不在训练和测试数据中估算距离值。
(2)处理异常值
检查大于200公里的H_Distance字段,人们不可能在纽约最多行驶200公里以上。
查找距离大于200,票价不等于0的记录。如下图,一共1938行,可以看到,异常高的距离是由于上车或下车坐标不正确或为0。但是,由于所有这些值都有票价,因此不希望将其丢弃,因为它们包含关键数据。相反,我将使用以下公式使用票价计算出的距离值代替初始距离值。这是纽约市出租车票价的一般计算公式,只考虑里程。
distance = (fare_amount - 2.5)/1.56
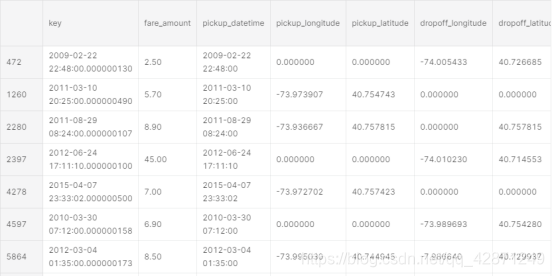
现在我们将检查距离值为0的行。我们可以看到几条距离= 0的行。这可能是由于两个原因:
一、出租车一直等着,乘客最终取消了。这就是为什么上落坐标和下落坐标相同的原因,也许是在等待时间上向乘客收取了费用。二、没有输入拾取和放置坐标。换句话说,这些都是缺失的值。如下图,一共28667行太多,无法删除。我们需要估算这些缺失的值。我们打算用票价和纽约市出租车每公里平均价格来估算缺失的距离值。
通过Google搜索得到:
周一至周五上午6点至晚上8点:$ 2.5基础价格+ $ 1.56 / km
晚上8点至周一至周五上午6点和周六和周日:$$ 3.0基本价格+ $ 1.56 / km
但是,在继续之前,让我们检查以下情况,以将缺失的票价金额和H_Distance推算到火车数据中。
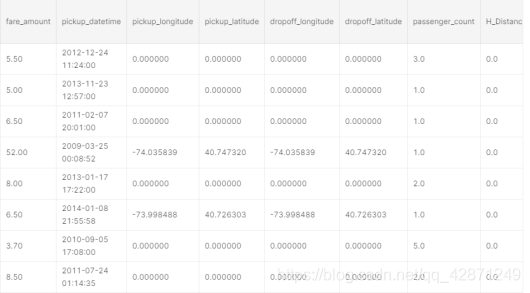
场景1
票价和距离均为0。对于这类,我们将删除它们,因为它们未向我们提供有关数据的任何信息。有4行。有4行对我们无济于事,因为我们不知道估算缺失值的距离或票价。所以我们丢弃它们。
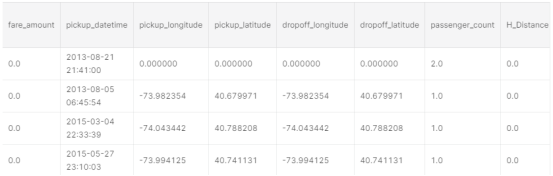
场景2
票价不是0,并且小于基本数量,但距离是0。删除这些行,因为最低限额为2.50美元,并且这些票价都是错误的值。
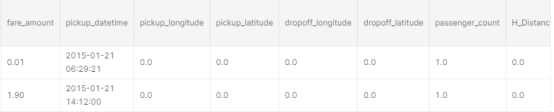
对于有些票价是2.5美元,保留这些。 由于fare_amount不小于2.5(这是基本票价),因此这些值在我看来是合理的。票价是最低票价2.5美元,这可能是因为乘客预订了出租车,但最终取消了支付基本车费。
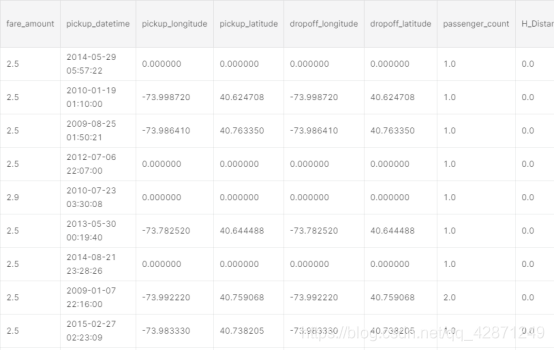
场景3
票价是0,但距离不是0。这些值需要估算。只要有距离,我就可以计算票价。使用以下公式:
票价= 2.5 + 1.56(H_Distance)
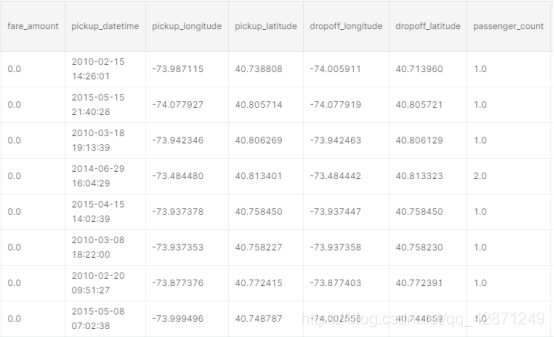
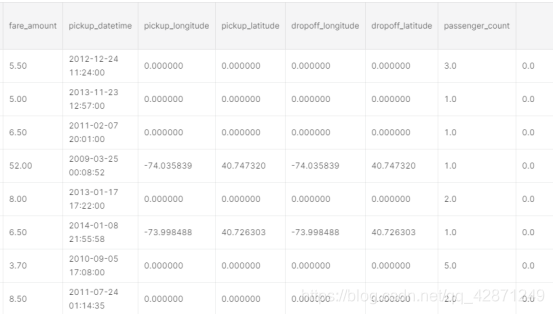
场景4
票价不是0,但距离是0。这些值需要估算。使用我们在平日和周末的出租车基本价格方面的先验知识。我不想估算这1502个值,因为它们是清晰可见的。
distance = (fare_amount - 2.5)/1.56
5. 建模和预测
数据清理完成, 现在拆分x和y变量,然后进行建模。我将使用随机森林、LGBM、XGBoost三种方法分别进行建模和预测。
训练集在删除部分缺失值和异常值之后,还剩下999910条记录。训练集所有的字段:‘pickup_longitude’, ‘pickup_latitude’, ‘dropoff_longitude’, ‘dropoff_latitude’, ‘passenger_count’, ‘H_Distance’, ‘Year’, ‘Month’,‘Date’, ‘Day of Week’, 'Hour’。
下面分别为随机森林、LGBM、XGBoost三种方法预测得到的票价的部分截图。
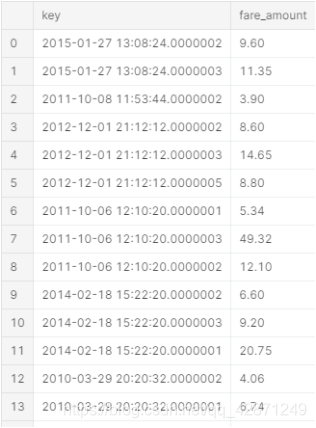
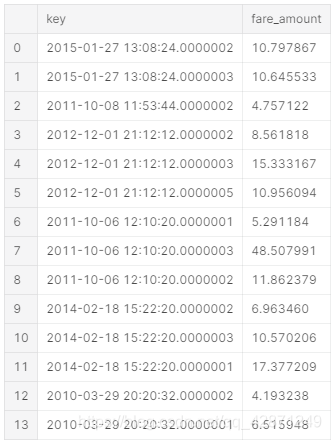
6.结论
在kaggle比赛中,使用随机森林代码,得到了3.39分;使用LGBM,得到了3.37分;而使用XGBoost,我得到了3.61。因此最后是用随机森林做预测的。可见,所建立的模型预测的效果较好,提取的字段确实对票价有影响,也有一定的现实意义。
附录
部分代码,需要完整代码可私信
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import sklearn
import seaborn as sns
import matplotlib.pyplot as plt
import os
print(os.listdir("../kaggle2"))
train = pd.read_csv("./train.csv", nrows = 1000000)
test = pd.read_csv("./test.csv")
train.shape
test.shape
train.head(10)
train.describe()
train.isnull().sum().sort_values(ascending=False)
test.isnull().sum().sort_values(ascending=False)
train.isnull().any(1)
#drop the missing values
train = train.drop(train[train.isnull().any(1)].index, axis = 0)
from collections import Counter
Counter(train['fare_amount']<0)
train = train.drop(train[train['fare_amount']<0].index, axis=0)
train.shape
train['fare_amount'].describe()
train['fare_amount'].sort_values(ascending=False)
train['passenger_count'].describe()
carry 208 passengers! Let' see the distribution of this field
train[train['passenger_count']>6]
train = train.drop(train[train['passenger_count']==208].index, axis = 0)
an SUV :)
train['passenger_count'].describe()
train['pickup_latitude'].describe()
train[train['pickup_latitude']<-90]
train[train['pickup_latitude']>90]
train = train.drop((train[train['pickup_latitude']<-90]).index, axis=0)
train = train.drop((train[train['pickup_latitude']>90]).index, axis=0)
train.shape
train = train.drop((train[train['pickup_longitude']<-180]).index, axis=0)
train = train.drop((train[train['pickup_longitude']>180]).index, axis=0)
train.drop(((train[train['dropoff_latitude']<-90])|(train[train['dropoff_latitude']>90])).index, axis=0)
train = train.drop((train[train['dropoff_latitude']<-90]).index, axis=0)
train = train.drop((train[train['dropoff_latitude']>90]).index, axis=0)
train['key'] = pd.to_datetime(train['key'])
train['pickup_datetime'] = pd.to_datetime(train['pickup_datetime'])
haversine_distance('pickup_latitude', 'pickup_longitude', 'dropoff_latitude', 'dropoff_longitude')
train['H_Distance'].head(10)
data = [train,test]
for i in data:
i['Year'] = i['pickup_datetime'].dt.year
i['Month'] = i['pickup_datetime'].dt.month
i['Date'] = i['pickup_datetime'].dt.day
i['Day of Week'] = i['pickup_datetime'].dt.dayofweek
i['Hour'] = i['pickup_datetime'].dt.hour
plt.figure(figsize=(15,7))
plt.hist(train['passenger_count'], bins=15)
plt.xlabel('No. of Passengers')
plt.ylabel('Frequency')
plt.figure(figsize=(15,7))
plt.scatter(x=train['passenger_count'], y=train['fare_amount'], s=1.5)
plt.xlabel('No. of Passengers')
plt.ylabel('Fare')
travellers, and the highest fare also seems to come from cabs which carry just 1 passenger.
plt.figure(figsize=(15,7))
plt.scatter(x=train['Date'], y=train['fare_amount'], s=1.5)
plt.xlabel('Date')
plt.ylabel('Fare')
plt.figure(figsize=(15,7))
plt.hist(train['Hour'], bins=100)
plt.xlabel('Hour')
plt.ylabel('Frequency')
plt.figure(figsize=(15,7))
plt.scatter(x=train['Hour'], y=train['fare_amount'], s=1.5)
plt.xlabel('Hour')
plt.ylabel('Fare')
plt.figure(figsize=(15,7))
plt.hist(train['Day of Week'], bins=100)
plt.xlabel('Day of Week')
plt.ylabel('Frequency')
plt.figure(figsize=(15,7))
plt.scatter(x=train['Day of Week'], y=train['fare_amount'], s=1.5)
plt.xlabel('Day of Week')
plt.ylabel('Fare')
train.sort_values(['H_Distance','fare_amount'], ascending=False)
bins_0 = train.loc[(train['H_Distance'] == 0), ['H_Distance']]
bins_1 = train.loc[(train['H_Distance'] > 0) & (train['H_Distance'] <= 10),['H_Distance']]
bins_2 = train.loc[(train['H_Distance'] > 10) & (train['H_Distance'] <= 50),['H_Distance']]
bins_3 = train.loc[(train['H_Distance'] > 50) & (train['H_Distance'] <= 100),['H_Distance']]
bins_4 = train.loc[(train['H_Distance'] > 100) & (train['H_Distance'] <= 200),['H_Distance']]
bins_5 = train.loc[(train['H_Distance'] > 200) & (train['H_Distance'] <= 300),['H_Distance']]
bins_6 = train.loc[(train['H_Distance'] > 300),['H_Distance']]
bins_0['bins'] = '0'
bins_1['bins'] = '0-10'
bins_2['bins'] = '11-50'
bins_3['bins'] = '51-100'
bins_4['bins'] = '100-200'
bins_5['bins'] = '201-300'
bins_6['bins'] = '>300'
dist_bins =pd.concat([bins_0,bins_1,bins_2,bins_3,bins_4,bins_5,bins_6])
plt.figure(figsize=(15,7))
plt.hist(dist_bins['bins'], bins=75)
plt.xlabel('Bins')
plt.ylabel('Frequency')
Counter(dist_bins['bins'])
train.loc[((train['pickup_latitude']==0) & (train['pickup_longitude']==0))&((train['dropoff_latitude']!=0) & (train['dropoff_longitude']!=0)) & (train['fare_amount']==0)]
train = train.drop(train.loc[((train['pickup_latitude']==0) & (train['pickup_longitude']==0))&((train['dropoff_latitude']!=0) & (train['dropoff_longitude']!=0)) & (train['fare_amount']==0)].index, axis=0)
test.loc[((test['pickup_latitude']==0) & (test['pickup_longitude']==0))&((test['dropoff_latitude']!=0) & (test['dropoff_longitude']!=0))]
train.loc[((train['pickup_latitude']!=0) & (train['pickup_longitude']!=0))&((train['dropoff_latitude']==0) & (train['dropoff_longitude']==0)) & (train['fare_amount']==0)]
train = train.drop(train.loc[((train['pickup_latitude']!=0) & (train['pickup_longitude']!=0))&((train['dropoff_latitude']==0) & (train['dropoff_longitude']==0)) & (train['fare_amount']==0)].index, axis=0)
test.loc[((test['pickup_latitude']!=0) & (test['pickup_longitude']!=0))&((test['dropoff_latitude']==0) & (test['dropoff_longitude']==0))]
high_distance = train.loc[(train['H_Distance']>200)&(train['fare_amount']!=0)]
)
dataframe
train.update(high_distance)
train.loc[(train['H_Distance']==0) & (train['fare_amount']!=0)]
scenario_4 = train.loc[(train['H_Distance']==0) & (train['fare_amount']!=0)]
scenario_4_sub['H_Distance'] = scenario_4_sub.apply(
lambda row: ((row['fare_amount']-2.50)/1.56), axis=1
)
used while modelling. Features need to extracted from the
#timestamp fields which will later be used as features for modelling.
train = train.drop(['key','pickup_datetime'], axis = 1)
test = test.drop(['key','pickup_datetime'], axis = 1)
x_train = train.iloc[:,train.columns!='fare_amount']
y_train = train['fare_amount'].values
x_test = test
x_train.shape
from sklearn.ensemble import RandomForestRegressor
rf = RandomForestRegressor()
rf.fit(x_train, y_train)
rf_predict = rf.predict(x_test)
submission = pd.read_csv('../input/sample_submission.csv')
submission['fare_amount'] = rf_predict
submission.to_csv('submission_1.csv', index=False)
submission.head(20)
LGBM really lives up to its hype of improving scores. My intital score with just the RF was 3.39 and placed me in the top 20%.
import lightgbm as lgbm
params = {
'boosting_type':'gbdt',
'objective': 'regression',
'nthread': -1,
'verbose': 0,
'num_leaves': 31,
'learning_rate': 0.05,
'max_depth': -1,
'subsample': 0.8,
'subsample_freq': 1,
'colsample_bytree': 0.6,
'reg_aplha': 1,
'reg_lambda': 0.001,
'metric': 'rmse',
'min_split_gain': 0.5,
'min_child_weight': 1,
'min_child_samples': 10,
'scale_pos_weight':1
}
pred_test_y = np.zeros(x_test.shape[0])
pred_test_y.shape
train_set = lgbm.Dataset(x_train, y_train, silent=True)
train_set
model = lgbm.train(params, train_set = train_set, num_boost_round=300)
pred_test_y = model.predict(x_test, num_iteration = model.best_iteration)
submission['fare_amount'] = pred_test_y
submission.to_csv('submission_LGB.csv', index=False)
submission.head(20)
import xgboost as xgb
dtrain = xgb.DMatrix(x_train, label=y_train)
dtest = xgb.DMatrix(x_test)
dtrain
params = {'max_depth':7,
'eta':1,
'silent':1,
'objective':'reg:linear',
'eval_metric':'rmse',
'learning_rate':0.05
}
num_rounds = 50
xb = xgb.train(params, dtrain, num_rounds)
y_pred_xgb = xb.predict(dtest)
print(y_pred_xgb)
