锁、事务的隔离级别、事务的并发问题——写好“增删改查”必须知道的MySQL InnoDB相关知识
MySQL InnoDB
MySQL InnoDB是最常用的MySQL数据库引擎,这篇文章以后端程序员的视角对他做一些介绍,不会牵扯实现原理,也不会引入太多名词,免得大家越看越糊涂。
锁的类型
共享锁(SLock)
结论:共享锁就是多个事务对于同一数据可以共享一把锁,都能访问到数据,但是只能读不能修改。SQL语句:SELECT … LOCK IN SHARE MODE
验证:
第一步,我们先开启事务,给id为11的记录加共享锁;

第二步,打开另外一个命令行,执行查询和修改,不管声不声明事务,结论都一样:查询可以成功,修改失败;

第三步,提交第一步中开启的事务,释放共享锁;

第四步,刚才执行失败的update语句再执行一遍,成功执行

排他锁(XLock)
结论:允许事务删除或更新一行数据。排他锁就是不能与其他锁并存,如一个事务获取了一个数据行的排他锁,其他事务就不能再获取该行的锁,包括共享锁和排他锁。获取排他锁的事务是可以对一行数据读取和修改。SQL语句:SELECT … FOR UPDATE
验证:
第一步,开启事务,给id为12的记录加排他锁;
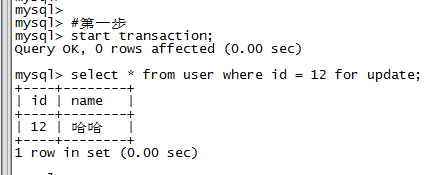
第二步,打开另外一个命令行,执行查询,可以成功;尝试获取共享锁或排他锁,全都失败;update和delete也都不能成功;
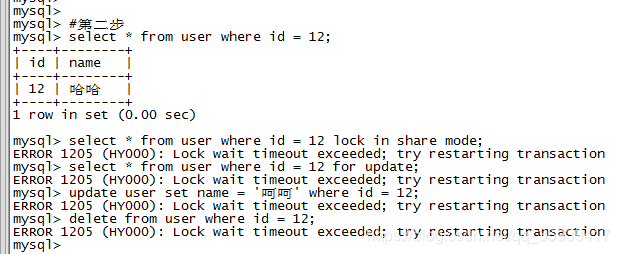
第三步,提交第一步中开启的事务,释放排他锁;
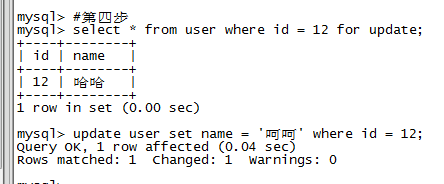
第四步,对id为12的数据加排他锁,可以成功,数据更新当然也是可以成功的。
锁的范围
锁行
结论:当查询条件带主键或索引,且记录存在时,锁住匹配到的那一行
验证:
第一步,开启事务,给id为12的那一行加排他锁,id是主键;
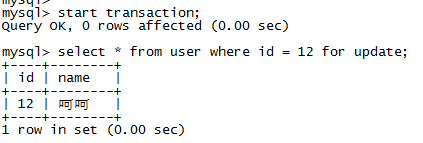
第二步,向user表插入一条数据,可以成功插入;

第三步,提交第一步中开启的事务,释放排他锁;
第四步,开启事务,给name为‘hello’的那一行加排它锁,其中name加了唯一索引;
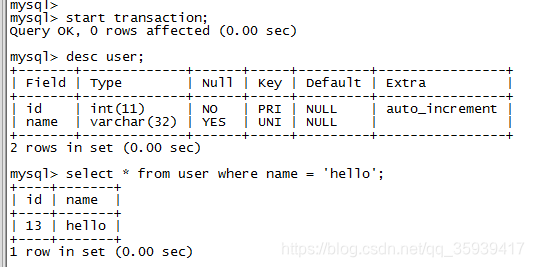
第五步,向user表插入一条数据,可以成功插入;

锁表
结论:当查询条件不是主键或索引,或者主键或索引匹配不到任何数据时,会锁住整张表
验证:
第一步,开启事务,给id为100的行加排他锁,我们可以看到id为100的数据是不存在的;

第二步,开启另外一个命令行,向user表插入一条数据,发现插入失败;

(把id换成索引字段name来验证也可以得到一样的结论)
第三步,给user表新增一个普通字段sex,开启事务,以sex=‘男’为查询条件加共享锁;
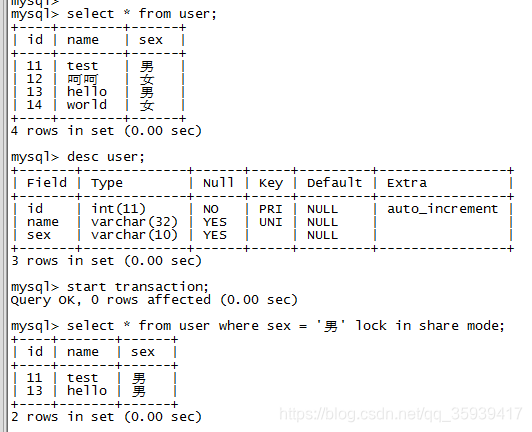
第四步,打开另外一个命令行,将sex=‘女’的记录的sex改为‘中性’,执行失败;
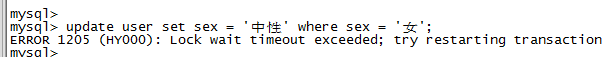
读的类型
一致性非锁定读(快照读)
如果读取的行正在执行delete或update操作,这时读取操作不会因此去等待行上的锁释放,而是去读取一个快照数据。快照数据是指该行之前版本的数据,该实现是通过undo段来完成的,而undo用来在事务中回滚数据。此外,读取快照数据是不需要上锁的,因为没有事务需要对历史的数据进行修改操作。在默认配置下,即事务隔离级别为REPEATABLE READ(可重复读)时,MySQL InnoDB使用一致性非锁定读。
一致性锁定读(当前读)
对于select语句可以加锁来实现一致性的锁定读,可以加共享锁,也可以加排他锁。
事务的隔离级别
READ UNCOMMITTED
浏览访问,俗称“读未提交”。会出现“脏读”;这种隔离级别最低,一般是在理论上存在,很少用到
READ COMMITTED
游标稳定,俗称“读提交”。这种隔离级别高于读未提交;可以避免“脏读”;但会导致“不可重复读”
REPEATABLE READ
俗称“重复读”。这种隔离级别高于“读已提交”;可以实现可重复读,不能避免“幻读”
SERIALIZABLE
隔离,俗称“串行化”。在此事务隔离级别,InnoDB存储引擎会对每个select语句后自动加上lock in share mode,因此对一致性的非锁定读不再予以支持。(ps:有的博客直接就说SERIALIZABLE加的是排他锁,这种说法是错的,试想,如果加的是排他锁,查询也是串行的,那这个效率也太低了吧)
事务的并发问题
脏读
指的是在不同的事务中,当前事务可以读到另外事务未提交的数据。比如:事务A读取了事务B更新的数据,然后B回滚操作,那么A读取到的数据是脏数据。
不可重复读
是指在一个事务内多次读取同一数据集合,在这个事务还没有结束时,另外一个事务也访问了该同一数据集合,并做了一些DML操作。因此,在第一个事务中的两次读数据之间,由于第二个事务的修改,那么第一个事务两次读到的数据可能是不一样的。
幻读
“幻读”跟“不可重复读”不是同一个问题,REPEATABLE READ不能解决“幻读”问题。“幻读”是指一个事务A中,先select查询符合条件1的数据是否存在,发现不存在再insert,结果在此时,另外一个事务B insert了一条符合条件1的数据,这就导致我在事务A中的select看到的就像幻觉一样。可以加排他锁(XLock)来解决“幻读”的问题。
(PS:扒一扒我接手的一个老系统遇到的“幻读”坑。就是某个表的邮箱字段,业务上这个邮箱字段应该是唯一的,但是数据表设计时没有加唯一约束,然后这个校验是否唯一的工作就放到代码中来做了,总之就是先查询,发现不存在就insert,然而这段代码并没有加锁。平时用着也没什么问题,因为访问量不高,但有一天不知是什么原因,同一类型的请求在几毫秒之内发了两次,然后就发生了如下情况:第一个请求进来查询发现邮箱地址不存在,于是就insert了一条包含该邮箱的数据;第二个请求以几毫秒的间隔进入该方法,查询发现该邮箱不存在,我看日志发现此时第一个请求已经insert完成了,只不过还没完成事务的提交,所以第二个请求的事务中是查询不到另外一个事务中未提交的数据(数据库隔离级别是默认的REPEATABLE READ),于是也insert了一条一模一样的数据)
丢失更新
简单来说就是一个事务的更新操作会被另一个事务的更新操作所覆盖,从而导致数据的不一致。不过,在当前数据库的任何隔离级别下,都不会导致数据库理论上的丢失更新问题。这是因为,即使是READ UNCOMMITTED的事务隔离级别,对于行的DML操作,需要对行或其他粗粒度级别的对象加锁。不论你的事务隔离级别是什么样的,只要你开启事务修改了一行数据还没有提交,你就获得了这行数据的写锁,其他事务就不能再修改这条记录。事务隔离级别只是确认其他事务能不能读取到你修改过但未提交的数据记录而已,当你修改完成提交事务,其他事物才能获得这行记录的修改权限,才能执行修改操作。
