文档内容为本人观看北京理工大学嵩天老师公开课的听课笔记与实践总结,图片为从该课程下载资料的截图,感谢嵩老师。
Key_point:网页内容提取实际上是对标签的内容进行提取,其关键是标签的获取和标签感兴趣内容的提取。获取标签用beautifulsoup/beautifulsoup.tag.标签名称的方法,例如soup.p或者soup.body.p,soup.P.b任何标签内容的获取都可以用用tag.name/attrs等直接访问python类属性的方法。
逻辑过程:标签树→标签或者标签集合→标签内容
一、BeautifulSoup库入门
1、理解
该库的作用为:定向网络的数据爬取与网页解析。BS类是对Tag类的继承。提供了html文档到python对象的映射。可以简单地理解为BS将html封装成一个标签集合,我们可以通过标签名字来访问其包含的标签对象,例如.a、.body等,若相同标签有多个则只返回第一个。如果想全部检索,可以使用后面的find_all方法。
2、Tag基本方法
可以分为两类,分别是访问自身的方法和遍历方法。
访问自身的方法包括以下四种:
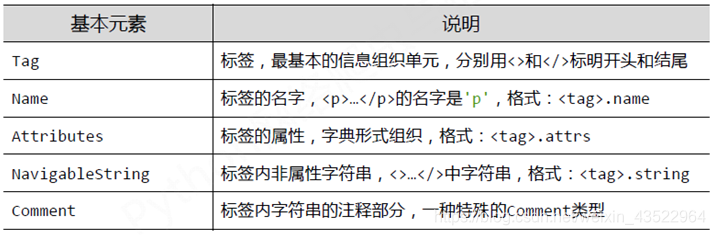
值得注意的是,本来tag.string是访问标签的字符串部分,但是实际上在有嵌套的标签中,会访问失败,返回值为空,当用于简单的标签(不含嵌套时)可以正常的使用,一种补救的方法是用.get_text()方法,但返回的是该标签内的所有文本信息,即包含被嵌套标签的string。
遍历其他标签的方法包括:下行遍历、上行遍历、平行遍历。
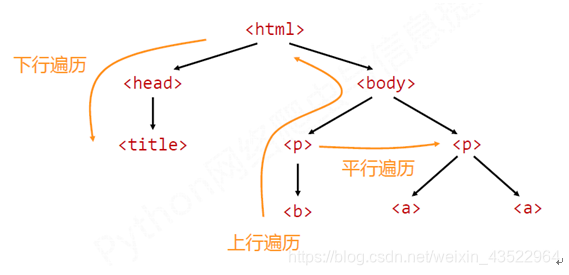
下行遍历:

.contents返回子标签列表,列表元素仍为tag类型。
.children返回迭代类型,不能直接访问,需要用for循环来遍历。
for child in soup.body.children:
print(child)
.decendants方法在jupyter测试时候报错,用pycharm正常,不知何故。(原来是单词拼错了)
// 子孙节点
for son in soup.body.descendants:
print(son)
上行遍历

.parent返回父(复合)标签,这个父标签支持遍历,内容是该标签的contents,实际上,实际上只要是标签就有.contents,就支持遍历。
.parents返回有tag和BS类构成的generator类,例如:


类型分别是:
1 <class ‘bs4.element.Tag’>
2 <class ‘bs4.element.Tag’>
3 <class ‘bs4.element.Tag’>
4 <class ‘bs4.BeautifulSoup’>
也就是说:上行遍历的终点是beautifulsoup类也就是根。
平行遍历:
首先,具有同一个父节点的标签节点才具有平行关系,如下图所示:
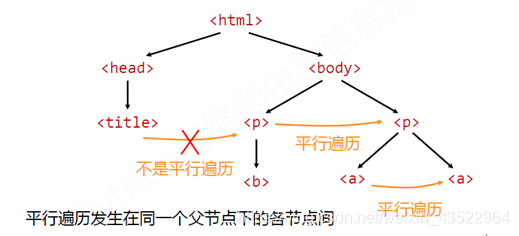
平行遍历的方法包括:

平行遍历(无论前后)即是在父节点的.contents列表里面遍历,所以有时会有换行符。
最后,bs4库的prettify()方法可以使得bs类对象更美观的显示,bs4和python3都默认utf-8编码,所以最好用3以上版本开发。
find_all方法和正则表达式结合,经常用于信息检索。find_all可以使用标签名称检索、属性值检索、导航字符串检索等。
3、Find_all方法:
Find方法是返回find_all内容列表的第一个元素。常用约束项:标签名称name,属性内容attrs,字符串内容。
例如:
for p in soup.find_all(‘p’) # soup中的所有p标签
for p in soup.find_all([‘a’, ‘p’]) # soup中所有的a标签和p标签
for tag in soup.find_all(True) # soup中的所有标签
soup.find_all(‘p’, ‘course’) # 所有属性值包含course的p标签
soup.find_all(attrs=‘course’) # 所有属性值为course的标签
for tag in soup.find_all(attrs=re.compile(‘py’)): # 属性中包含py
soup.find_all(‘p’, string=re.compile(‘python’)) # 字符串区域包含python的所有p标签
注意:soup.find_all 和 正则库的findall区别很大,后者是在目标字符串中严格按照pattern去匹配,而soup的方法如果加入正则对象,例如上面第六句,name返回的是所有包含正则吻合的标签集合,举例来说:
soup.find_all(attrs=re.compile('py')): # 属性中包含py
只要属性字典中的 class 对应的值包含‘py’而不要求严格为‘py’,name都会作为结果之一返回。
输出结果:
<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a>
{'href': 'http://www.icourse163.org/course/BIT-268001', 'class': ['py1'], 'id': 'link1'}
<a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>
{'href': 'http://www.icourse163.org/course/BIT-1001870001', 'class': ['py2'], 'id': 'link2'}
关于find_all方法的attrs这个参数有必要提一下:一般而言一个标签的属性字典包括很多的键值对,例如:
{'href': 'http://www.icourse163.org/course/BIT-268001', 'class': ['py1'], 'id': 'link1'}
阅读源码可知:如果我们的attrs参数不是以字典的形式传入,那么默认该键为class,如果想用除去class的键作为约束,那么attrs必须用字典传入。例如:
for tag in soup.find_all(attrs=re.compile('org')):
print(tag)
print(tag.attrs)
for tag in soup.find_all(attrs={"href":re.compile('org')}):
print(tag)
print(tag.attrs)
输出结果:
上面代码的输出:[]
下面代码的输出:
<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a>
{'href': 'http://www.icourse163.org/course/BIT-268001', 'class': ['py1'], 'id': 'link1'}
<a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>
{'href': 'http://www.icourse163.org/course/BIT-1001870001', 'class': ['py2'], 'id': 'link2'}
代码链接:BeautifulSoup练习
