CUDA时间评估
LZ之前都是使用CPU timer来评估CUDA代码的性能的,但是这样做时候没有办法给出精确答案的,除了其他因素外,最常见的时间计算误差包括线程延迟开销和操作系统调度的开销。同时,使用GPU测量的时间还取决于高精度Cpu计时器的可用性。在很多情况下,主机在GPU内核运行时执行异步计算,因此,因此为了测量GPU内核消耗的时间,CUDA提供了对应于event的API。
CUDA event是在CUDA程序中指定位置记录GPU的时间戳,在这个API中,GPU记录了对应的时间戳,消除了上面提到的两个问题。
使用CUDA event有两个测量时间的步骤:创建事件和记录事件,最后计算中间的时间,得到最后代码的整体性能。
具体的代码块如下所示
#include <cuda_runtime_api.h>
#include <stdio.h>
int main(){
// 一些数据准备
...
...
// 实例化CUDA event
cudaEvent_t e_start, e_stop;
//创建事件
cudaEventCreate(&e_start);
cudaEventCreate(&e_stop);
//记录事件,开始计算时间
cudaEventRecord(e_start, 0);
...
//一顿操作猛如虎
...
//记录结束时事件
cudaEventRecord(e_stop, 0);// 0 代表CUDA流0
//等待事件同步后
cudaEventSynchronize(e_stop);
//计算对应的时间,评估代码性能
float elapsedTime;
cudaEventElapsedTime(&elapsedTime, e_start, e_stop);
}
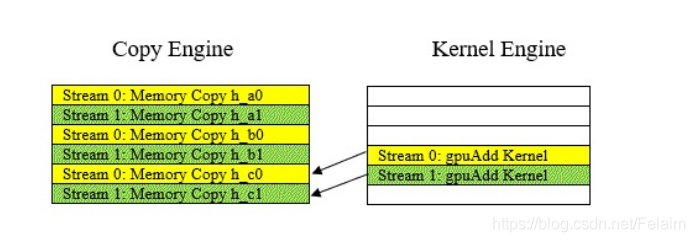
CUDA stream(CUDA 流)的一些理解
使用多个block或者thread,只是把一个任务进行并行化操作,但是并没有体现任务的并行性。任务的并行性是指可以运行多个核函数,最常见的如图像处理可以一个流做图像上下翻转,一个流做随机crop,还可以一个流做resize但是这个并不是那么灵活。
CUDA流其实是在GPU执行中GPU操作队列具体顺序。这些功能包括内核功能,内存复制操作和CUDA事件操作,而这些操作添加队列的顺序其实就是对应操作执行的顺序。每个CUDA流可以看做一个单独的任务,所以我们可以使用多个流来开启多个任务。
#include <cuda_runtime_api.h>
#include <iostream>
#include <stdio.h>
#define RANDOM(x) (rand() % x)
#define MAX 10
#define M 128 // number of thread
#define N 50000 // Define number of elements in Array
//Define kernel function for vector addition
__global__ void gpuAdd(int *d_a, int *d_b, int *d_c){
// getting block index of current kernel
int tid = threadIdx.x + blockIdx.x *blockDim.x;
while(tid<N){
d_c[tid] = d_a[tid]+d_b[tid];
tid += blockDim.x * gridDim.x;
}
}
int main(){
// define host arrays
int *h_a, *h_b, *h_c;
// define device pointers for stream0
int *d_a0, *d_b0, *d_c0;
// define device pointers for stream1
int *d_a1, *d_b1, *d_c1;
cudaStream_t stream0, stream1;
cudaStreamCreate(&stream0);
cudaStreamCreate(&stream1);
cudaEvent_t e_start, e_stop;
cudaEventCreate(&e_start);
cudaEventCreate(&e_stop);
cudaEventRecord(e_start, 0);
// Allocate memory for host pointers
cudaHostAlloc((void **)&h_a, 2*N*sizeof(int), cudaHostAllocDefault);
cudaHostAlloc((void **)&h_b, 2*N*sizeof(int), cudaHostAllocDefault);
cudaHostAlloc((void **)&h_c, 2*N*sizeof(int), cudaHostAllocDefault);
// Allocate memory for device pointers
cudaMalloc((void **)&d_a0, N*sizeof(int));
cudaMalloc((void **)&d_b0, N*sizeof(int));
cudaMalloc((void **)&d_c0, N*sizeof(int));
cudaMalloc((void **)&d_a1, N*sizeof(int));
cudaMalloc((void **)&d_b1, N*sizeof(int));
cudaMalloc((void **)&d_c1, N*sizeof(int));
for(int i= 0; i<N*2; ++i){
h_a[i] = 2*i*i;
h_b[i] = i;
}
cudaMemcpyAsync(d_a0, h_a, N*sizeof(int), cudaMemcpyHostToDevice, stream0);
cudaMemcpyAsync(d_a1, h_a+N, N*sizeof(int), cudaMemcpyHostToDevice, stream1);
cudaMemcpyAsync(d_b0, h_b, N*sizeof(int), cudaMemcpyHostToDevice, stream0);
cudaMemcpyAsync(d_b1, h_b+N, N*sizeof(int), cudaMemcpyHostToDevice, stream1);
// Kernel call
gpuAdd <<<512, 512, 0, stream0>>>(d_a0, d_b0, d_c0);
gpuAdd <<<512, 512, 0, stream1>>>(d_a1, d_b1, d_c1);
// Copy result back to host memory from device memory
cudaMemcpyAsync(h_c, d_c0, N*sizeof(int), cudaMemcpyDeviceToHost, stream0);
cudaMemcpyAsync(h_c+N, d_c1, N*sizeof(int), cudaMemcpyDeviceToHost, stream1);
cudaDeviceSynchronize();
cudaStreamSynchronize(stream0);
cudaStreamSynchronize(stream1);
cudaEventRecord(e_stop, 0);
cudaEventSynchronize(e_stop);
float elapsedTime;
cudaEventElapsedTime(&elapsedTime, e_start, e_stop);
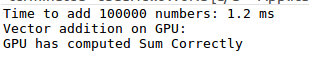
printf("Time to add %d numbers: %3.1f ms\n", 2*N, elapsedTime);
int Correct = 1;
printf("Vector addition on GPU: \n");
// print result on console
for(int i = 0; i<2*N;i++){
if(h_a[i]+h_b[i] != h_c[i]){
Correct = 0;
}
}
if(Correct == 1){
printf("GPU has computed Sum Correctly\n");
}
else{
printf("There is an Error in GPU computation\n");
}
// free up memory
cudaFree(d_a0);
cudaFree(d_b0);
cudaFree(d_c0);
cudaFree(d_a1);
cudaFree(d_b1);
cudaFree(d_c1);
cudaFreeHost(h_a);
cudaFreeHost(h_b);
cudaFreeHost(h_c);
return 0;
}
附一张运行示意图:
最后运行结果如图所示:
参考书籍:
- Hands-On GPU-Accelerated Computer Vision with OpenCV and CUDA
PS:
每天起床第一件事,就是看下疫情有没有缓解,有些时候也只能干着急,帮不上什么忙,只能默默宅在家里,不出门添乱了,按照目前态势周六可能就破三万了,心里慌慌的,公司也是准备10号开始远程办公,怕人员太多,不便于管理的角度考虑,这个做法还是值得赞赏的。
但是觉得这个疫情情况界面可以再做好一些,对每个区域的新增人数最好也有直观的表示,而且是不是确诊病例绝大多数都是从疑似病例中确诊出来的,那么新增的疑似病例如果分析一下可能昨天一天就增加了8000多例!
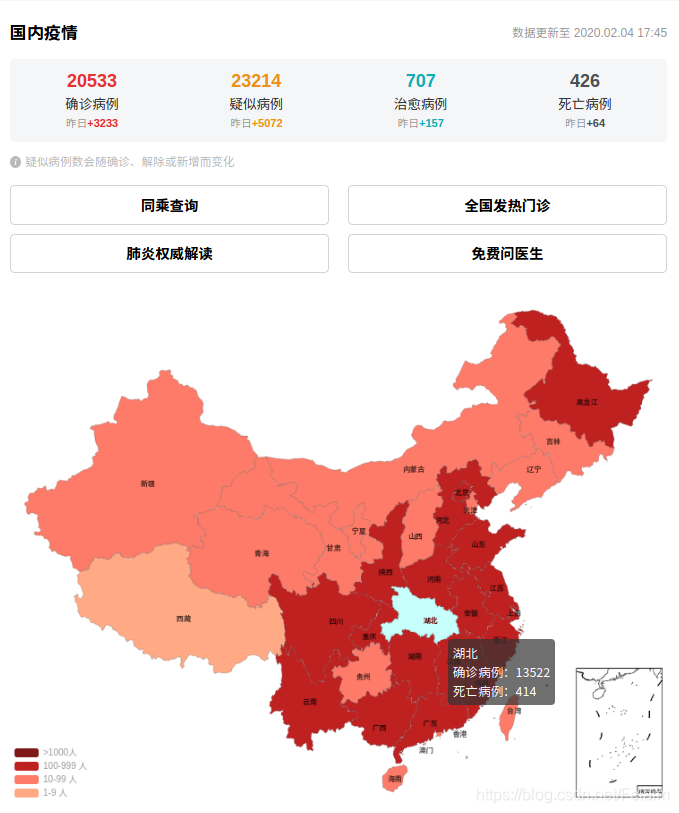
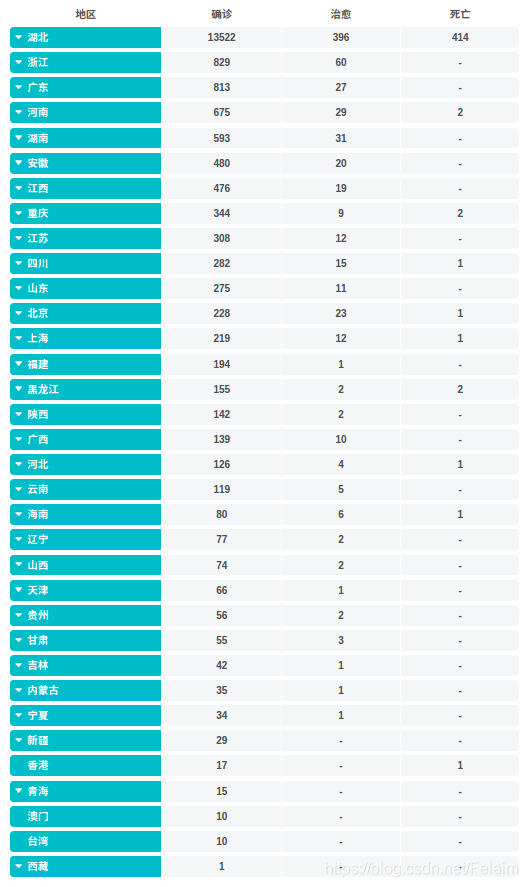
武汉加油!湖北加油!中国加油!劲头上来了,能行!
