文章目录
VS2017 CUDA编程学习1:CUDA编程两变量加法运算
VS2017 CUDA编程学习2:在GPU上执行线程
VS2017 CUDA编程学习3:CUDA获取设备上属性信息
VS2017 CUDA编程学习4:CUDA并行处理初探 - 向量加法实现
VS2017 CUDA编程学习5:CUDA并行执行-线程
VS2017 CUDA编程学习6: GPU存储器架构
VS2017 CUDA编程学习7:线程同步-共享内存
VS2017 CUDA编程学习8:线程同步-原子操作
VS2017 CUDA编程学习9:常量内存
VS2017 CUDA编程学习10:纹理内存
VS2017 CUDA编程学习实例1:CUDA实现向量点乘
VS2017 CUDA编程学习11:CUDA性能测量
前言
今天跟大家分享CUDA编程中一个重要概念:CUDA流。
1. CUDA流的理解
之前介绍的GPU内核函数,通过多线程实现加速,可以理解为数据并行。而CUDA流可以理解为任务并行,即多个相互独立的内核函数同时执行。
CUDA流是GPU上的工作队列,队列中的工作将以特定的顺序执行。队列中的工作主要包括:内核函数的调用, cudaMemcpy系列的数据传输,以及CUDA事件的操作。CUDA流中工作的顺序以添加的顺序来执行,先加入的先执行,即每个CUDA流中的工作是串行执行的。
2. C++ 实现CUDA流
这里以GPU上加法操作为例实现CUDA流。
例子中主要调用一下API:
cudaHostAlloc/cudaFreeHost(): 使用页面锁定内存为CPU设备变量分配内存,页面锁定内存,简单理解就是内存数据永远存储在内存上,不会转储到硬盘空间来暂存,缺点是如果内存一直不释放,将造成内存高使用率,可能影响其他程序的运行;
cudaMemcpyAsync:用于异步传输数据,和cudaMemcpy函数相比,多了最后一个参数 - 指定一个特定的CUDA流,从而在这个特定的CUDA流中进行存储器传输操作。这里注意,异步操作是指当该函数返回时,实际的存储器传输操作可能尚未完成,甚至尚未开始。
这里要注意,每个CUDA流中的工作是串行的,而流和流之间则默认不保证顺序。每个流程都有传输和计算工作,这样不同的流间计算和传输工作可以并行执行,起到加速的作用,进而提升程序性能。
cudaStreamSynchronize(): 确保CUDA流中所有操作都结束后才返回控制权给主机(CPU)。
详细代码如下所示:
#include <stdio.h>
#include <iostream>
#include <cuda.h>
#include <cuda_runtime.h>
#include <cuda_runtime_api.h>
#include <device_launch_parameters.h>
#define N 50000
__global__ void gpuAdd(int* d_a, int* d_b, int* d_c)
{
int tid = threadIdx.x + blockIdx.x * blockDim.x;
while (tid < N)
{
d_c[tid] = d_a[tid] + d_b[tid];
tid += blockDim.x * gridDim.x;
}
}
int main()
{
//定义CPU变量
int* h_a, *h_b, *h_c;
//为CUDA流 stream0定义GPU变量
int* d_a0, *d_b0, *d_c0;
//为CUDA流 stream1定义GPU变量
int *d_a1, *d_b1, *d_c1;
//定义CUDA流变量
cudaStream_t stream0, stream1;
//创建CUDA流
cudaStreamCreate(&stream0);
cudaStreamCreate(&stream1);
//定义CUDA事件
cudaEvent_t e_start, e_stop;
//创建CUDA事件
cudaEventCreate(&e_start);
cudaEventCreate(&e_stop);
//开始记录CUDA事件
cudaEventRecord(e_start, 0);
//分配CPU内存,使用页面锁定内存, 不会发生换页操作(将暂时不用的数据从内存中转存硬盘上),数据永远存在内存中
cudaHostAlloc(&h_a, 2 * N * sizeof(int), cudaHostAllocDefault);
cudaHostAlloc(&h_b, 2 * N * sizeof(int), cudaHostAllocDefault);
cudaHostAlloc(&h_c, 2 * N * sizeof(int), cudaHostAllocDefault);
//分配GPU内存
cudaMalloc(&d_a0, N * sizeof(int));
cudaMalloc(&d_b0, N * sizeof(int));
cudaMalloc(&d_c0, N * sizeof(int));
cudaMalloc(&d_a1, N * sizeof(int));
cudaMalloc(&d_b1, N * sizeof(int));
cudaMalloc(&d_c1, N * sizeof(int));
//初始化CPU数据
for (int i = 0; i < 2 * N; i++)
{
h_a[i] = 2 * i * i;
h_b[i] = i;
}
//为两个CUDA流执行异步内存拷贝操作
cudaMemcpyAsync(d_a0, h_a, N * sizeof(int), cudaMemcpyHostToDevice,
stream0);
cudaMemcpyAsync(d_a1, h_a + N, N * sizeof(int), cudaMemcpyHostToDevice,
stream1);
cudaMemcpyAsync(d_b0, h_b, N * sizeof(int), cudaMemcpyHostToDevice,
stream0);
cudaMemcpyAsync(d_b1, h_b + N, N * sizeof(int), cudaMemcpyHostToDevice,
stream1);
//为两个CUDA流分别调用内核函数
gpuAdd << <512, 512, 0, stream0 >> > (d_a0, d_b0, d_c0);
gpuAdd << <512, 512, 0, stream1 >> > (d_a1, d_b1, d_c1);
//从GPU拷贝数据到CPU
cudaMemcpyAsync(h_c, d_c0, N * sizeof(int), cudaMemcpyDeviceToHost,
stream0);
cudaMemcpyAsync(h_c + N, d_c1, N * sizeof(int), cudaMemcpyDeviceToHost,
stream1);
//等待GPU所有线程运行结束
cudaDeviceSynchronize();
//等待所有CUDA流中工作完成
cudaStreamSynchronize(stream0);
cudaStreamSynchronize(stream1);
//结束CUDA事件记录
cudaEventRecord(e_stop, 0);
//等待CUDA事件记录完成
cudaEventSynchronize(e_stop);
//GPU上运行时间统计
float elapsedTime;
cudaEventElapsedTime(&elapsedTime, e_start, e_stop);
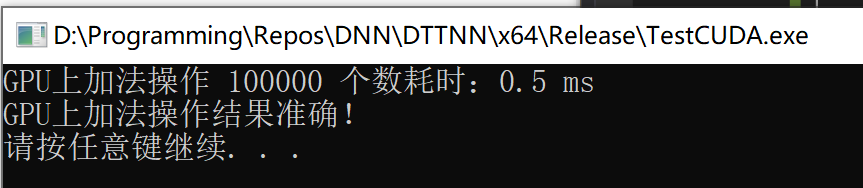
printf("GPU上加法操作 %d 个数耗时:%3.1f ms\n", 2 * N, elapsedTime);
//验证GPU上运行结果的准确性
int correct = 1;
for (int i = 0; i < 2 * N; i++)
{
if (h_a[i] + h_b[i] != h_c[i])
{
correct = 0;
break;
}
}
if (correct == 1)
{
printf("GPU上加法操作结果准确!\n");
}
else
{
printf("GPU上加法操作结果不准确!\n");
}
//释放GPU内存
cudaFree(d_a0);
cudaFree(d_a1);
cudaFree(d_b0);
cudaFree(d_b1);
cudaFree(d_c0);
cudaFree(d_c1);
//释放CPU页面锁定内存
cudaFreeHost(h_a);
cudaFreeHost(h_b);
cudaFreeHost(h_c);
system("pause");
return 0;
}
3. 执行结果
总结
CUDA流,说白了就是实现了多任务并行的功能。今天就分享到这里,本人还是小菜鸟,如果上面描述有问题,还请大神不吝指正!
学习资料
《基于GPU加速的计算机视觉编程》