介绍标准I/O前,先介绍文件I/O,以便与区别比较。
带缓冲和不带缓冲I/O的区别:
所谓不带缓冲,并不是指内核不提供缓冲,而是只单纯的系统调用,不是函数库的调用。系统内核对磁盘的读写都会提供一个块缓冲(内核缓冲区)(在有些地方也被称为内核高速缓存),当用write函数对其写数据时,直接调用系统调用,将数据写入到块缓冲进行排队,当块缓冲达到一定的量时,才会把数据写入磁盘。因此所谓的不带缓冲的I/O是指进程不提供缓冲功能(但内核还是提供缓冲的)。每调用一次write或read函数,直接系统调用。
带缓冲的I/O是指进程对输入输出流进行了改进,提供了一个流缓冲,当用fwrite函数往磁盘写数据时,先把数据写入流缓冲区中,当达到一定条件,比如流缓冲区满了,或刷新流缓冲,这时候才会把数据一次送往内核提供的块缓冲,再经块缓冲写入磁盘。(双重缓冲)
因此,带缓冲的I/O在往磁盘写入相同的数据量时,会比不带缓冲的I/O调用系统调用的次数要少。
带缓存IO其实就是在用户层再建立一个缓存区,这个缓存区的分配和优化长度等细节都是标准IO库代你处理好了
总结:
无缓存IO操作数据流向路径:数据——内核缓存区——磁盘
标准IO操作数据流向路径:数据——流缓存区——内核缓存区——磁盘
不带缓存的I/O对文件描述符操作,下面带缓存的I/O是针对流的
关于带缓冲与不带缓冲详解博客:
文件I/O
UNIX系统中的大多数文件I/O只需用到5个函数:open,read,write,lseek以及close。
这些I/O函数经常被称为不带缓冲的I/O,不带缓冲是指每个read和write函数都调用内核中的一个系统调用。
文件描述符:
所有打开的文件都通过文件描述符引用,文件描述符是一个非负整数。打开或创建一个文件时,内核向进程返回一个文件描述符。读写文件时通过文件描述符标识文件,将其作为参数传递给read或write。
文件描述符的变化范围是0~OPEN_MAX-1
标准输入:STDIN_FILENO
标准输出:STDOUT_FILENO
标准错误:STDERR_FILENO
函数open和openat
调用open或openat函数可以打开或创建一个文件
int open(const char *path, int oflag,..) int openat(ind fd, const char *path, int oflag,...) //自行搜索掌握
path参数是要打开或创建文件的名字,oflag参数是此函数的多个选项,通常是一个或多个常量。
列出一些常用的oflag参数:
O_RDONLY:只读打开
O_WRONLY:只写打开
O_RDWR:读写打开
O_EXEC:只执行打开
O_CREAT:若此文件不存在则创建它
函数creat
调用creat函数创建一个新文件
int creat(const char *path,mode_t mode); //返回只写打开的文件描述符
此函数等效于:
open(path,O_WRONLY | O_CREAT | O_TRUNC,mode);
函数close
调用close函数关闭一个打开文件
int close(int fd);
当一个进程终止时,内核自动关闭它所有的打开文件。
函数lseek
每个打开文件都有一个与其关联的"当前文件偏移量"--offset。通常是个非负整数,用以度量从文件开始处计算的字节数。读写操作都从当前文件偏移量处开始,并使偏移量增加所读写的字节数。
off_t lseek(int fd, off_t offset, int whence); //返回新的文件偏移量
参数offset和参数whence:
-当whence是SEEK_SET,则将该文件的偏移量设置为距文件开始处offset个字节。
-当whence是SEEK_CUR,则将该文件的偏移量设置为其当前值加offset,offset可为正为负。
-当whence是SEEK_END,则将该文件的偏移量设置为文件长度加offset,offset可为正为负。
函数read
调用read函数从打开文件中读数据
ssize_t read(int fd, void *buf, size_t nbytes); //返回读到的字节数。若到文件尾,返回0
从fd指向的文件中读取nbytes到buf中。
-读普通文件时,若读到要求字节数之前到了文件尾端,则read返回读到的字节数,下次再调用时,返回0。
-当从终端设备读时,通常一次最多读一行。
-当从网络中读时,网络中的缓冲机制可能造成返回值小于所要求读的字节数。
函数write
调用write函数向打开文件写数据
ssize_t write(int fd, const void *buf, size_t nbytes); //返回已写的字节数
将buf中的数据写入fd指向的文件。
I/O的效率
/* 只使用read和write函数复制一个文件 */
#include<stdio.h>
#include<apue.h>
#include<myerr.h>
#include<fcntl.h>
#define BUFSIZE 4096
int main(void)
{
int n;
char buf[BUFSIZE];
while((n = read(STDOUT_FILENO,buf,BUFSIZE)) > 0)
if(write(STDOUT_FILENO,buf,n) != n)
err_sys("write error");
if(n<0)
err_sys("read error");
exit(0);
}
如何选取BUFSIZE的值呢?通常拥有较大的缓冲区长度耗费时间越少。
标准I/O库
流和FILE对象
上面文件I/O函数都是围绕文件描述符的,当打开一个文件时,即返回一个文件描述符。
而对于标准I/O库,操作是围绕流(stream)进行的,用标准I/O库打开或创建一个文件时,一个流就与一个文件相关联
标准I/O库就是带缓存的I/O,它由ANSI C标准说明。当然,标准I/O最终都会调用上面的I/O例程。标准I/O库代替用户处理很多细节,比如缓存分配、以优化长度执行I/O等。
标准I/O提供缓存的目的就是减少调用read和write的次数,它对每个I/O流自动进行缓存管理(标准I/O函数通常调用malloc来分配缓存)。
流的定向决定了所读写的字符是单字节还是多字节的。一个流被创建时,并没有定向。若在未定向的流上使用一个多字节I/O函数,则流的定向设置为宽定向的;若在未定向的流上使用单字节I/O函数,则流的定向设为字节定向的。
两个函数改变流的定向:freopen函数清除一个流的定向;fwide函数用于设置流的定向
#include<wchar.h> int fwide(FILE* fp, int mode); //若流是宽定向,返回正值;流是字节定向,返回负值;流是未定向的,返回0
fwide函数不改变已定向流的定向,若指定流已定向,则返回相应值。
根据mode参数设置:
-若mode参数值为负,fwide将使指定的流是字节定向的
-若mode参数值为正,fwide将使指定的流是宽定向的
-若mode参数值为0,fwide不设置流定向
标准I/O流预定义文件指针:
标准输入:stdin
标准输出:stdout
标准错误:stderr
缓冲
标准I/O也被称为带缓冲的I/O,提供缓冲的目的是尽可能减少使用read和write调用的次数。
一般而言,由系统选择缓存的长度,并自动分配。标准I/O库在关闭流的时候自动释放缓存。
标准I/O提供了以下3种类型的缓冲:
--全缓冲:在填满标准I/O缓冲区后才进行实际I/O操作。在一个流上执行第一次I/O操作时,标准I/O函数通常调用malloc获得需使用的缓冲区。
--行缓冲:当在输入和输出中遇到换行符时,标准I/O库执行I/O操作。当流涉及一个终端时(标准输入和标准输出),通常使用行缓冲。因为I/O库用来收集每一行缓冲区的长度是固定的,所以只要填满了缓冲区,即时还没有换行符,也进行I/O操作。
--不带缓冲。标准I/O库不对字符进行缓冲存储,例如标准I/O函数fputs写15个字符到不带缓冲的流的,期望15个字符能立即输出,就很可能使用write函数将这些字符写到相关联的打开文件中。标准错误流stderr通常是不带缓冲的,这使得出错消息可以尽快显示出来。
系统默认使用下列类型的缓冲:
--标准错误不带缓冲
--若是指向终端设备的流,则是行缓冲的;否则是全缓冲的。
打开流
下列3个函数打开一个标准I/O流:
FILE *fopen(const char *restrict pathname, const char *restrict type); FILE *freopen(const char *restrict pathname, const char *restrict type, FILE *restrict fp); FILE *fdopen(int fd, const char *type); //若成功,返回文件指针
3个函数区别如下:
--fopen函数打开路径名为pathname的一个指定的文件
--freopen函数在一个指定的流上打开一个指定的文件,若该流已经打开,则先关闭该流。若该流已经定向,则使用freopen清除该定向
--fdopen函数获取一个已有的文件描述符,并使一个标准的I/O流与该描述符相结合。此函数常用于由创建管道和网络通信通道函数返回的描述符。
type参数指定对该I/O流的读写方式:

关闭流
调用fclose函数关闭一个打开的流
int fclose(FILE *fp);
在该文件被关闭前,冲洗缓冲中的输出数据。
读和写流
一旦打开了流,则可在3种不同类型的非格式化I/O种进行选择,对其进行读写操作:
--每次一个字符的I/O,一次读或写一个字符,若流是带缓冲的,则标准I/O函数处理所有缓冲
--每次一行的I/O,fgets和fputs。
--直接I/O,fread和fwrite函数支持这种类型的I/O,每次I/O操作读或写某种数量的对象,每个对象具有指定的长度。这两个函数通常用于从二进制文件中每次读或写一个结构。
每次一个字符I/O
输入函数
一次读一个字符:
int getc(FILE *fp); int fgetc(FILE *fp); int getchar(void);
getchat等同于getc(stdin);
getc和fgetc的区别是getc可被实现为宏,而fgetc不能。
输出函数
对应于上述输入函数:
int putc(int c, FILE *fp); int fputc(int c, FILE *fp); int putchar(int c);
每次一行I/O
输入函数
每次输入一行:
char *fgets(char *restrict buf, int n, FILE *restrict fp); char *gets(char *buf); //若成功,返回buf
读入的行将送入缓冲区,fgets从指定的流读,gets从标准输入读。
gets不推荐用,因为不能指定缓冲区的长度,可能造成缓冲区溢出(即读入的行大于缓冲区长度)
输出函数
每次输出一行:
int *fputs(const char *restrict str, FILE *restrict fp); int puts(const char *str);
fputs将一个以null字符终止的字符串写到指定的流。注意:这并不一定是每次输出一行。
puts.................................................写到标准输出。
标准I/O的效率
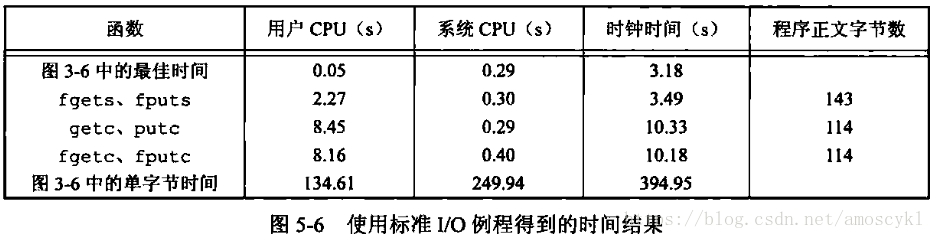
使用标准I/O的一个优点是无需考虑缓冲及最佳I/O长度的选择,在使用fgets时需要考虑最大行长,但是与选择最佳I/O长度来说,这要方便得多。
使用每次一行I/O版本的速度大约是每次一个字符版本速度的两倍。
二进制I/O
前面介绍了以一次一个字符或一次一行的方式进行操作。如果进行二进制I/O操作,那么我们更愿意一次读或写一个完整的结构。
size_t fread(void *restrict ptr, size_t size, size_t nobj, FILE *restrict fp);
size_t fwrite(const void *restrict ptr, size_t size, size_t nobj, FILE *restrict fp);
//返回读或写的对象数
两种常见的用法:
1.读或写一个二进制数组。例如:为了将一个浮点数组的第2~5个元素写到一个文件上
float data[10];
if (fwrite(&data[2], sizeof(float), 4, fp) != 4)
err_sys("fwrite error");
其中,指定size为每个数组元素的长度,nobj为欲写的元素个数
2.读或写一个结构。例如:
struct {
short count;
long total;
char name[NAMESIZE];
}item;
if (fwrite(&item,sizeof(item),1,fp) != 1)
err_sys("fwrite error");
其中,指定size为结构的长度,nobj为1 (要写的对象个数)
格式化I/O
格式化输出
格式化输出是由5个printf函数来处理的:
int printf(const char *restrict format...); int fprintf(FILE *restrict fp, const *restrict format,...); int dprintf(int fd, const char *restrict format,...); //3个返回值:若成功,返回输出字符数 int sprintf(char *restrict buf, const char *restrict format,...); //若成功,返回存入数组的字符数 int snprintf(char *restrict buf, size_t n, const char *restrict format,...);
printf将格式化数据写到标准输出,fprintf写至指定的流,dprintf写至指定的文件描述符,sprintf将格式化的字符送入数组buf中。
格式化输入
格式化输入处理的是3个scanf函数
int scanf(const char *restrict format...); int fscanf(FILE *restrict fp, const char *restrict format...); int sscanf(const char *restrict buf, const char *restrict format...);
每个标准I/O流都有一个与其相关联的文件描述符,可以对一个流调用fileno函数以获得其描述符。
int fileno(FILE *fp); //返回与该流相关联的文件描述符